Crawl Dữ Liệu
Dữ liệu ngày càng trở thành tài nguyên quý giá, và việc thu thập, phân tích chúng là một kỹ năng quan trọng trong thời đại số. Crawl dữ liệu (hay còn gọi là web scraping) là quá trình tự động thu thập thông tin từ các trang web bằng cách sử dụng các công cụ phần mềm. Mục tiêu của crawl dữ liệu là trích xuất các dữ liệu hữu ích từ các trang web một cách nhanh chóng và hiệu quả. Kỹ thuật này có thể được ứng dụng trong nhiều lĩnh vực như nghiên cứu thị trường, theo dõi giá cả, phân tích đối thủ cạnh tranh hay xây dựng cơ sở dữ liệu. Tuy nhiên, cần lưu ý đến các vấn đề về bản quyền và quyền riêng tư khi thực hiện crawl dữ liệu để tuân thủ các quy định pháp luật.
1. Web Scarping.
- Web scraping là quá trình tự động trích xuất dữ liệu từ các trang web. Nó bao gồm việc lấy dữ liệu từ các trang web, phân tích nội dung HTML và sau đó trích xuất thông tin cụ thể từ đó.
- Web scraping cho phép bạn thu nhập dữ liệu từ các trang web khác nhau một cách hiệu quả, mà không cần nhập liệu thủ công.
2. Crawl Process.
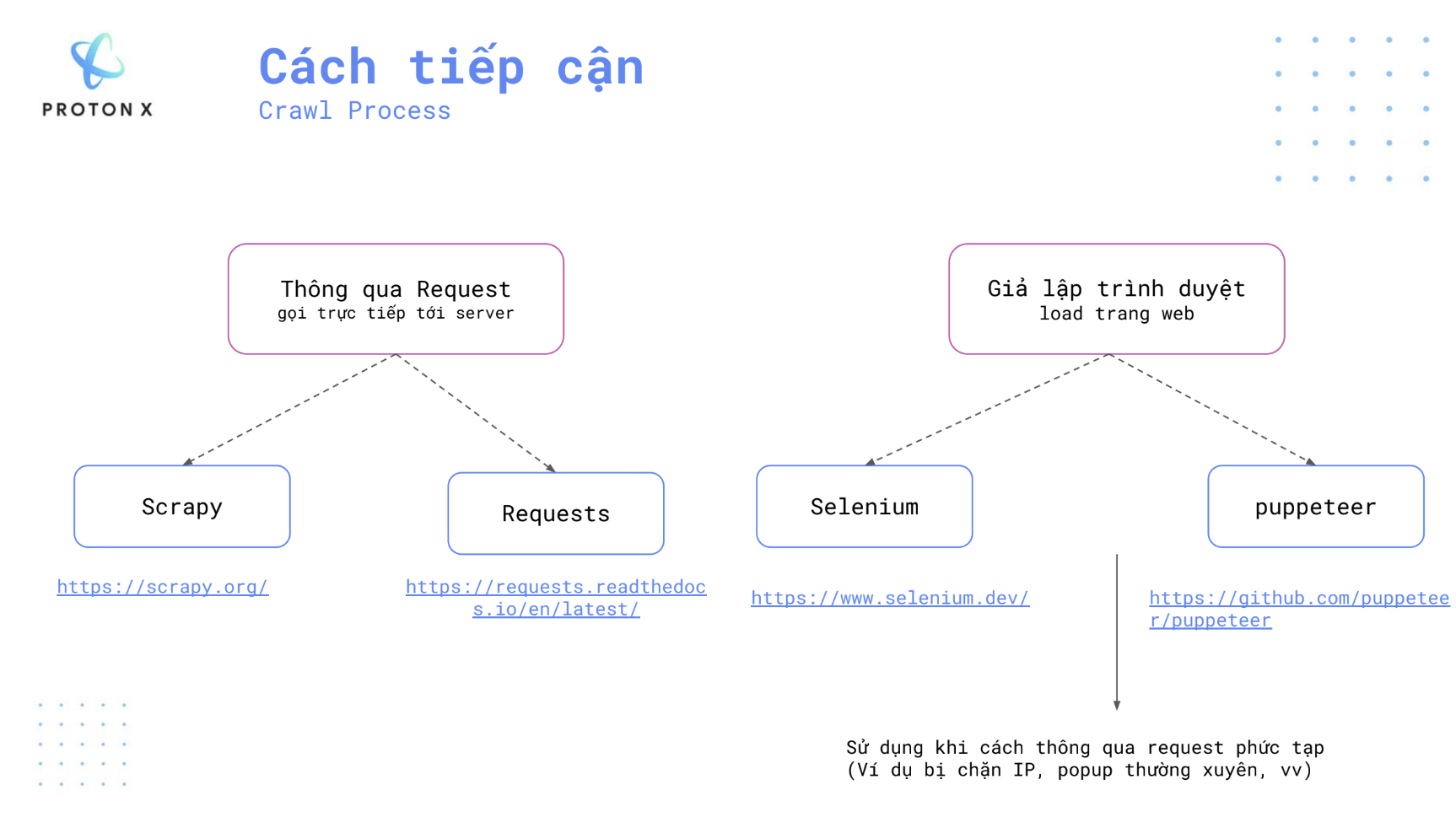
2.1. Thông qua Request (Direct Request to Server)
Phương pháp này sử dụng các yêu cầu HTTP để gửi trực tiếp tới server của trang web, nhằm thu thập dữ liệu mà không cần tải toàn bộ nội dung trang web (như giao diện, JavaScript). Điều này giúp quá trình thu thập dữ liệu nhanh hơn và nhẹ hơn, nhưng có thể bị giới hạn bởi các chính sách chặn của trang web hoặc thiếu nội dung động.
Scrapy: Đây là một framework mạnh mẽ, được thiết kế đặc biệt để thu thập dữ liệu từ các trang web một cách hệ thống và nhanh chóng. Scrapy phù hợp với các dự án thu thập dữ liệu lớn, có khả năng xử lý các trang có cấu trúc phức tạp, hỗ trợ việc theo dõi liên kết và quản lý dữ liệu. Scrapy giúp người dùng định nghĩa cách thu thập dữ liệu bằng cách tạo ra các spiders (con nhện) để tự động khám phá và lấy nội dung từ nhiều trang web. Trang chủ Scrapy
Requests: Requests là một thư viện HTTP đơn giản nhưng mạnh mẽ trong Python, giúp người dùng gửi các yêu cầu HTTP như GET hoặc POST một cách dễ dàng. Nó thường được sử dụng khi cần thu thập dữ liệu từ các trang có cấu trúc đơn giản hoặc không yêu cầu tải nhiều nội dung động. Requests giúp thao tác với API và lấy các phản hồi từ server mà không cần phải xử lý các yếu tố phức tạp như JavaScript. Tài liệu Requests
2.2. Giả lập trình duyệt (Browser Simulation)
Phương pháp này mô phỏng một trình duyệt thực để tải toàn bộ nội dung trang web, bao gồm cả các yếu tố động như JavaScript hoặc các thành phần không thể truy cập chỉ thông qua HTTP request đơn thuần. Phương pháp này có thể chậm hơn do phải tải toàn bộ trang, nhưng cần thiết khi trang web sử dụng nhiều JavaScript để hiển thị nội dung.
Selenium: Selenium là một công cụ phổ biến để tự động hóa trình duyệt. Nó có thể điều khiển các trình duyệt thực như Chrome hoặc Firefox, cho phép người dùng thao tác và thu thập dữ liệu từ các trang web mà không thể thu thập thông qua yêu cầu HTTP đơn giản. Selenium phù hợp khi bạn cần tương tác với các thành phần động của trang web như nút, form, popup, hoặc xử lý JavaScript phức tạp. Selenium có thể được sử dụng để thực hiện kiểm thử tự động hoặc crawl các trang web có nội dung động.
Trang chủ SeleniumPuppeteer: Puppeteer là một thư viện JavaScript giúp điều khiển các trình duyệt Chromium (như Google Chrome) một cách chương trình hóa. Nó thường được sử dụng để thực hiện các tác vụ như tạo ảnh chụp màn hình, tạo PDF từ trang web, hoặc thu thập dữ liệu từ các trang web có nhiều nội dung động. Puppeteer cung cấp API cho phép kiểm soát chính xác những gì trình duyệt làm, phù hợp cho các dự án yêu cầu mức độ tự động hóa cao và cần tương tác sâu với nội dung trang web. Github Puppeteer
Ghi chú:
- Các phương pháp giả lập trình duyệt thường được sử dụng khi phương pháp thông qua request gặp phải các hạn chế, chẳng hạn như:
- Trang web chặn IP của người gửi request.
- Các trang có nhiều popup hoặc yêu cầu tương tác động.
- Các trang sử dụng JavaScript để hiển thị dữ liệu, khiến dữ liệu không xuất hiện khi chỉ gửi request thông thường.
3. Cách Web Scraping hoạt động.
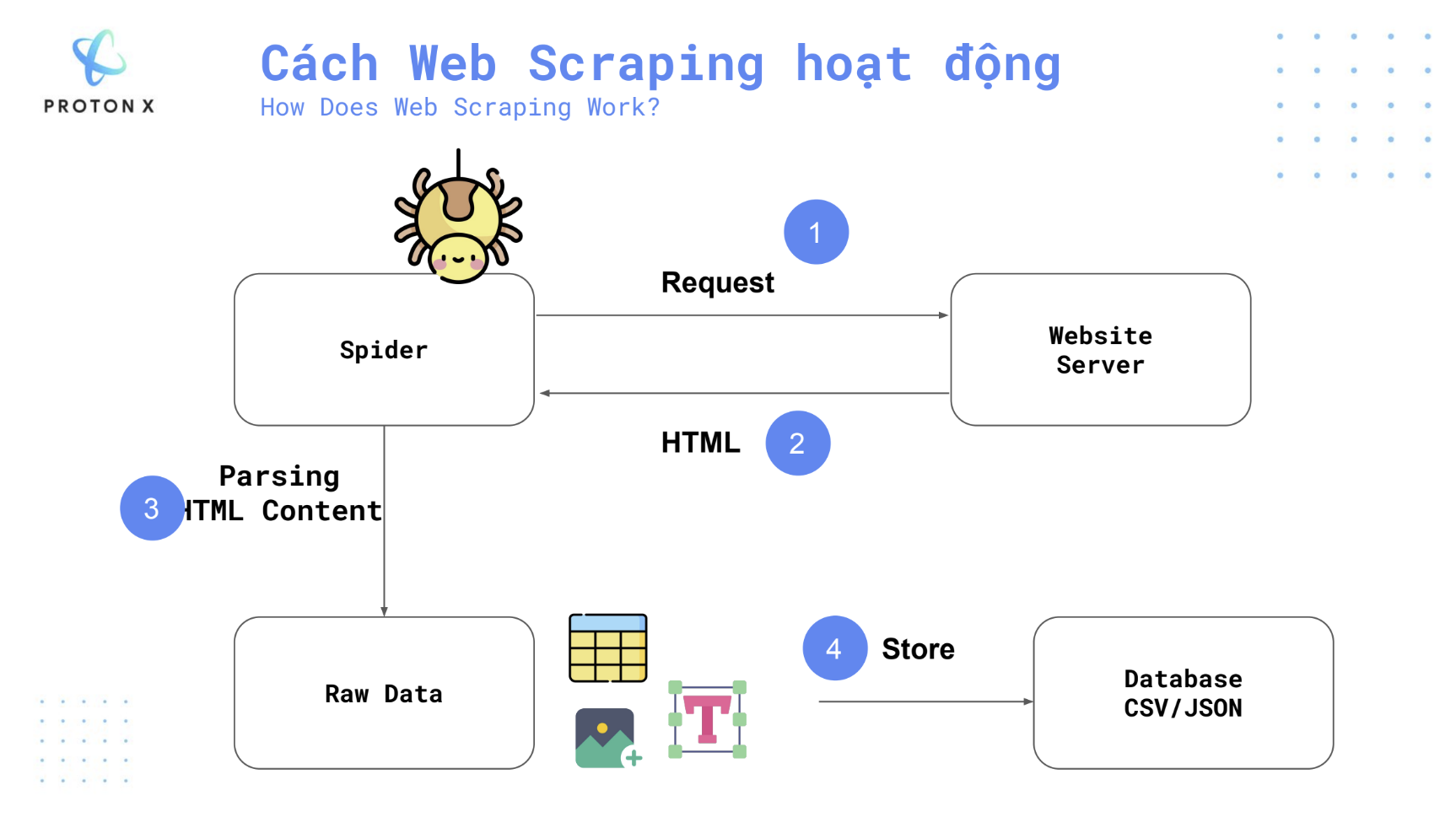
Quy trình web scraping hoạt động qua bốn bước chính, giúp thu thập dữ liệu từ các trang web một cách tự động và có hệ thống. Dưới đây là chi tiết từng bước:
1. Request (Gửi yêu cầu tới máy chủ)
- Spider (con nhện), là một chương trình hoặc tập lệnh được thiết kế để tự động duyệt các trang web và thu thập dữ liệu. Bước đầu tiên của quy trình là spider gửi một yêu cầu HTTP (thường là GET request) tới máy chủ trang web.
- Máy chủ trang web nhận được yêu cầu này giống như khi người dùng truy cập trang web bằng trình duyệt thông thường.
- Yêu cầu này có thể được cấu hình để chứa thông tin về user-agent, cookie, hoặc các thông tin xác thực khác nếu cần.
2. Receive HTML (Nhận mã HTML từ máy chủ)
- Khi máy chủ nhận yêu cầu từ spider, nó sẽ phản hồi bằng cách gửi lại mã HTML của trang web. Mã HTML này chứa toàn bộ nội dung mà người dùng nhìn thấy trên trang web (các văn bản, hình ảnh, liên kết, và các thành phần khác).
- Đối với các trang web động sử dụng JavaScript để tải dữ liệu, đôi khi chỉ nhận được mã HTML cơ bản ban đầu, và việc tải nội dung động sẽ cần các công cụ đặc biệt như Selenium hoặc Puppeteer để xử lý.
3. Parsing HTML Content (Phân tích nội dung HTML)
- Sau khi spider nhận được mã HTML, nó bắt đầu quá trình phân tích nội dung HTML. Đây là bước spider tách lọc và trích xuất dữ liệu cần thiết từ trang web.
- Các bước phân tích có thể bao gồm:
- Tìm kiếm các thẻ HTML cụ thể (ví dụ:
<div>,<a>,<p>,<img>). - Trích xuất văn bản, liên kết, hình ảnh, hoặc các thông tin khác tùy vào mục tiêu của quá trình scraping.
- Nếu trang web có cấu trúc phức tạp hoặc không đồng nhất, người dùng có thể phải viết các logic riêng để xử lý việc phân tích và trích xuất dữ liệu một cách chính xác.
- Tìm kiếm các thẻ HTML cụ thể (ví dụ:
- Công cụ phổ biến dùng cho bước này bao gồm:
- BeautifulSoup (Python): Một thư viện giúp phân tích và trích xuất dữ liệu từ HTML dễ dàng.
- lxml: Một công cụ xử lý HTML/XML hiệu quả và tốc độ cao.
4. Store Data (Lưu trữ dữ liệu)
- Sau khi dữ liệu được trích xuất từ HTML, bước cuối cùng là lưu trữ dữ liệu vào các định dạng hoặc cơ sở dữ liệu phù hợp.
- Các lựa chọn phổ biến cho việc lưu trữ dữ liệu bao gồm:
- CSV (Comma-Separated Values): Định dạng tệp văn bản đơn giản thường được sử dụng để lưu trữ dữ liệu bảng biểu.
- JSON (JavaScript Object Notation): Định dạng phổ biến để lưu trữ và trao đổi dữ liệu có cấu trúc, đặc biệt hữu ích khi làm việc với API hoặc các dịch vụ web.
- Cơ sở dữ liệu (Database): Dữ liệu có thể được lưu trực tiếp vào cơ sở dữ liệu như MySQL, MongoDB, PostgreSQL, để dễ dàng truy cập và xử lý sau này.
- Quá trình lưu trữ còn phụ thuộc vào yêu cầu và khối lượng dữ liệu. Đối với các dự án nhỏ, CSV hoặc JSON là lựa chọn đơn giản. Với các dự án lớn, việc sử dụng cơ sở dữ liệu sẽ giúp quản lý dữ liệu hiệu quả hơn.
Tổng kết quy trình:
- Spider gửi yêu cầu HTTP tới máy chủ.
- Máy chủ phản hồi bằng mã HTML.
- Spider phân tích và trích xuất nội dung từ mã HTML.
- Dữ liệu thu thập được lưu trữ vào các tệp hoặc cơ sở dữ liệu để sử dụng sau này.
Quy trình này có thể được lặp lại nhiều lần để thu thập dữ liệu từ nhiều trang web hoặc trang con khác nhau trong cùng một trang web.
4. Cách sử dụng thư viện Scarpy.
Tạo Scrapy Project.
- Sử dung lệnh sau để tạo một project với thư viện Scarpy (ví dụ này mình đặt tên là chanhtuoi vì mình sẽ crawl dữ liệu từ trang web chanhtuoi.com):
scrapy startproject chanhtuoi
- Lệnh này sẽ tạo ra một cấu trúc thư mục cơ bản như sau:
1
2
3
4
5
6
7
8
9
10
chanhtuoi/
scrapy.cfg
chanhtuoi/
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
spiders/
__init__.py
scrapy.cfg: Tệp cấu hình triển khai (deploy configuration file), nơi lưu trữ các thông tin về cài đặt chung của dự án.
chanhtuoi/: Đây là thư mục chính của dự án với nhiều tệp và thư mục con, bao gồm:
- __init__.py: Tệp khởi tạo của module Python. Bạn sẽ import code của mình từ đây.
- items.py: Tệp định nghĩa các đối tượng (items) mà bạn sẽ thu thập từ trang web. Bạn có thể khai báo cấu trúc dữ liệu mà spider sẽ lấy, chẳng hạn như tiêu đề bài viết, giá sản phẩm, hoặc liên kết.
- middlewares.py: Tệp chứa các middleware của dự án. Middleware là các lớp nằm giữa quá trình request/response, giúp điều chỉnh và xử lý request hoặc phản hồi từ spider.
- pipelines.py: Tệp xử lý dữ liệu sau khi spider thu thập. Dữ liệu sau khi được spider thu thập có thể được làm sạch, chuyển đổi hoặc lưu trữ vào cơ sở dữ liệu tại đây.
- settings.py: Tệp cấu hình dự án. Bạn có thể điều chỉnh các thông số như thời gian chờ (timeout), số lượng spider chạy đồng thời, user-agent, và nhiều thiết lập khác.
- spiders/: Thư mục chứa các spider của bạn. Đây là nơi bạn sẽ viết mã để định nghĩa cách mà spider thu thập dữ liệu từ các trang web.
- Nói một cách đơn giản thì mục đích của từng file là:
- scrapy.cfg: Định nghĩa cấu hình toàn bộ dự án.
- items.py: Xác định cấu trúc của dữ liệu mà bạn muốn thu thập (các đối tượng cần scrape).
- middlewares.py: Điều chỉnh quá trình request và response trước và sau khi spider thực hiện.
- pipelines.py: Xử lý dữ liệu trước khi lưu trữ, chẳng hạn như làm sạch dữ liệu hoặc lưu vào cơ sở dữ liệu.
- settings.py: Quản lý các thông số cấu hình cho spider và dự án.
- spiders/: Nơi bạn sẽ tạo các spider để định nghĩa logic cho việc crawl dữ liệu.
Kiến trúc của Scrapy.
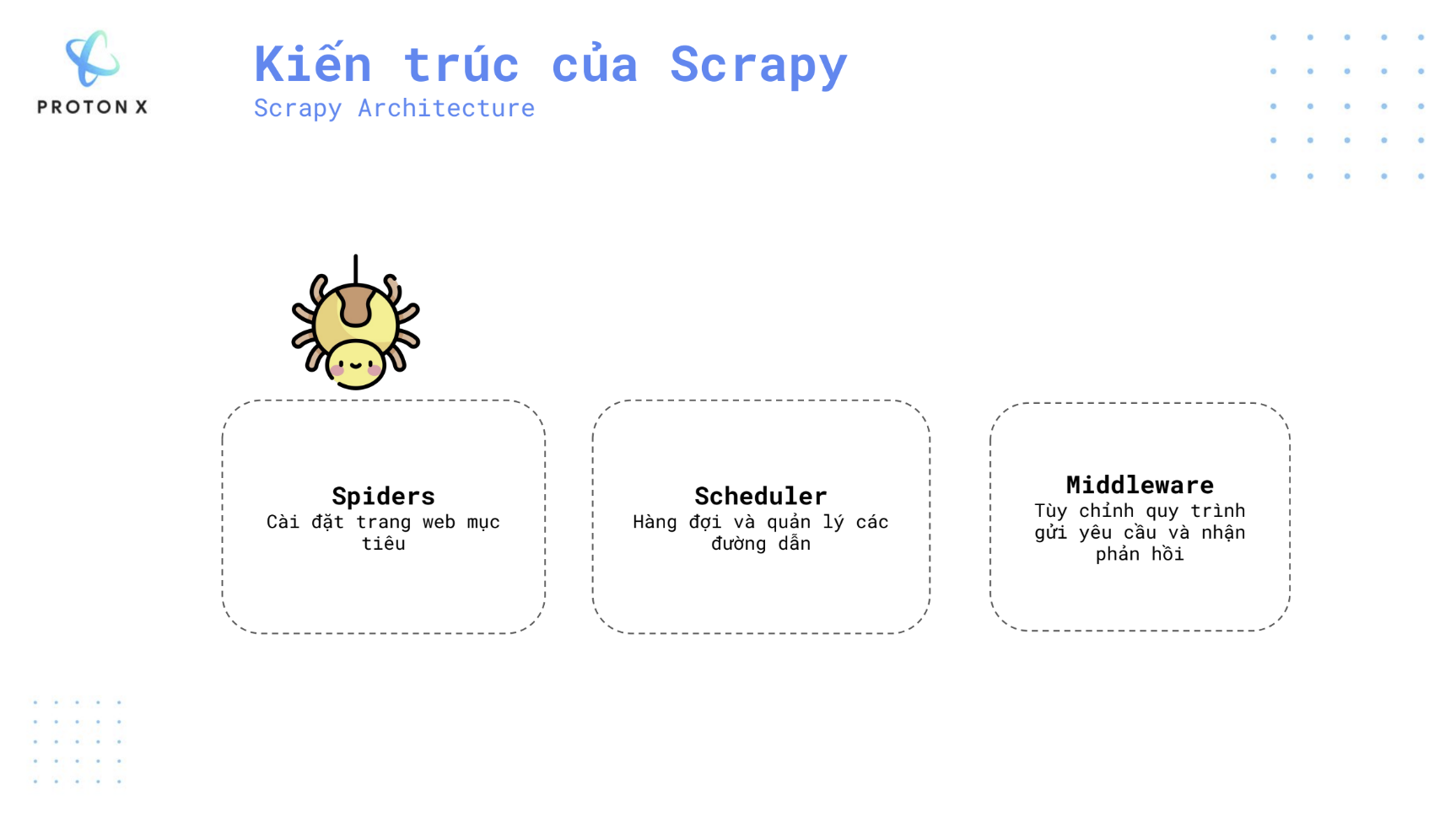
Scrapy có ba thành phần chính trong kiến trúc của nó: Spiders, Scheduler, và Middleware. Mỗi thành phần đóng một vai trò cụ thể trong việc quản lý và thu thập dữ liệu từ các trang web.
- Spiders là thành phần chính trong Scrapy, nơi bạn định nghĩa logic để thu thập dữ liệu từ các trang web mục tiêu.
- Nhiệm vụ của spiders bao gồm:
- Xác định các URL mà bạn muốn truy cập.
- Phân tích mã HTML của trang để trích xuất dữ liệu.
- Theo dõi các liên kết khác để tiếp tục thu thập dữ liệu từ các trang liên quan.
- Một spider có thể được tùy chỉnh để tương tác với các phần tử HTML cụ thể của trang web, giúp thu thập các trường dữ liệu bạn muốn.
- Scheduler là bộ lập lịch quản lý các yêu cầu (request) do spider gửi đi.
- Vai trò của scheduler bao gồm:
- Xếp các yêu cầu vào hàng đợi để gửi đến máy chủ của trang web.
- Quản lý việc xử lý các yêu cầu một cách hiệu quả, đảm bảo rằng không có yêu cầu nào bị trùng lặp hoặc bị bỏ sót.
- Điều phối và sắp xếp yêu cầu theo thứ tự phù hợp để sử dụng tài nguyên hiệu quả nhất.
Scheduler đóng vai trò quan trọng trong việc đảm bảo Scrapy thu thập dữ liệu một cách hệ thống và không bị quá tải bởi quá nhiều yêu cầu.
- Middleware là các lớp trung gian cho phép bạn tùy chỉnh quá trình xử lý yêu cầu (request) và phản hồi (response) giữa spiders và scheduler.
- Vai trò của middleware bao gồm:
- Điều chỉnh yêu cầu trước khi chúng được gửi tới máy chủ, ví dụ như thêm các headers, cookies, hoặc thay đổi user-agent.
- Xử lý phản hồi trước khi nó được gửi tới spider, có thể là sửa đổi hoặc phân tích thêm dữ liệu từ phản hồi.
- Quản lý các tình huống như yêu cầu xác thực hoặc xử lý lỗi khi gặp sự cố trong quá trình gửi yêu cầu.
- Middleware cung cấp mức độ kiểm soát cao hơn cho người dùng, đặc biệt hữu ích khi cần tương tác với các trang web có cấu trúc bảo mật phức tạp.
Coming Soon…