Code Representation Learning At Scale
Blog này là phiên bản tiếng việt được tôi dịch từ bài báo gốc.
Abstract
- Các nghiên cứu gần đây đã chỉ ra rằng các mô hình ngôn ngữ code trên quy mô lớn chứng minh hiệu suất tăng đáng kể đối với các downstream task, ví dụ như là sinh code. Tuy nhiên, hầu hết các công trình hiện liên quan đến biểu diễn mã ở quy mô hàng trăm triệu tham số sử dụng tập dữ liệu tiền huấn luyện rất hạn chế. Trong báo báo này, chúng tôi nâng cấp việc học biểu diễn mã bằng một lượng lớn dữ liệu mã thông qua gồm hai giai đoạn. Giai đoạn một, chúng tôi huấn luyện các bộ mã thông qua sự kết hợp tận dụng của randomness in masking language modeling (RiMLM) và khía cạnh cấu trúc của ngôn ngữ lập trình. Sau đó, chung tôi nâng cao các biểu diễn thông qua contrastive learning (học tương phản) với hard negative và hard positive được xây dựng theo học không giám sát. Chúng tôi xây dựng một mô hình bộ mã hóa có sẵn hoạt động tốt hơn các mô hình hiện có trong nhiều downstream task với large margins. Để hiểu rõ các yếu tố góp phần vào sự thành công trong việc biểu diễn mã, chúng tôi sẽ loại bỏ các chi tiết và chia sẻ sự phát hiện của chúng tôi về (i) sơ đồ khử nhiễu mức mã thông báo tùy chỉnh và hiệu quả cho mã nguồn; (ii) tầm quan trọng của hard negative và hard positive; (iii) bimodal contrastive learning trong việc thúc đẩy hiệu suất tìm kiếm ngữ nghĩa đa ngôn ngữ; (iv) cách các pretraining quyết định các hiệu suất của downstream task theo kích thước mô hình.
1. Giới thiệu
- Large language models (LLMs) được huấn luyện trước trên một lượng lớn mã nguồn đã thay đổi đáng kể lĩnh vực tạo mã. Ví dụ, việc phát hành gần đây một tập dữ liệu 6TB bao gồm mã nguồn có giấy phép cho phép đã đóng vai trò then chốt trong việc thúc đẩy sự phát triển của các mô hình ngôn ngữ mã trong thời điểm hiện tại. Tuy nhiên, những tập dữ liệu lớn này chưa được tận dụng hết để phát triển các Programming Language (PL) embedding models nhiều mục đích. Đến nay, hầu hết các mô hình PL có không quá 125 triệu tham số và chủ yếu được huấn luyện trên một vài triệu ví dụ huấn luyện, ví dụ như CodeSearchNet.
Mặc dù không thể phủ nhận tầm quan trọng của dữ liệu quy mô lớn, nhưng cần phải thừa nhận vai trò quan trọng của các mục tiêu huấn luyện trước. Cách tiếp cận phổ biến hiện nay để huấn luyện trước một bộ mã hóa Transformer hai chiều nhằm học các biểu diễn là thông qua việc tối ưu hóa mục tiêu Mask Language Model (MLM), như được đề xuất bởi Devlin và cộng sự (2019b). Quy trình masking trong mục tiêu MLM tiêu chuẩn tuân theo quy tắc 80-10-10. Tuy nhiên, chúng tôi nhận thấy rằng quy trình che như vậy dẫn đến sự phát triển của các mô hình nhúng mã không tối ưu. Vì các đoạn mã chứa cả các câu lệnh natural language (NL) (tức là docstring, comment) và mã thuần túy, việc thay thế các token bị che bằng một token ngẫu nhiên theo quy tắc 80-10-10 có thể dẫn đến việc thay thế một token NL bằng một token PL, và ngược lại (xem thống kê ở Phụ lục A.3). Chúng tôi suy đoán rằng sự đồng xuất hiện của PL và NL cùng với bản chất cú pháp của mã nguồn làm cho nó dễ bị phá vỡ cả ngữ nghĩa và cấu trúc của mã bị che, dẫn đến việc học ngôn ngữ mô hình không tối ưu.
- Trong khi MLM đã được huấn luyện mang lại các biểu diễn ngữ cảnh của token, hầu hết các downstream sau này chủ yếu hoạt động ở mức độ chuỗi. Khi mục tiêu là tăng cường khả năng phân biệt biểu diễn để ứng dụng ngay lập tức trong các nhiệm vụ ở mức độ chuỗi, Contrastive Learning (CL) trở thành phương pháp được lựa chọn. Các công trình hiện tại đã sử dụng CL đơn (sử dụng các cặp Code-Code) (Guo et al., 2022; Jain et al., 2021) hoặc CL đôi (sử dụng các cặp Text-Code) (Li et al., 2022) cho việc học biểu diễn. Trong CL đơn, một lựa chọn phổ biến là sử dụng bổ sung dropout (Gao et al., 2021) để xây dựng các cặp mã tích cực. Tuy nhiên, chúng tôi nhận thấy rằng bổ sung dropout gặp khó khăn trong việc hỗ trợ quá trình huấn luyện dài, điều này cũng được báo cáo bởi Zhou et al. (2022). Ngược lại, CL đôi trở thành một lựa chọn hấp dẫn, chủ yếu là do sự sẵn có của các cặp tự nhiên. Các nghiên cứu trước đây sử dụng các hàm và docstring tương ứng của chúng để thiết lập các cặp huấn luyện đa mô. Tuy nhiên, các thí nghiệm sơ bộ của chúng tôi chỉ ra rằng sự trùng lặp đáng kể giữa docstring và chữ ký hàm làm đơn giản hóa quá trình học đối lập (xem thống kê ở Phụ lục A.6).
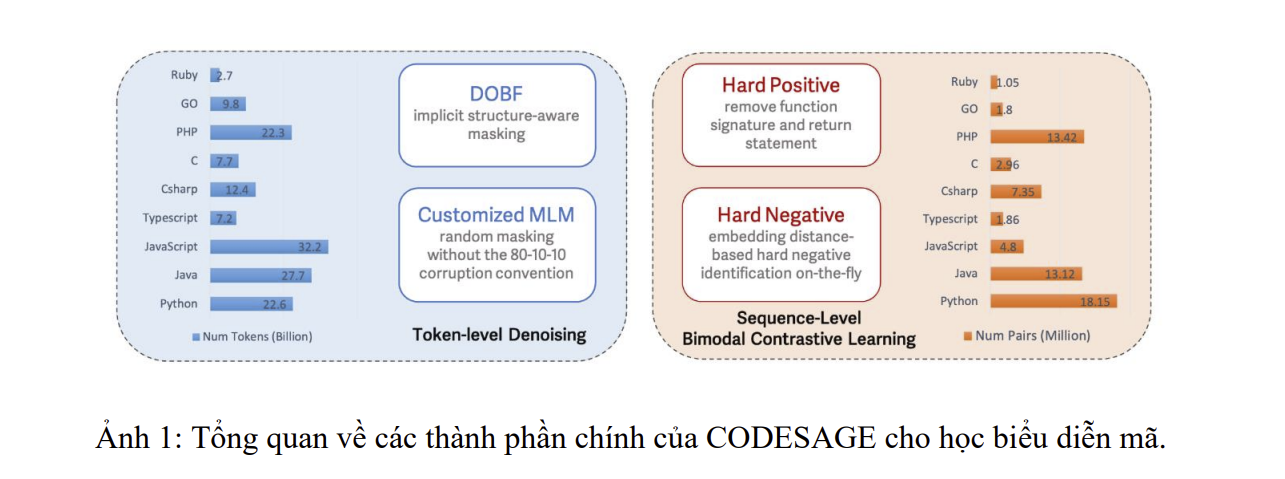
Để đạt được mục tiêu này, chúng tôi giới thiệu CODESAGE, một mô hình biểu diễn mã hóa hai chiều cho mã nguồn. Chúng tôi huấn luyện trước CODESAGE bằng cách sử dụng một lược đồ huấn luyện hai giai đoạn với một lượng lớn dữ liệu huấn luyện được tùy chỉnh (Kocetkov et al., 2022). Chúng tôi mô tả các thành phần chính của CODESAGE trong Hình 1. Đầu tiên, chúng tôi huấn luyện các bộ mã hóa hai chiều thông qua sự kết hợp của hai mục tiêu bổ sung cho nhau: Identifier Deobfuscation (DOBF) và MLM mà không theo quy tắc 80-10-10. Tương tự như một lập trình viên con người, việc tìm các tên có ý nghĩa cho các định danh bị làm xáo trộn yêu cầu mô hình phải có sự hiểu biết sâu sắc về ngữ nghĩa và cấu trúc của mã. Đồng thời, như một mục tiêu chung hơn, MLM bao phủ các khía cạnh khác ngoài các định danh của mã – điều này quan trọng để làm phong phú các tín hiệu huấn luyện, đặc biệt đối với các ví dụ dữ liệu có tên định danh không mang tính thông tin. Trong giai đoạn thứ hai, chúng tôi tận dụng các cặp (văn bản, mã) bằng bimodal contrastive learning (CL). Khác với các phương pháp hiện có chủ yếu dựa vào các cặp văn bản và mã tự nhiên, chúng tôi đề xuất một chiến lược để giảm khả năng mô hình học các lối tắt. Phương pháp của chúng tôi bao gồm chỉ sử dụng phần thân hàm trong khi bỏ qua chữ ký và các câu lệnh trả về. Chúng tôi cũng khai thác CL dựa trên các hard negative trong không gian nhúng. Chúng tôi cho thấy rằng chiến lược xây dựng các cặp hard postive và hard negative như vậy đơn giản nhưng rất cần thiết cho việc bimodal contrastive learning hiệu quả.
Chúng tôi huấn luyện ba mô hình biểu diễn mã hóa hai chiều, cụ thể là CODESAGE-SMALL (130M), CODESAGE-BASE (356M) và CODESAGE-LARGE (1.3B). Chúng tôi đánh giá hiệu quả của phương pháp của mình trên nhiều nhiệm vụ phân biệt khác nhau, trong đó CODESAGE vượt trội hơn đáng kể so với các mô hình tiên tiến trước đó có kích thước tương tự trong hầu hết các nhiệm vụ. Để hiểu rõ các yếu tố góp phần vào việc học biểu diễn mã thành công, chúng tôi phân tích tỉ mỉ các thành phần chính của khung làm việc của mình và trình bày những phát hiện của chúng tôi cho các nghiên cứu trong tương lai.
2. Các nghiên cứu liên quan
Embedding for Programming Languages: gần đây đã chứng kiến sự gia tăng đáng kể trong việc học các biểu diễn đa mục đích để hỗ trợ nhiều nhiệm vụ tiếp theo trong ngôn ngữ lập trình. Feng et al. (2020a); Kanade et al. (2020); Li et al. (2023) lấy cảm hứng từ thành công trong xử lý văn bản và tối ưu hóa mục tiêu Masking Language Modeling (MLM) trên dữ liệu mã hóa thành dạng tuyến tính. Tương tự như văn bản, họ cũng tối ưu hóa với mục tiêu phát hiện token được thay thế (Clark et al., 2020) hoặc mục tiêu dự đoán câu tiếp theo (Devlin et al., 2019b) cho mã nguồn. Một dòng nghiên cứu khác tận dụng mặt cấu trúc của mã để cung cấp tín hiệu huấn luyện bổ sung. Trong số đó, Guo et al. (2021) tận dụng luồng dữ liệu để mã hóa mối quan hệ “nơi-giá trị-xuất-phát” giữa các biến. Wang et al. (2021a); Jiang et al. (2021) chèn cấu trúc cú pháp từ abstract syntax tree (AST) thông qua các mục tiêu phụ trợ biến thể. Một công trình mới đây hơn (Guo et al., 2022) làm phẳng cấu trúc AST trực tiếp thành một chuỗi và mã hóa thông tin cú pháp qua các mục tiêu mô hình ngôn ngữ. Wang et al. (2021b); Lachaux et al. (2021) huấn luyện một mô hình ngôn ngữ từ chuỗi đến chuỗi để tái tạo mã gốc từ một mã bị làm rối các tên lớp, hàm và biến bằng các token đặc biệt. Giải mã mà không chỉ rõ nguồn dữ liệu và AST ngầm định mã hóa mà không liên quan đến các mục tiêu phụ trợ hoặc đầu vào phức tạp với sự phân cấp sâu, vì mô hình cần hiểu rõ sự phụ thuộc giữa các biến cũng như cấu trúc mã để dự đoán chính xác tên cho các định danh.
Contrastive Learning: Kể từ những thành công ban đầu của mạng Siamese (Hadsell et al., 2006), học đối lập đã được rộng rãi áp dụng trong học biểu diễn bằng mạng nơ-ron sâu. Song et al. (2016) mở rộng mất mát ba cụm nguyên bản bằng cách so sánh mỗi ví dụ tích cực với tất cả các âm tích cực trong cùng một lô, điều này đã cải thiện đáng kể hiệu quả học và được phổ biến hơn nữa bởi SimCLR (Chen et al., 2020). Tuy nhiên, khác với lĩnh vực tính toán nơi mà các dương tích cực hiệu quả có thể được đạt được bằng các biến đổi ngẫu nhiên của hình ảnh trong không gian đầu vào, việc tăng cường dữ liệu hiệu quả đã lâu là một thách thức trong NLP do tính rời rạc của đầu vào. Thách thức này được khẳng định thêm trong công trình của Gao et al. (2021) chỉ ra rằng dropout (Srivastava et al., 2014) như là biến cố dữ liệu tối thiểu thường hiệu quả hơn so với những biến cố được đạt được bằng cách hoạt động trong không gian đầu vào rời rạc, ví dụ như xóa và thay thế từ.
Một cách tiếp cận khác là các phương pháp đã được đề xuất để tận dụng các cặp tự nhiên làm dương tích cực. Zhou et al. (2022) xem xét các lời nói liên tiếp từ dữ liệu hội thoại như là dương tích cực, trong khi Neelakantan et al. (2022) xem xét các văn bản láng giềng được khai thác từ internet. Một công trình rất gần đây (Wang et al., 2022) tận dụng các cặp câu hỏi và câu trả lời hoặc nhận xét từ StackExchange và Reddit. Trên cùng một hướng đi với ngôn ngữ lập trình, Guo et al. (2022); Wang et al. (2021a); Neelakantan et al. (2022) tận dụng các cặp (văn bản, mã) với văn bản được khai thác từ các docstring. Chúng tôi đi một bước xa hơn bằng việc tập trung vào xây dựng tích cực khó và âm tích cực khó, đây là thành phần chính cho học biểu diễn và cho phép chúng tôi đạt được các mô hình nhúng sẵn sàng sử dụng.
3. Phương pháp
3.1 Mask Language Modeling và Deobfuscation Pre-Tranining.
- Cho một câu đầu vào với $N$ tokens, ví dụ như $\mathbf{x} = [\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_N]$. Mask Language Model (MLM) sẽ cố gắng tối ưu hàm Loss sau:
- Ở đây $\mathcal{M}$ đại diện cho mask áp dụng trên chuỗi ban đầu. Phương trình trên cơ bản là dự báo các từ bị che (mask) với điều kiện câu đầu vào bị che.
- Ví dụ như ta có câu đầu vào như sau: “Con mèo trèo lên cây”. Ta có thể mask từ “trèo” và từ “cây” với token [MASK] như sau: “Con mèo [MASK] lên [MASK]”. Sau đó chúng ta sẽ encoder các từ trong câu đó sang vector 𝑑 chiều. Giá sử chúng ta ra được một tập các vector biểu diễn câu trên như sau $\mathbf{D} = [\mathbf{d}_1, \mathbf{d}_2, \mathbf{d}_3, \mathbf{d}_4, \mathbf{d}_5]$ ($\mathbf{d}_3$ và $\mathbf{d}_5$ chính là biểu diễn vector của token [MASK]). Khi đó hàm Loss sẽ được tính như sau:
Giải mã (deobfuscation): Chúng ta đầu tiên xem xét việc giải mã định danh (DOBF), trong đó tiền huấn luyện mô hình để dự đoán tên các định danh đã bị che giấu. Tương tự như các lập trình viên con người, để giải mã mã nguồn (dự đoán các định danh), mô hình cần phải hiểu cả ngữ nghĩa và cấu trúc của mã nguồn. Cũng cần lưu ý rằng các token ngôn ngữ tự nhiên (NL), tức là các docstring và comment, được loại trừ khỏi việc che giấu mã nguồn. Khi mô hình được huấn luyện để dự đoán tên định danh, nó có thể hưởng lợi từ việc nhìn vào và liên kết với các token NL trong comment hoặc docstring vì chúng thường mang ý nghĩa phong phú về mã nguồn. Kết quả là, mô hình được khuyến khích học các biểu diễn chung giữa ngôn ngữ lập trình và ngôn ngữ tự nhiên tốt hơn, điều này được thể hiện qua hiệu suất tìm kiếm NL2Code tốt hơn mà DOBF đạt được so với chiến lược che giấu ngẫu nhiên.
DOBF ban đầu được đề xuất cho các mô hình Seq2Seq (anne Lachaux et al., 2021; Wang et al., 2021b). Theo hiểu biết của chúng tôi, đây là lần đầu tiên nó được áp dụng cho các mô hình chỉ sử dụng bộ mã hóa. Thách thức chính khi áp dụng DOBF cho các mô hình chỉ sử dụng bộ mã hóa là việc xây dựng bản đồ một-một giữa các token mặt nạ (đầu vào cho mô hình ngôn ngữ - LM) và các token định danh (nhãn đầu ra) do sự khác biệt trong việc mã hóa mã nguồn (ví dụ, sử dụng tree-sitter) và mã hóa cụ thể theo mô hình (ví dụ, sử dụng bộ mã hóa sentencepiece). Chúng tôi thảo luận ngắn gọn về thách thức này trong Phụ lục A.5.
Mặt nạ ngẫu nhiên (Random Masking): Ngoài ra, chúng tôi cũng áp dụng chiến lược mặt nạ token ngẫu nhiên trong BERT (Devlin et al., 2019b) vì hai lý do chính. Thứ nhất, để thúc đẩy các biểu diễn tốt hơn bằng cách giúp mô hình học vượt ra ngoài các định danh. Lấy Python làm ví dụ, khoảng 30% các token mã liên quan đến định danh, do đó có thể đạt được các biểu diễn tốt hơn bằng cách mã hóa thông tin được mang bởi 70% token còn lại. Thứ hai, không phải lập trình viên nào cũng tuân theo quy ước đặt tên, ví dụ: các tên biến vô nghĩa như v1, v2, v3 có thể được sử dụng. Việc dự đoán các token này là không cần thiết và cung cấp tín hiệu huấn luyện rất hạn chế.
Chúng tôi không tuân theo quy ước mặt nạ 80-10-10 được đề xuất trong chuẩn MLM cho văn bản (Devlin et al., 2019b). Vì mã nguồn bao gồm các thành phần ngôn ngữ tự nhiên (NL) và mã (tức là định danh, từ khóa, toán tử), việc thay thế ngẫu nhiên các token có thể làm tổn hại cả cấu trúc và ý nghĩa của mã, dẫn đến sự suy giảm trong học biểu diễn.³ Chúng tôi cho thấy trong Mục 4.2.1 rằng quy ước 80-10-10 này dẫn đến kết quả kém hơn một cách nhất quán trong các tác vụ hạ nguồn. Trong bài báo này, chúng tôi cũng đặt tỷ lệ mặt nạ ngẫu nhiên là 15%, mà chúng tôi thấy là tối ưu thông qua nghiên cứu cắt lớp của mình (trình bày trong Phụ lục A.4). Với mỗi tập huấn luyện, chúng tôi chọn ngẫu nhiên giữa DOBF hoặc mặt nạ ngẫu nhiên với xác suất bằng nhau.
3.2 Bimodal Contrastive Learning với Hard Negative và Hard Posotive
- Giả sử $x_i, x_{i+}$ kí hiệu cho một cặp positive input, cặp này có thể được tạo ra bởi data augmentation từ anchor ban đầu (nhưng không đảm bảo việc các phần tử được tạo ra từ achor là một cặp positive input), $h_i, h_{i+}$ là representations của $x_i, x_{i+}$ qua layer cuối cùng của encoder.
- Đặt $\mathcal{B} = [h_1, h_{1+}, h_2, h_{2+}, \dots, h_N, h_{N+}]$ kí hiệu cho một tập $h_i, h_{i+}$ được chọn ngẫu nhiên từ một batch có $N$ cặp. Chúng ta phải tối ưu hóa hàm Loss đối xứng sau:
Ở đây, $\tau$ là siêu tham số nhiệt độ mà chúng tôi đặt giá trị là 0.05 trong nghiên cứu này. Ký hiệu $\cdot$ biểu thị sự tương đồng cosine giữa hai vector biểu diễn. $\gamma_i^k$ là tham số trọng số, sẽ được giải thích chi tiết sau.
Hard Negative: Vì đây không phải là bài toán có giám sát nên khá khó để xác định hard negative. Chúng tôi sử dụng một phương pháp không giám sát dựa trên khoảng cách, được đề xuất bởi Zhang et al. (2021). Với một anchor $h_i$, các hard negative là những ví dụ khác nhau về mặt ngữ nghĩa nhưng được ánh xạ gần $h_i$ trong không gian biểu diễn. Do đó, một hard negative càng gần với anchor $h_i$ trong không gian biểu diễn thì giá trị $\gamma$ mong muốn càng lớn, cụ thể được tính bởi công thức sau:
Điều này có nghĩa là $\gamma_i^k$ ước lượng tầm quan trọng tương đối của $h_k$ đối với điểm neo $h_i$ trong số tất cả $2N-2$ điểm âm trong batch. Mặc dù các ví dụ huấn luyện có tính tương đương ngữ nghĩa ngoại trừ các cặp tích cực đã cho không có sẵn trong trường hợp của chúng tôi, sự ước lượng ở trên đối với các điểm âm khó (hard negatives) vẫn hợp lý. Để thấy được điều này, lưu ý rằng mỗi batch huấn luyện được lấy mẫu ngẫu nhiên với kích thước nhỏ hơn nhiều so với kích thước của toàn bộ dữ liệu huấn luyện. Do đó, sự hiện diện của các điểm âm sai trong mỗi batch là rất nhỏ miễn là dữ liệu huấn luyện đủ lớn và đa dạng. Trong bài viết này, chúng tôi đặt kích thước batch (N) là 8K, dưới điều kiện này, chúng tôi quan sát thấy hiệu suất tăng đơn điệu được báo cáo trên các tác vụ hạ nguồn.
- Hard Positive: Chúng tôi xem xét các cặp (văn bản, hàm) xuất hiện tự nhiên như là các cặp tích cực, trong đó văn bản được trích xuất từ chuỗi tài liệu (docstring) của hàm (Husain và cộng sự, 2019). Văn bản trích xuất từ docstring thường tóm tắt tốt các ngữ nghĩa cấp cao của mã. Do đó, việc học đối kháng với dữ liệu hai chiều, tức là các cặp văn bản và hàm, nâng cao đáng kể hiệu suất tìm kiếm ngữ nghĩa NL2Code. Trong Mục 4.2.2, thêm vào đó, văn bản được trích xuất từ mã tương đương ngữ nghĩa, bất kể từ cùng một ngôn ngữ lập trình hay các ngôn ngữ khác nhau, thường kém đa dạng hơn so với chính mã đó. Do đó, các mã tương tự ngữ nghĩa có thể được nhóm lại với nhau một cách ngầm thông qua các văn bản tóm tắt giống nhau hoặc rất tương tự. Kết luận của chúng tôi được xác thực bởi sự cải thiện hiệu suất lớn đạt được khi học đối kháng trong cả tìm kiếm Code2Code cùng ngôn ngữ và khác ngôn ngữ trong Mục 4.2.2.
- Cũng dễ thấy rằng các tên hàm và tên biến đầu vào thường chia sẻ sự tương đồng đáng kể, đặc biệt là về mức độ trùng lặp từ vựng với văn bản tóm tắt. Chúng tôi tiếp tục định lượng mức độ trùng lặp này với các thống kê chi tiết trong Phụ lục A.6. Từ đó, chúng tôi tạo các hard positives bằng cách loại bỏ cả chữ ký hàm và các câu lệnh trả về. Như được minh họa trong Mục 4.2.2, các hard positives được hình thành theo cách này có thể cải thiện đáng kể hiệu suất của việc học đối kháng.
Coming soon