Dự Án Học Máy Từ Đầu Đến Cuối
Đây là bài cuối cùng trong phần Machine Learning cơ bản, tôi viết bài này trước tại vì tôi muốn, hãy cân nhắc bạn có đủ kiến thức để đọc nó. Trong blog này, chúng ta sẽ đóng vai nhà khoa học dữ liệu vừa được tuyển dụng bởi một công ty bất động sản, và sẽ làm việc trong một dự án từ đầu đến cuối. Dưới đây là những bước mà ta sẽ thực hiện:
- Nhìn vào bức tranh tổng thể.
- Lấy dữ liệu.
- Khám phá và trực quan hóa để hiểu dữ liệu.
- Chuẩn bị dữ liệu cho các thuật toán Học Máy.
- Lựa chọn và huấn luyện mô hình Học Máy.
- Tinh chỉnh mô hình Học Máy.
- Trình bày giải pháp.
- Triển khai, giám sát và bảo trì hệ thống.
1. Làm việc với dữ liệu thực
- Khi tìm hiểu về Học Máy, cách tốt nhất là thử nghiệm trên dữ liệu thực tế thay vì các tập dữ liệu nhân tạo. May mắn thay, hiện nay ta có thể sử dụng hàng ngàn tập dữ liệu mở trong hầu hết các lĩnh vực. Dưới đây là một số nguồn để lấy dữ liệu mà bạn có thể tham khảo:
- Các kho dữ liệu mở phổ biến:
- Cổng thông tin các kho dữ liệu mở:
- Các trang web khác:
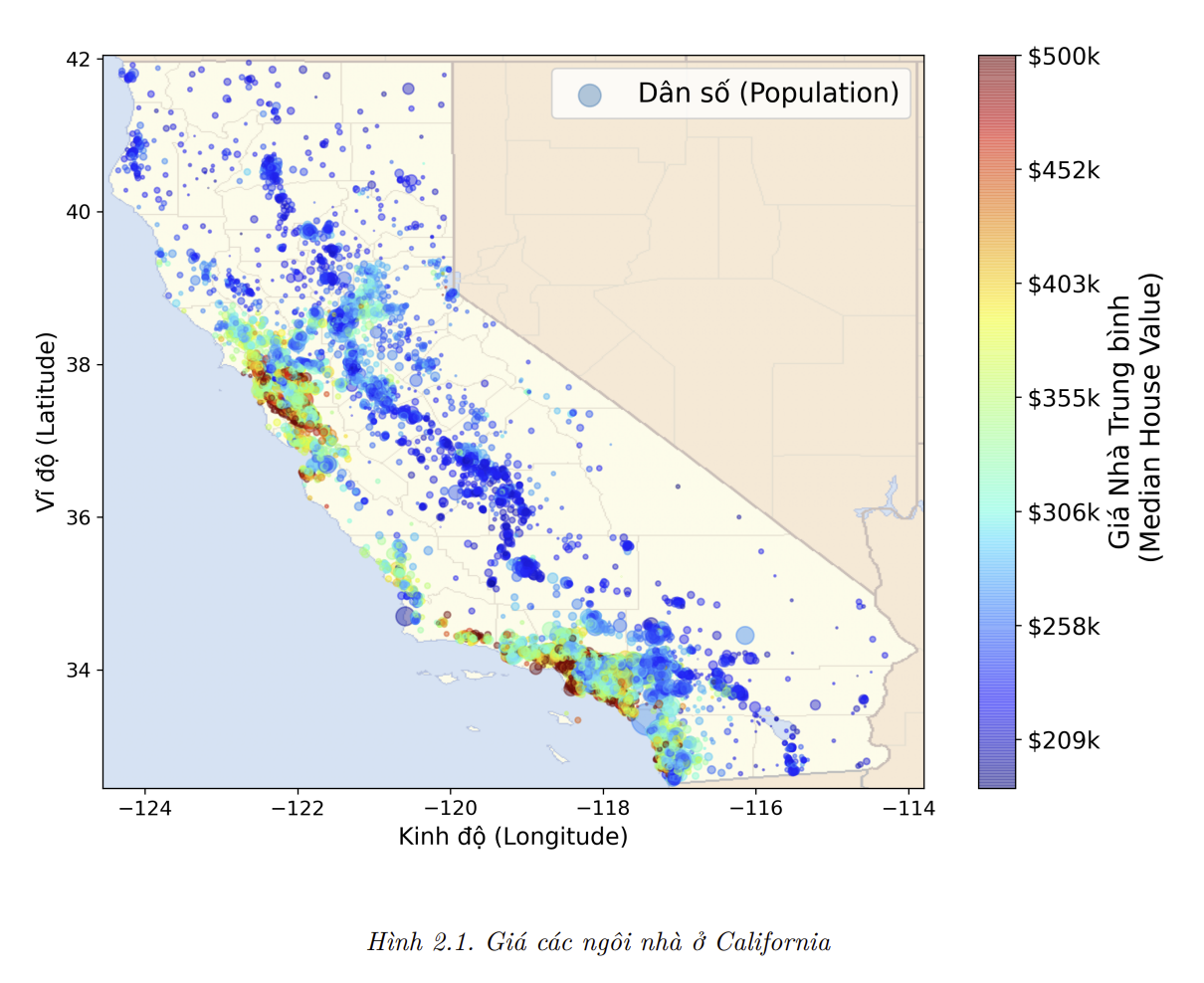
- Trong chương này, chúng ta sẽ sử dụng tập dữ liệu Giá nhà ở California từ kho dữ liệu StatLib (tham khảo hình 2.1). Tập dữ liệu này dựa trên kết quả của cuộc điều tra dân số năm 1990 ở bang California. Nó không phản ánh đúng giá cả hiện tại (giá một ngồi nhà tốt ở Bay Area lúc đó vẫn còn rẻ), nhưng lại sở hữu nhiều tính chất hỗ trợ việc học nên hãy cứ giả sử rằng tập dữ liệu này mới được thu nhập gần đây. Để phù hợp với mục đích giảng dạy, tôi đã thêm vào một vài thuộc tính hạng mục và loại bỏ một vài đặc trưng:
2. Nhìn vào bức tranh tổng thể
- Nhiệm vụ đầu tiên của bạn là sử dụng tập dữ liệu điều tra dân số của bang California để xây dựng một mô hình dự đoán giá nhà tại bang. Dữ liệu này bao gồm các số liệu như dân số, thu nhập trung vị và giá nhà trung vị cho từng block ở California. Block là đơn vị địa lý nhỏ nhất mà cục điều tra dân số Hoa Kỳ sử dụng để công bố dữ liệu mẫu (một block thường có dân số từ 600 đến 3,000 người). Để thuận tiện, ta sẽ gọi các block là các “quận”.
- Mô hình của ta sẽ cần học từ tập dữ liệu này và dự đoán giá nhà trung vị cho một quận bất kỳ, dựa trên tất cả các số liệu đã cho.
💹 Mẹo: Là một nhà khoa học dữ liệu bài bản, việc đầu tiên bạn cần làm là tạo một danh mục công việc cho dự án Học Máy. Bạn có thể bắt đầu bằng cách tham khảo Phụ lục cuối cùng của blog này, mô tả một khuôn mẫu phù hợp cho hầu hết các dự án Học Máy. Tuy nhiên, hãy điều chỉnh danh mục công việc theo nhu cầu cụ thể của bạn. Trong blog này, tôi sẽ thực hiện nhiều việc trong danh mục, nhưng cũng sẽ bỏ qua một vài việc do chúng không cần thiết.
Phát biểu bài toán
Trước hết, bạn nên hỏi sếp về mục tiêu của dự án. Xây dựng một mô hình có lẽ không phải là mục tiêu cuối cùng. Công ty sẽ sử dụng và thu lợi từ mô hình này như thế nào? Biết được mục tiêu rất quan trọng vì nó sẽ xác định cách bạn phát biểu bài toán, thuật toán được lựa chọn, phép đo chất lượng mà bạn sẽ sử dụng để đánh giá mô hình và công sức bạn cần bỏ ra để tinh chỉnh nó.
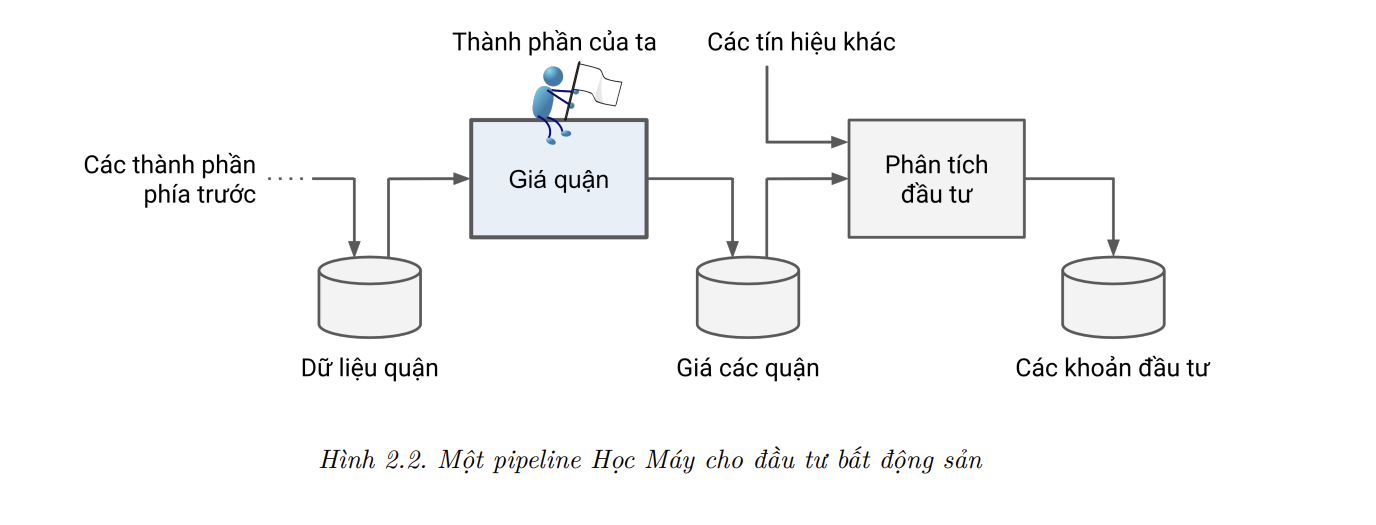
Sếp của bạn trả lời rằng đầu ra của mô hình (dự đoán giá nhà trung vị của một quận) sẽ được đưa tiếp vào một hệ thống Học Máy khác (tham khảo Hình 2.2), cùng với các dữ liệu khác. Hệ thống này sẽ xác định liệu có đáng để đầu tư vào một khu vực nào đó hay không. Việc nắm được thông tin này rất quan trọng, vì nó ảnh hưởng trực tiếp tới lợi nhuận của công ty.
Câu hỏi tiếp theo cho sếp là về giải pháp hiện tại (nếu có). Tình hình hiện tại thường sẽ cung cấp một cách đối chiếu chất lượng, đồng thời giúp ta hiểu thêm về các phương pháp giải quyết vấn đề. Sếp của bạn trả lời rằng giá nhà ở của một quận hiện được chuyên gia ước lượng một cách thủ công: một nhóm thu thập các thông tin cơ bản về quận đó và khi không có giá nhà trung vị, họ ước lượng nó bằng các quy tắc phức tạp.
Cách này rất tốn kém và mất thời gian, và các giá trị ước lượng thường không chính xác. Trong trường hợp tìm được giá nhà trung vị thực tế, họ nhận thấy rằng các ước lượng thường sai lệch hơn 20%. Do đó, công ty cho rằng sẽ rất hữu ích nếu huấn luyện được một mô hình dự đoán giá nhà trung vị của các quận, khi biết các dữ liệu khác về quận đó. Dữ liệu hiện ra dần đó được coi là một tập dữ liệu tuyệt vời để sử dụng cho mục đích này, vì nó bao gồm giá nhà trung vị của hàng nghìn quận, cũng như các dữ liệu khác.
Với tất cả những thông tin trên, bây giờ bạn đã sẵn sàng để bắt đầu thiết kế hệ thống của mình. Đầu tiên, bạn cần xác định bài toán: đây là bài toán học có giám sát, học không giám sát, hay học tăng cường? Đây là bài toán phân loại, hồi quy, hay một bài toán khác? Bạn nên sử dụng kỹ thuật học theo batch hay học trực tuyến? Trước khi đọc tiếp, bạn đọc hãy tạm dừng một chút và cố gắng tự trả lời những câu hỏi này.
Bạn đã tìm thấy câu trả lời chưa? Có thể thấy, rõ ràng đây là một bài toán học có giám sát điển hình, vì bạn có một tập dữ liệu huấn luyện đã được gán nhân (mỗi mẫu có một giá trị nhân tương ứng, trong trường hợp này là giá nhà ở trung vị của quận đó). Đây cũng là một bài toán hồi quy điển hình, vì bạn được yêu cầu dự đoán một giá trị. Cụ thể hơn, đây là bài toán đa hồi quy (multiple regression), vì hệ thống sẽ sử dụng nhiều đặc trưng để đưa ra dự đoán (như dân số của quận, trung vị thu nhập, v.v.). Đây cũng là bài toán hồi quy đơn biến (univariate regression), vì ta chỉ dự đoán một giá trị cho một quận. Nếu ta dự đoán nhiều giá trị cho một quận, thì nó sẽ là bài toán hồi quy đa biến (multivariate regression). Cuối cùng, do không có lượng dữ liệu lớn tới hệ thống nên ta sẽ không cần phải điều chỉnh để thích nghi với dữ liệu một cách nhanh chóng. Đồng thời, dữ liệu đủ nhỏ để đưa vào bộ nhớ, nên ta có thể đơn thuần sử dụng phương pháp học theo batch.
💹 Mẹo: Nếu lượng dữ liệu quá lớn, ta có thể chia nhỏ việc học theo batch ra các server (sử dụng kỹ thuật MapReduce) hoặc sử dụng phương pháp học trực tuyến.
Lựa chọn phép đo chất lượng
- Bước tiếp theo là lựa chọn một phép đo chất lượng phù hợp. Một phép đo chất lượng điển hình trong bài toán hồi quy là căn bậc hai trung bình bình phương sai số (Root Mean Square Error - RMSE). Phép đo này cho biết sai số mà hệ thống thường phạm phải khi đưa ra dự đoán, với trọng số lớn cho những sai số lớn. Phương trình dưới trình bày công thức toán học để tính giá trị RMSE:
- Mặc dù RMSE nhìn chung khá phổ biến cho bài toán hồi quy, trong một vài trường hợp ta có thể lựa chọn phép đo khác. Ví dụ, giả sử tập dữ liệu có nhiều quận ngoại lai. Trong trường hợp này, bạn có thể cân nhác sử dụng trung bình sai số tuyệt đối (Mean Absolute Error - MAE) hay còn được gọi là trung bình độ lệch tuyệt đối:
- Ngoài ra thì phép đo trung bình bình phương sai số (Mean Square Error - MSE) cũng được sử dụng phổ biến:
- Bảng dưới đây so sánh ba phép đo dựa trên từng tiêu chí:
| Tiêu chí | MAE | MSE | RMSE |
|---|---|---|---|
| Mức độ nhạy cảm với outliers | Ít nhạy cảm. | Rất nhạy cảm (phạt sai số lớn hơn). | Rất nhạy cảm (như MSE). |
| Tập trung vào sai số lớn | Không ưu tiên sai số lớn. | Phạt nặng sai số lớn. | Phạt nặng sai số lớn. |
| Khả năng tối ưu hóa (Hàm cost) | Khó tối ưu vì đạo hàm không liên tục. | Dễ tối ưu vì đạo hàm liên tục. | Dễ tối ưu vì đạo hàm liên tục. |
| Độ phức tạp tính toán | Thấp. | Trung bình. | Cao hơn MSE do có căn bậc hai. |
| Khi nào nên dùng? | Khi dữ liệu có nhiều outliers. | Khi sai số lớn cần chú trọng. | Khi cần diễn giải sai số trực quan. |
| Ví dụ ứng dụng | Dự đoán giá nhà trong dữ liệu nhiễu. | Bài toán hồi quy chính xác cao. | Dự báo thời tiết, nhiệt độ,… |
Kiểm tra các giả định
Cuối cùng, việc liệt kê và kiểm tra các giả định đã được đưa ra (bởi bạn hoặc người khác) là một thói quen tốt. Việc này giúp ta sớm phát hiện các vấn đề nghiêm trọng. Ví dụ: giá nhà ở một quận mà hệ thống dự đoán sẽ được đưa vào một hệ thống Học Máy khác và ta giả định rằng những giá trị này vẫn được sử dụng ở định dạng số. Nhưng điều gì sẽ xảy ra nếu hệ thống tiếp theo chuyển đổi giá nhà ở thành các hạng mục (ví dụ: “rẻ”, “trung bình” hoặc “đắt”) và sau đó sử dụng các hạng mục đó thay vì các con số ban đầu? Trong trường hợp này, việc dự đoán chính xác mức giá không còn quan trọng nữa, mà hệ thống của bạn chỉ cần chọn đúng hạng mục. Khi đó, bài toán nên được xem là một bài toán phân loại, chứ không phải là bài toán hồi quy. Ta không muốn phát hiện ra điều này quá muộn sau khi đã dành nhiều tháng để xây dựng một hệ thống hồi quy.
May thay, sau khi nói chuyện với nhóm phụ trách hệ thống tiếp theo, bạn biết chắc rằng họ thực sự cần giá nhà ở dạng số, thay vì các hạng mục. Tuyệt! Bạn đã được bật đèn xanh và có thể bắt đầu lập trình ngay bây giờ!
Tải dữ liệu
Trong môi trường thông thường, dữ liệu sẽ được lưu trữ trong một cơ sở dữ liệu quan hệ (hoặc các kho chứa dữ liệu thông dụng khác) và có thể bao gồm nhiều bảng/tập tin/tài liệu. Để truy cập cơ sở dữ liệu này, ta cần có ủy nhiệm (credential) và quyền truy cập, rồi làm quen với định dạng dữ liệu. Tuy nhiên, trong dự án này, mọi thứ đơn giản hơn rất nhiều: ta chỉ cần tải xuống một tập tin nén,
housing.tgz, toàn bộ dữ liệu nằm trong tập tinhousing.csv, với các giá trị được ngăn cách bởi dấu phẩy (comma-separated values hay CSV).- Bạn có thể sử dụng trình duyệt web để tải xuống tập tin đó, chạy lệnh sau trên cửa sổ dòng lệnh để giải nén ra tập tin CSV:
1
tar xzf housing.tgz
- Tuy nhiên, lựa chọn phổ biến hơn là sử dụng một hàm nhỏ để làm việc này. Việc có một hàm tải dữ liệu về rất có lợi, đặc biệt là khi dữ liệu thay đổi thường xuyên. Ta có thể viết một đoạn mã ngắn dùng hàm này để lấy dữ liệu mới nhất (hoặc có thể tạo một tác vụ tự động lấy dữ liệu sau một khoảng thời gian nhất định). Việc tự động hóa quá trình lấy dữ liệu cũng cần thiết nếu ta cần cài đặt cùng một tập dữ liệu trên nhiều máy. Dưới đây là hàm để lấy dữ liệu:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import os
import tarfile
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/mlbvn/handson-ml2-vn/main/"
HOUSING_PATH = os.path.join("datasets", "housing") # Tạo đường dẫn datasets/housing
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path): # kiểm tra thư mục housing_path tồn tại chưa
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path) # tải file và lưu vào tgz_path
housing_tgz = tarfile.open(tgz_path) # mở file
housing_tgz.extractall(path=housing_path) # giải nén
housing_tgz.close() # đóng file
fetch_housing_data()
- Việc gọi hàm
fetch_housing_datasẽ tạo thư mụcdatasets/housingtrong không gian làm việc hiện tại, tải về tập tinhousing.tgz, và giải nén tập tinhousing.csvđến thư mục đó. - Giờ hãy sử dụng
pandasđể nạp dữ liệu. Tương tự, ta cũng nên viết một hàm nhỏ để làm điều này:
1
2
3
4
5
6
7
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
housing = load_housing_data()
print(housing.head())
- Hàm này trả về một đối tượng DataFrame của pandas chứa toàn bộ dữ liệu.
Nhìn qua cấu trúc dữ liệu
- Hãy cùng nhìn qua năm hàng đầu tiên của dữ liệu:
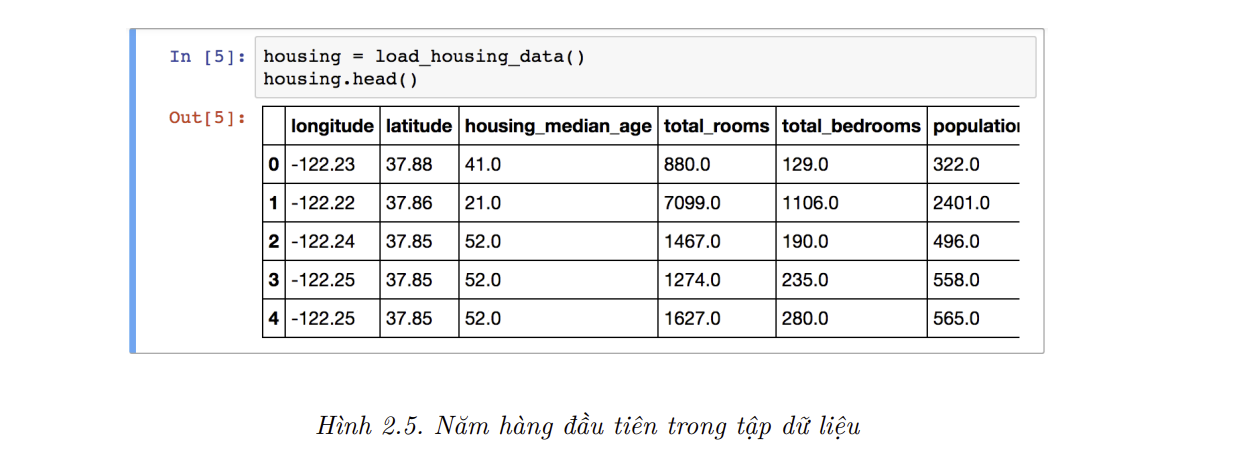
- Mỗi hàng biểu diễn một quân, và có 10 thuộc tính tất cả (ảnh trên chỉ hiện 6 thuộc tính):
longitude latitude,housing_median_age,total_rooms,total_bedrooms,population,households,median_income,median_house_value,ocean_proximity. - Phương thức
info()rất hữu dụng để xem các mô tả đơn giản về dữ liệu, như tổng số hàng, kiểu dữ liệu của mỗi thuộc tính, số lượng giá trị khác rỗng (xem ảnh dưới):
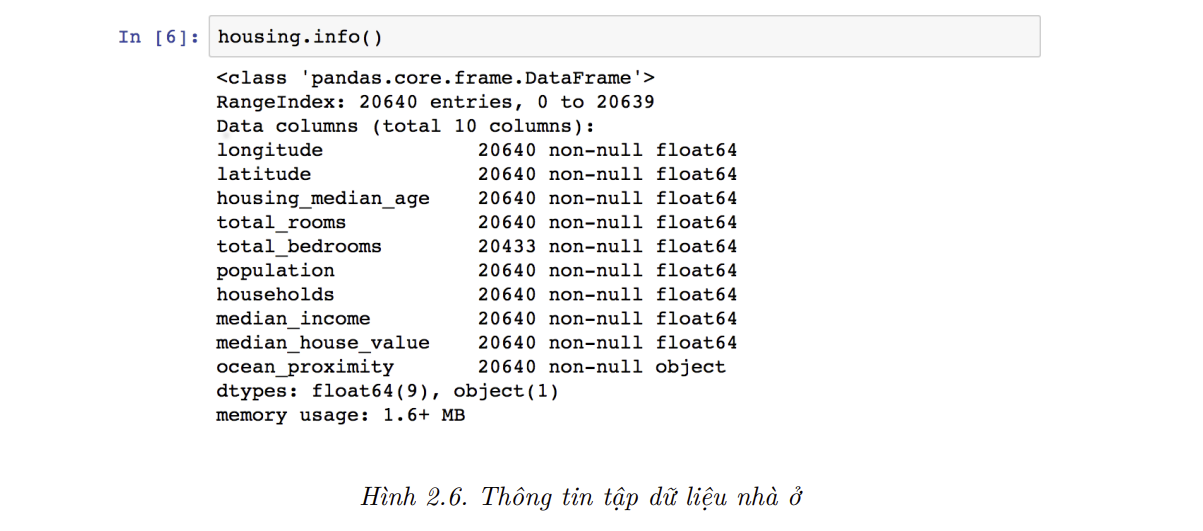
- Tập dữ liệu chứa tổng cộng 20640 mẫu này khá nhỏ theo tiêu chuẩn Học Máy, nhưng lại hoàn hảo cho dự án đầu tiên. Lưu ý rằng thuộc tính
total_bedroomschỉ có 20433 giá trị khác rỗng, đồng nghĩa là có 207 quận thiếu đặc trưng và ta sẽ phải giải quyết vấn đề này. - Tất cả thuộc tính là kiểu giá trị số, ngoại trừ thuộc tính
ocean_proximity. Kiểu dữ liệu của thuộc tính này làobject, tức nó có thể chứa bất kỳ đối tượng Python nào. Nhưng ta biết chắc rằng nó sẽ là một thuộc tính văn bản, vì dữ liệu được lấy từ một tệp CSV. Khi nhìn vào năm hàng đầu, ta thấy các giá trị trong cộtocean_proximityđược lặp đi lặp lại, đồng nghĩa với việc nó có thể là một thuộc tính hạng mục. Ta có thể biết tất cả các hạng mục cũng như số quận thuộc mỗi hạng mục bằng cách dùng hàmvalue_counts():

- Hãy xét thử các thuộc tính khác. Hàm
describe()cho biết thông tin tổng quan của các thuộc tính số:
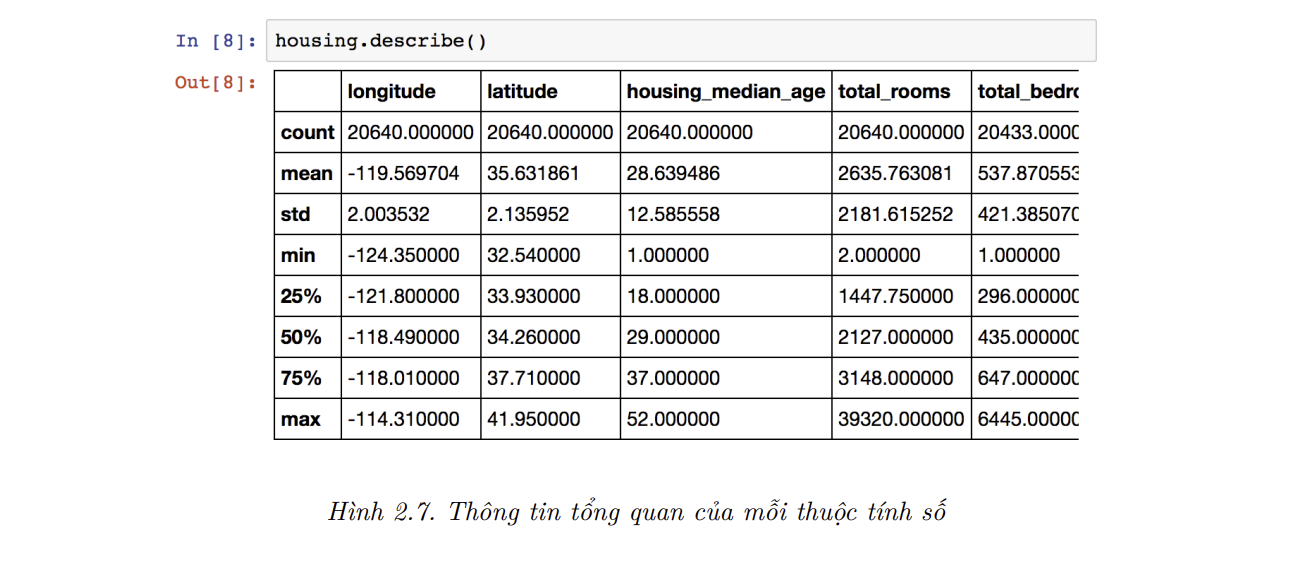
Ý nghĩa của các hàng
count,mean,min, vàmaxkhá là rõ ràng. Lưu ý rằng các giá trị rỗng được bỏ qua (ví dụ, ta thấy giá trịcountcủatotal_bedroomslà 20,433 thay vì 20,640). Dòngstdcho biết độ lệch chuẩn, một phép đo độ phân tán của giá trị.12 Các hàng 25%, 50%, và 75% cho biết các bách phân vị (percentile): tương tự với phần trăm số liệu có giá trị thấp hoặc cao hơn một mức ngưỡng cho trước. Ví dụ,housing_median_agecủa 25% các quận thấp hơn 18, trong khi đó 50% và 75% các quận cóhousing_median_agelần lượt thấp hơn 29 và 37. Chúng thường được gọi là bách phân vị thứ 25 (hay tứ phân vị –quartilethứ nhất), trung vị, và bách phân vị thứ 75 (hay tứ phân vị thứ ba).Ngoài ra, ta có thể vẽ biểu đồ tần suất cho mỗi thuộc tính số để nhanh chóng biết được dạng dữ liệu đang xử lý. Biểu đồ tần suất cho biết số mẫu (trên trục tung) nằm trong một khoảng giá trị nhất định (trên trục hoành). Ta có thể vẽ biểu đồ tần suất theo từng thuộc tính một, hoặc sử dụng phương thức hist() trên toàn bộ tập dữ liệu (như trong đoạn mã bên dưới) để vẽ biểu đồ tần suất cho mỗi thuộc tính số (xem Hình 2.8):
1
2
3
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()
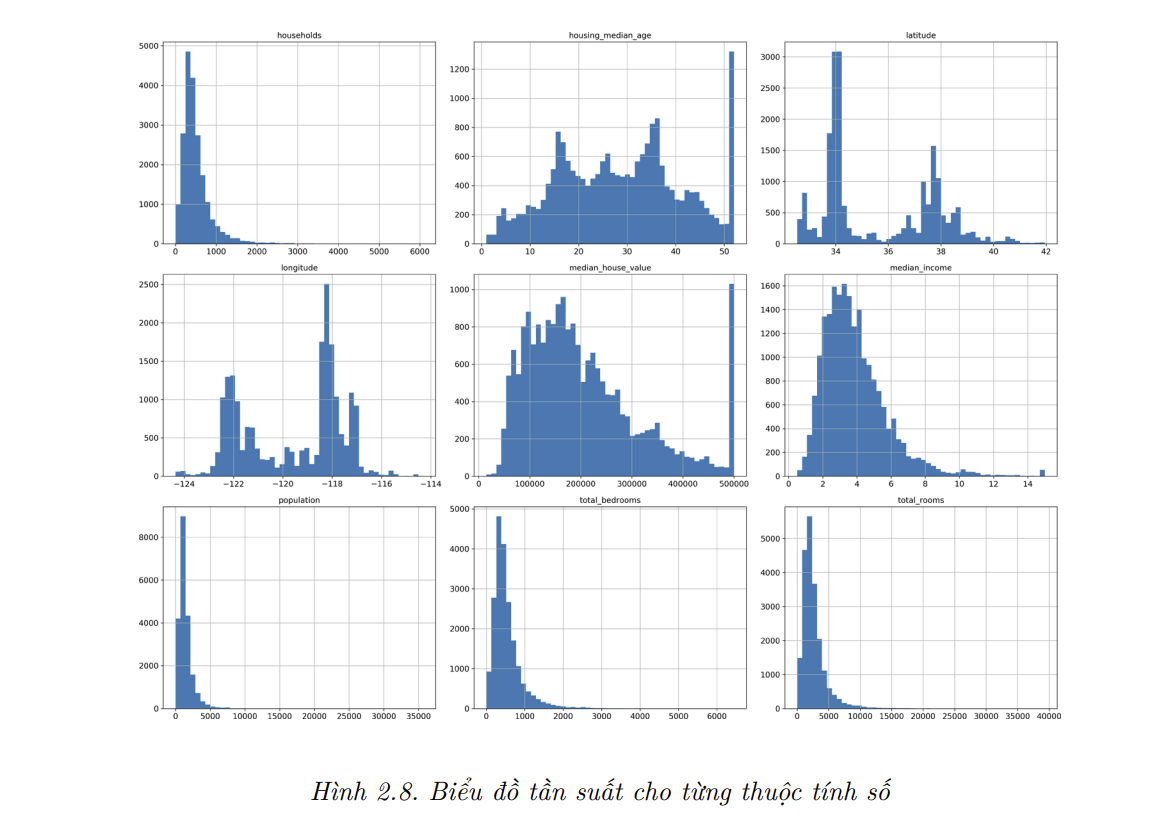
- Ta có thể nhận thấy một vài điều từ các biểu đồ này:
- Đầu tiên, dường như thuộc tính thu nhập trung vị không được biểu diễn bằng đơn vị đô-la Mỹ (USD). Sau khi hỏi lại nhóm thu thập dữ liệu, họ thông báo rằng dữ liệu đã được co giản xuống với mức trần tại 15 (chính xác là 15.0001) đối với các thu nhập trung vị cao hơn, và mức sàn tại 0.5 (chính xác là 0.4999) đối với các thu nhập trung vị thấp hơn. Các con số được tính theo mười ngàn đô-la (ví dụ, 3 thực tế có nghĩa là khoảng 30,000 đô-la). Làm việc với các thuộc tính đã được tiền xử lý là việc khá phổ biến trong Học Máy. Mặc dù đây không hẳn là vấn đề, nhưng bạn nên hiểu cách mà dữ liệu được xử lý.
- Tuổi đời trung vị và giá trị trung vị của ngôi nhà cũng được giới hạn. Việc giới hạn giá trị trung vị của ngôi nhà có thể là vấn đề nghiêm trọng vì đây là thuộc tính mục tiêu của bạn (nhãn muốn dự đoán). Thuật toán Học Máy có thể sẽ học được rằng giá cả sẽ không bao giờ vượt quá một giới hạn nhất định. Bạn cần phải kiểm tra với khách hàng (những người sẽ sử dụng hệ thống để dự đoán) để xem liệu đây có phải là một vấn đề không. Nếu khách hàng nói họ cần cả những dự đoán chính xác nằm ngoài khoảng 500,000 USD, thì bạn có thể sử dụng hai cách sau:
- Thu thập nhãn thích hợp cho các quận có nhãn bị giới hạn.
- Loại bỏ các quận đó ra khỏi tập huấn luyện (cũng như tập kiểm tra vì hệ thống của bạn không nên bị đánh giá tệ mỗi khi nó dự đoán giá trị trên ngưỡng 500,000 USD).
Các thuộc tính này có các khoảng giá trị rất khác nhau. Ta sẽ bàn luận về điều này ở blog khác về co giãn đặc trưng.
Cuối cùng, nhiều biểu đồ tần suất nặng đuôi (
tail-heavy): biểu đồ trải dài về bên phải trung vị hơn bên trái. Điều này sẽ khiến việc phát hiện khuôn mẫu trong một số thuật toán Học Máy gặp đôi chút khó khăn. Về sau, ta sẽ thử biến đổi phân phối của các thuộc tính này về dạng giống hình chuông hơn.
- Hy vọng rằng bây giờ bạn đã hiểu hơn về dạng dữ liệu mà mình đang xử lý.
📝 Note: Chờ đã! Trước khi xem xét thêm về dữ liệu, bạn cần tạo một tập dữ liệu kiểm tra, bỏ nó qua một bên, và không bao giờ động tới nó.
Tạo tập kiểm tra
Nghe có vẻ kỳ quặc nếu bây giờ ta tạm thời để một phần dữ liệu sang một bên. Cho tới hiện tại, ta chỉ mới nhìn qua dữ liệu, và chắc chắn rằng ta cần tìm hiểu thêm về dữ liệu trước khi quyết định sẽ sử dụng thuật toán nào. Tuy vậy, bộ não của chúng ta là một hệ thống phát hiện khuôn mẫu tuyệt vời, cũng có nghĩa là nó rất dễ quá khớp trên tập dữ liệu được quan sát: nếu nhìn vào tập kiểm tra, ta có thể gặp một vài khuôn mẫu thú vị trong tập kiểm tra, điều này khiến ta có thiên kiến lựa chọn một dạng mô hình Học Máy cụ thể. Khi đánh giá sai số khái quát trên tập kiểm tra, kết quả sẽ quá tốt. Do đó, ta sẽ đưa vào triển khai một hệ thống hoạt động tệ hơn mong đợi. Đây được gọi là thiên kiến dòm ngó dữ liệu (
data-snooping).Về lý thuyết, việc tạo một tập kiểm tra khá đơn giản: chọn ngẫu nhiên một vài mẫu, thường là 20% tập dữ liệu (hoặc ít hơn nếu tập dữ liệu có kích thước rất lớn), và để chúng sang một bên:
1
2
3
4
5
6
7
8
9
10
import numpy as np
def split_train_test(data, test_ratio):
shuffled_data = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_idx = shuffled_data[:test_set_size]
train_idx = shuffled_data[test_set_size:]
return data.iloc[train_idx], data.iloc[test_idx]
train_set, test_set = split_train_test(housing, 0.2)
- Cách này ổn, nhưng không hoàn hảo: nếu ta chạy lại chương trình, nó sẽ sinh ra một tập kiểm tra khác! Dần dần, bạn (hoặc thuật toán Học Máy) sẽ thấy được toàn bộ tập dữ liệu, và ta không muốn điều này xảy ra.
- Một giải pháp là lưu lại tập kiểm tra trong lần chạy đầu tiên và nạp nó trong các lần chạy tiếp theo. Một lựa chọn khác là đặt
seedcho bộ sinh số ngẫu nhiên (ví dụ, vớinp.random.seed(42)) trước khi họi hàmnp.random.permutation()để nó luôn sinh ra cùng một cách hoán đổi. - Tuy nhiên cả hai cách trên sẽ không hoạt động trong trường hợp tập dữ liệu được cập nhật. Để có một cách chia ổn định ngay cả trong trường hợp này, một giải pháp thông dụng là sử dụng ID của mỗi mẫu để quyết định xem liệu nó có thuộc dữ liệu kiểm tra hay không (giả sử các mẫu có một ID duy nhất và bất biến). Ví dụ, bạn có thể tính toán hash của ID mỗi mẫu và đưa mẫu đó vào tập kiểm tra nếu hash thấp hơn hoặc bằng 20% giá trị hash lớn nhất. Việc này sẽ đảm bảo rằng tập kiểm tra trong các lần chạy luôn đồng nhất, kể cả khi bạn cập nhật tập dữ liệu. Tập kiểm tra mới sẽ chứa 20% mẫu mới, nhưng nó sẽ không chứa bất kỳ mẫu nào trước đó thuộc về tập huấn luyện.
- Dưới đây là một cách lập trình khả thi:
1
2
3
4
5
6
7
8
9
10
from zlib import crc32
def test_set_check(identifier, test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32
def split_train_test_by_id(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio))
return data.loc[~in_test_set], data.loc[in_test_set]
- Không may, tập dữ liệu nhà ở không có cột ID. Cách đơn giản nhất là sử dụng chỉ số hàng làm ID:
1
2
housing_with_id = housing.reset_index() # adds an `index` column
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
- Nếu sử dụng chỉ số hàng làm ID duy nhất, ta cần đảm bảo rằng dữ liệu mới được nối vào cũ tập dữ liệu và không hàng nào bị xóa sau này. Nếu cách này không khả thi, ta có thể thử sử dụng đặc trưng ổn định nhất để tạo ID độc nhất. Ví dụ, kinh độ và vĩ độ của một quan điểm đảm bảo ổn định đến vài triệu năm, nên ta có thể kết hợp chúng lại thành một ID:
1
2
3
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
- Scikit-Learn cung cấp một vài hàm để chia một tập dữ liệu thành các tập dữ liệu con theo nhiều cách. Hàm đơn giản nhất là train_test_split, hoạt động giống với hàm split_train_test() với một vài chức năng bổ sung. Đầu tiên là tham số random_state cho phép ta đặt seed cho bộ sinh số ngẫu nhiên. Thứ hai, ta có thể truyền vào nhiều tập dữ liệu có cùng số hàng, và hàm này sẽ chia các tập dữ liệu theo cùng một cách (điều này rất hữu ích, ví dụ như khi bạn có một DataFrame riêng cho nhãn):
1
2
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size = 0.2, random_state = 42)
- Cho tới hiện tại, ta mới chỉ đơn thuần xem xét các phương pháp lấy mẫu ngẫu nhiên. Nhìn chung, các phương pháp này hoạt động ổn nếu tập dữ liệu đủ lớn (đặc biệt là so với số lượng thuộc tính), nhưng nếu không, ta sẽ đối mặt với rủi ro đáng kể về
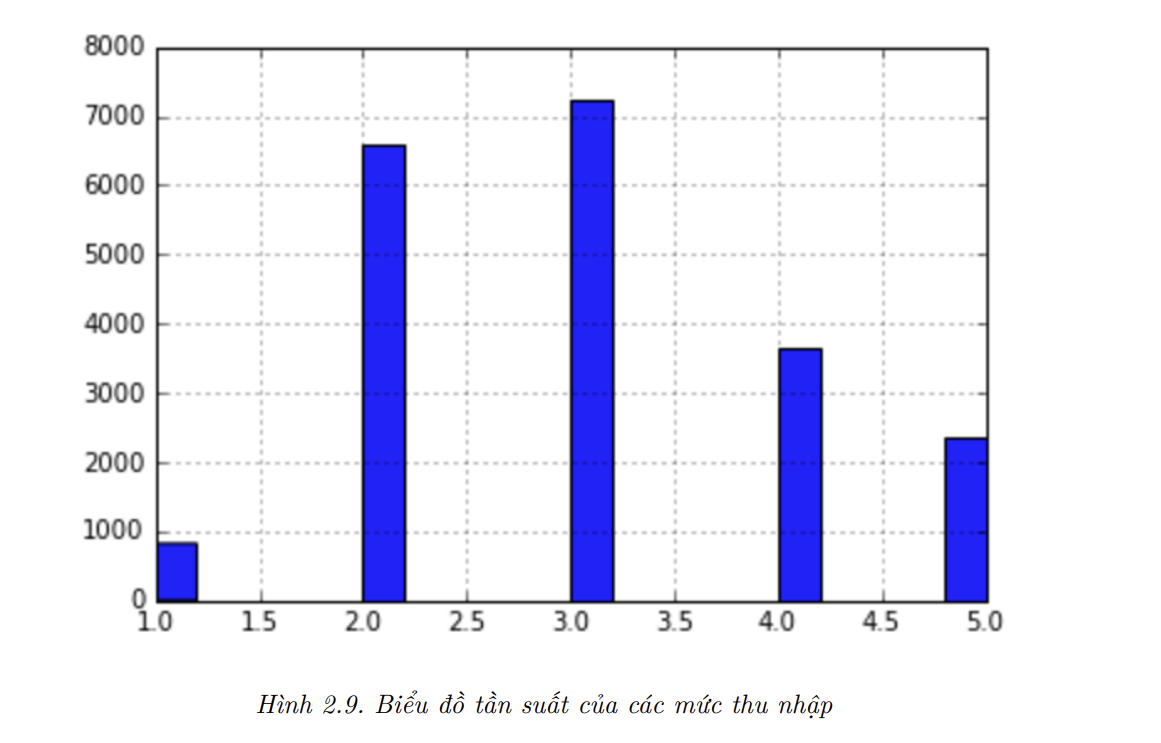
thiên kiến lấy mẫu. Khi một công ty làm khảo sát trên 1,000 người, họ không chỉ lấy ngẫu nhiên 1,000 người trong danh bạ. Họ cố gắng đảm bảo 1,000 người này đại diện cho toàn bộ dân số. Ví dụ, dân số nước Mỹ có 51.3% nữ và 48.7% nam, nên một cuộc khảo sát tốt ở Mỹ sẽ cố gắng duy trì tỷ lệ này khi lấy mẫu: 513 nữ và 487 nam. Cách lấy mẫu này được gọi là lấy mẫu phân tầng (stratified sampling): toàn bộ tổng thể được chia thành các nhóm con đồng nhất gọi làstratum, và một số lượng mẫu xác định được lấy từ mỗistratumđể đảm bảo tập dữ liệu kiểm tra có tính đại diện cho toàn bộ tổng thể. Nếu người làm khảo sát chỉ đơn thuần lấy mẫu ngẫu nhiên, sẽ có 12% khả năng phân phối của tập dữ liệu kiểm tra bị lệch, tức hoặc ít hơn 49% nam hoặc nhiều hơn 54% nữ. Dù là trường hợp nào, kết quả khảo sát sẽ bị thiên kiến đáng kể. - Giả sử sau khi thảo luận với chuyên gia, ta biết rằng thu nhập trung vị là một thuộc tính rất quan trọng để dự đoán giá nhà trung vị. Ta cần đảm bảo rằng tập kiểm tra mang tính đại diện cho tất cả các mức thu nhập trong toàn bộ tập dữ liệu. Vì thu nhập trung vị là một thuộc tính liên tục, đầu tiên ta cần tạo thuộc tính hạng để biểu diễn các mức thu nhập khác nhau. Hãy quan sát biểu đồ tần suất kỳ vọng (trong Hình 2.8): phần lớn các giá trị thu nhập trung vị được phân bố trong khoảng từ 1.5 đến 6 (tức 15,000 USD - 60,000 USD), nhưng có vài giá trị vượt quá 6. Việc có đủ mẫu trong tập dữ liệu cho mỗi stratum là rất quan trọng. Nếu không, việc ước lượng độ quan trọng của một stratum sẽ bị thiên kiến. Nghĩa là, không nên có quá nhiều stratum, và mỗi stratum nên đủ lớn. Đoạn mã dưới đây sử dụng hàm pd.cut() để tạo thuộc tính mức thu nhập theo năm mức (gán nhãn từ 1 đến 5): mức 1 từ 0 đến 1.5 (tức dưới 15,000 USD), mức 2 từ 1.5 đến 3, v.v.
1
2
3
4
housing["income_cat"] = pd.cut(housing["median_income"],
bins=[0., 1.5, 3.0, 4.5, 6., np.inf],
labels=[1, 2, 3, 4, 5])
housing["income_cat"].hist()
- Bây giờ, ta đã sẵn sàng lấy mẫu
stratifieddựa trên các mức thu nhập. Để thực hiện việc này, ta có thể sử dụng lớpStratifiedShuffleSplitcủa Scikit-learn:
1
2
3
4
5
6
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) # n_splits là số lần trộn
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
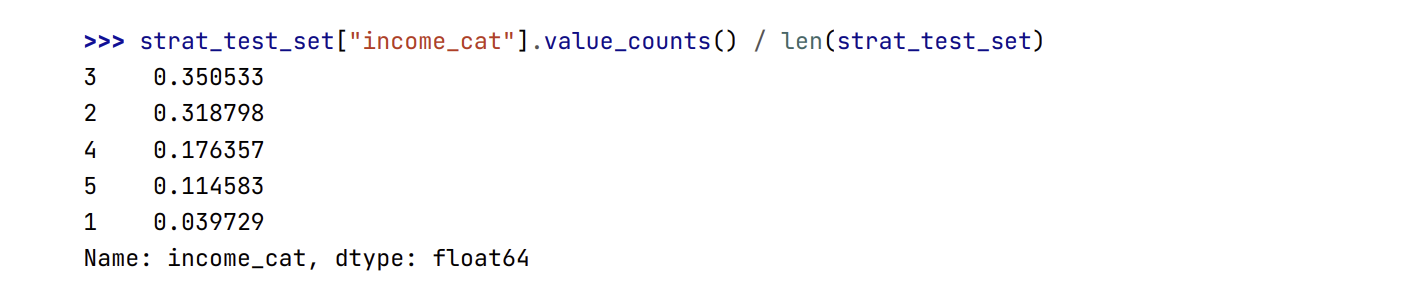
- Hãy kiểm tra xem đoạn mã có hoạt động đúng không, bắt đầu bằng việc quan sát tỷ lệ phần trăm các mức thu nhập trong tập kiểm tra:
1
strat_test_set["income_cat"].value_counts() / len(strat_test_set)
- Tương tự, ta có thể đo lường tỷ lệ phần trăm của các mức thu nhập trong toàn bộ tập dữ liệu. Hình 2.10 so sánh tỷ lệ phần trăm của các mức thu nhập trong toàn bộ dữ liệu và trong tập dữ liệu kiểm tra được tạo ra bởi lấy mẫu
stratifiedvà lấy mẫu ngẫu nhiên. Có thể thấy, lấy mẫustratifiedtạo ra tập dữ liệu kiểm tra có tỷ lệ các mức thu nhập khá giống với tỷ lệ trong tập dữ liệu gốc, trong khi phân phối của tập dữ liệu lấy mẫu ngẫu nhiên bị lệch:
1
2
3
4
5
6
7
8
9
10
11
12
def income_cat_proportions(data):
return data["income_cat"].value_counts() / len(data)
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
compare_props = pd.DataFrame({
"Overall": income_cat_proportions(housing),
"Stratified": income_cat_proportions(strat_test_set),
"Random": income_cat_proportions(test_set),
}).sort_index()
compare_props["Rand. %error"] = 100 * compare_props["Random"] / compare_props["Overall"] - 100
compare_props["Strat. %error"] = 100 * compare_props["Stratified"] / compare_props["Overall"] - 100
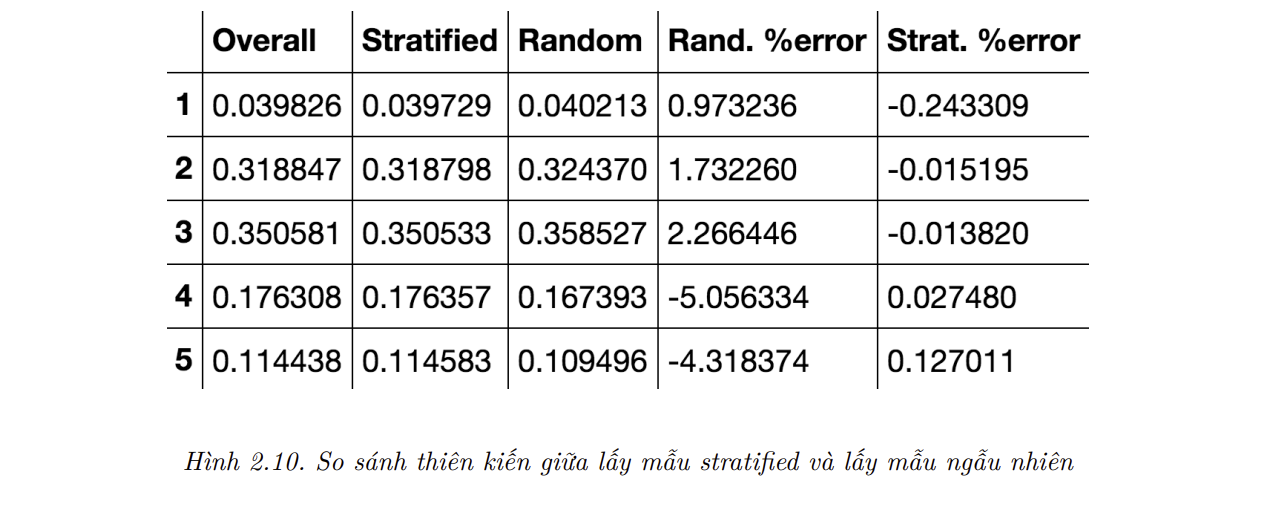
- Giờ ta có thể loại bỏ thuộc tính income_cat để dữ liệu trở về trạng thái ban đầu:
1
2
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)
- Việc ta dành khá nhiều thời gian để sinh tập dữ liệu kiểm tra là có lý do: điều này thường bị bỏ qua nhưng lại là phần cực kỳ quan trọng trong một dự án Học Máy. Hơn nữa, nhiều ý tưởng trình bày ở trên sẽ hữu ích khi thảo luận về
kiểm định chéo(cross-validation). Giờ là lúc chuyển sang bước tiếp theo: khám phá dữ liệu
3. Khám phá và trực quan hóa để hiểu dữ liệu
Cho tới nay ta mới chỉ nhìn lướt qua dữ liệu để nắm được các đặc điểm chung của chúng. Bây giờ mục tiêu của ta là đi sâu hơn một chút.
Đầu tiên, hãy đảm bảo rằng ta không động vào tập kiểm tra và chỉ sử dụng tập huấn luyện. Ngoài ra, nếu tập huấn luyện rất lớn, ta có thể chỉ lấy ra một tập nhỏ để việc thao tác dễ và nhanh hơn. Trong trường hợp này, tập huấn luyện tương đối nhỏ, nên ta có thể làm việc trực tiếp trên toàn bộ tập. Hãy tạo một bản sao để yên tâm rằng ta không làm ảnh hưởng đến tập huấn luyện gốc:
1
housing = strat_train_set.copy()
Trực quan hóa Dữ liệu Địa lý
- Vì dữ liệu có các thông tin về địa lý (kinh độ và vĩ độ), ta nên tạo một biểu đồ phân tán (
scatterplot) của tất cả các quan sát để trực quan hóa dữ liệu (Hình 2.11):
1
housing.plot(kind="scatter", x="longitude", y="latitude")
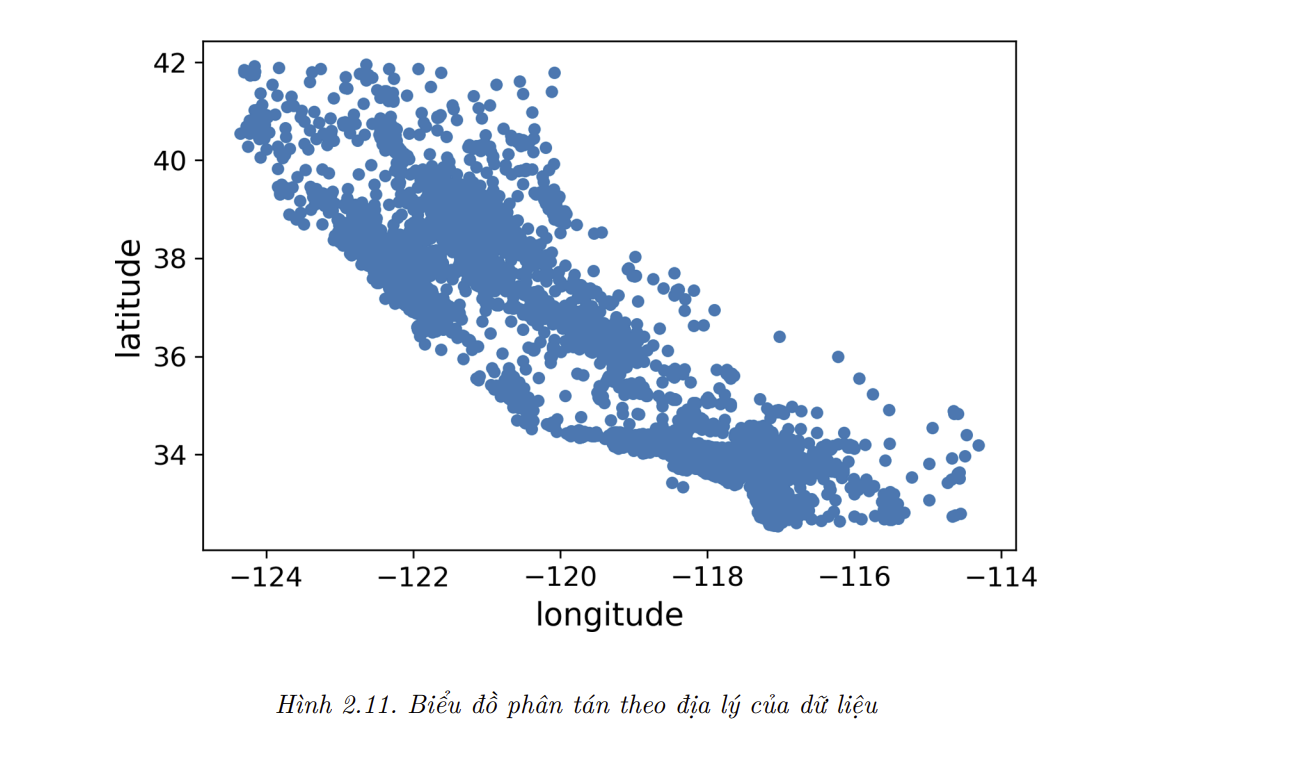
- Biểu đồ này nhìn khá giống hình dáng bang California, nhưng ngoài điều đó ra thì rất khó để thấy được khuôn mẫu cụ thể nào. Việc đặt alpha bằng 0.1 sẽ giúp minh họa tốt hơn các vùng có mật độ điểm dữ liệu lớn (Hình 2.12):
1
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
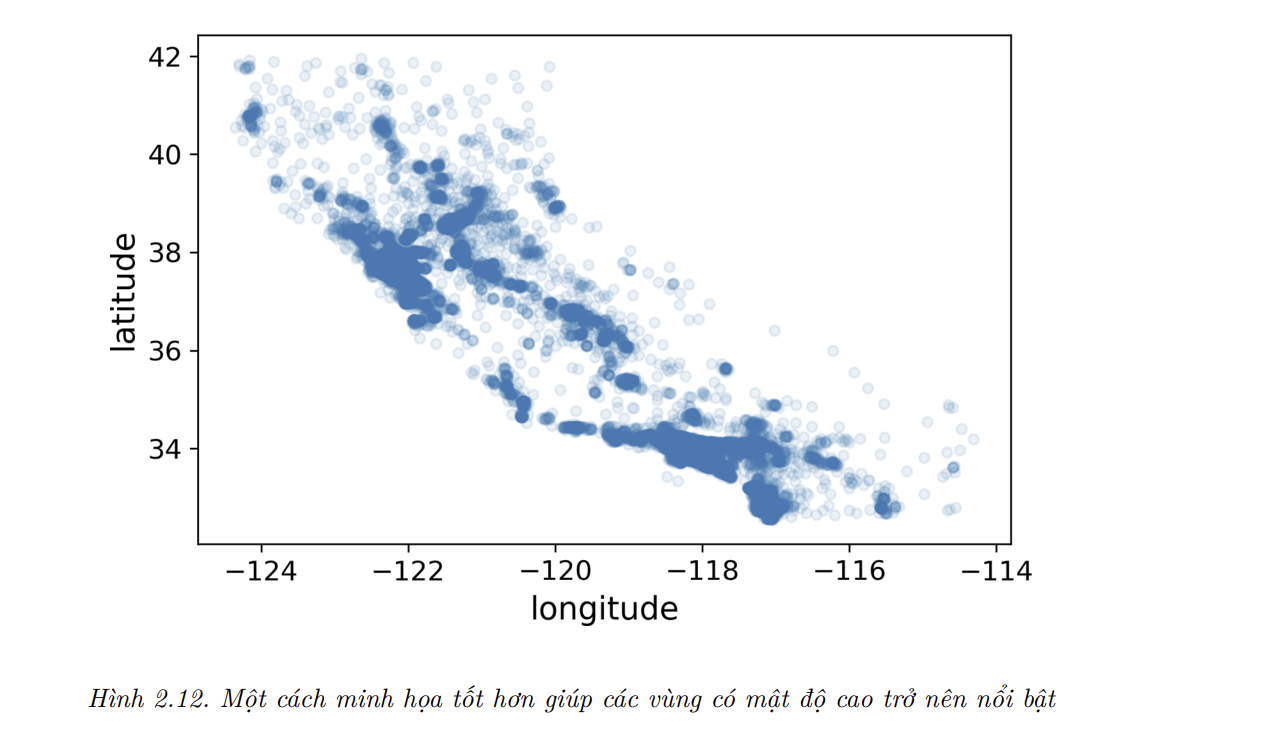
Lúc này ta đã có thể thấy rõ các khu vực đông dân, củ thể là Bay Area, xung quanh Los Angeles và San Diego, cộng với một dải dài đông đúc ở Central Valley, đặc biệt là quanh Sacramento và Fresno.
Giờ hãy nhìn vào giá nhà (Hình 2.13). Bán kính mỗi vòng tròn đại diện cho dân số của quận (đối số
s), và màu sắc đại diện cho mức giá (đối sốc). Ta sẽ sử dụng một bảng màu định nghĩa sẵn (đối sốcmap) có tên làjet, có dải màu từ xanh (giá thấp) đến đỏ (giá cao):
1
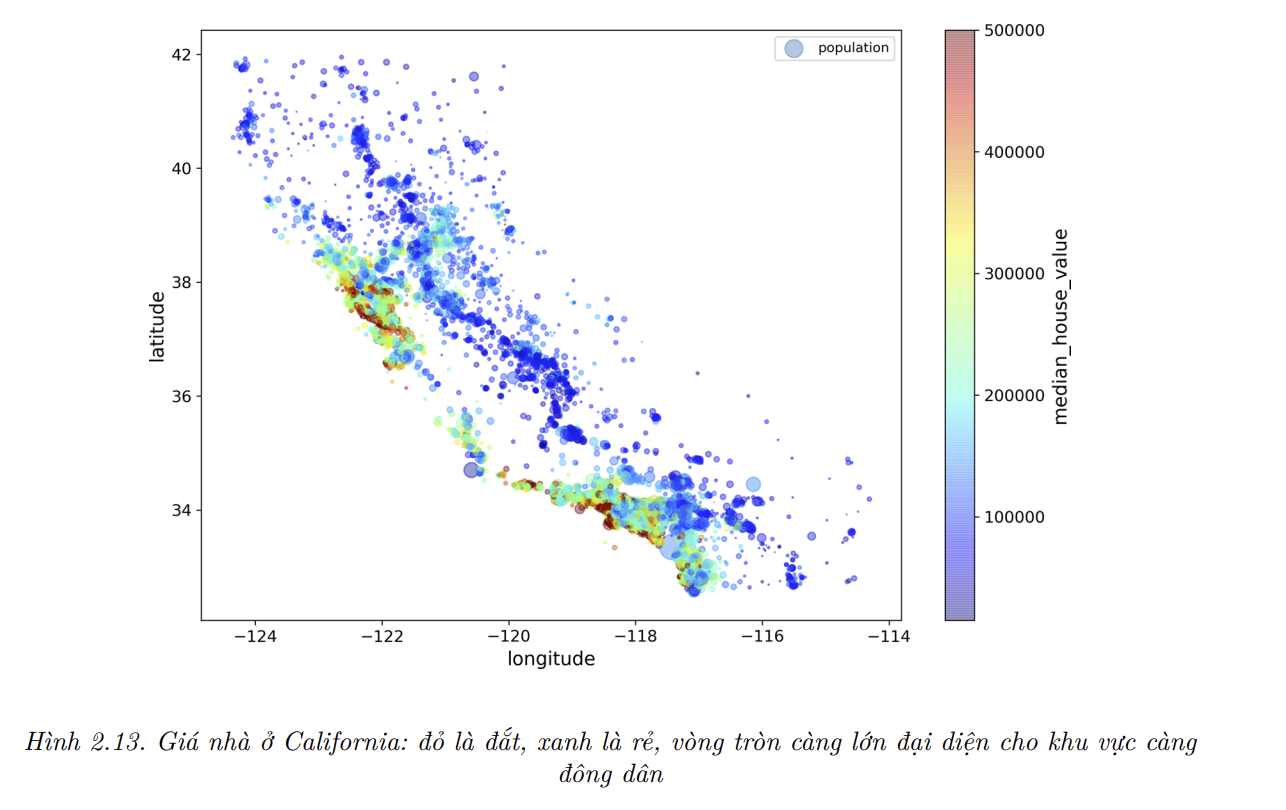
- Hình ảnh này cho thấy giá nhà liên quan mật thiết đến vị trí (như gần biển) và mật độ dân số, như bạn có thể đã biết. Một thuật toán phân cụm thường sẽ hữu ích trong việc phát hiện các cụm chính, từ đó giúp bổ sung thêm các đặc trưng mới là khoảng cách từ mẫu đến các tâm cụm. Khoảng cách đến biển cũng có thể là một thuộc tính hữu ích, tuy vậy ở Bắc California giá nhà ở các quận vùng vịnh lại không quá cao, vì thế đây không phải là một quy tắc đơn giản.
Tìm sự tương quan
- Vì tập dữ liệu không quá lớn, ta có thể dễ dàng tính dược hệ số tương quan chuẩn (
standard corelation coefficient, còn được gọi là hệ số tương quanPearson r) giữa các cặp thuộc tính bằng phương thứccorr():
1
2
housing = housing.drop(columns=['ocean_proximity'])
corr_matrix = housing.corr()
- Giờ hãy cùng xem tính tương quan của từng thuộc tính dữ liệu với nhà trung vị:
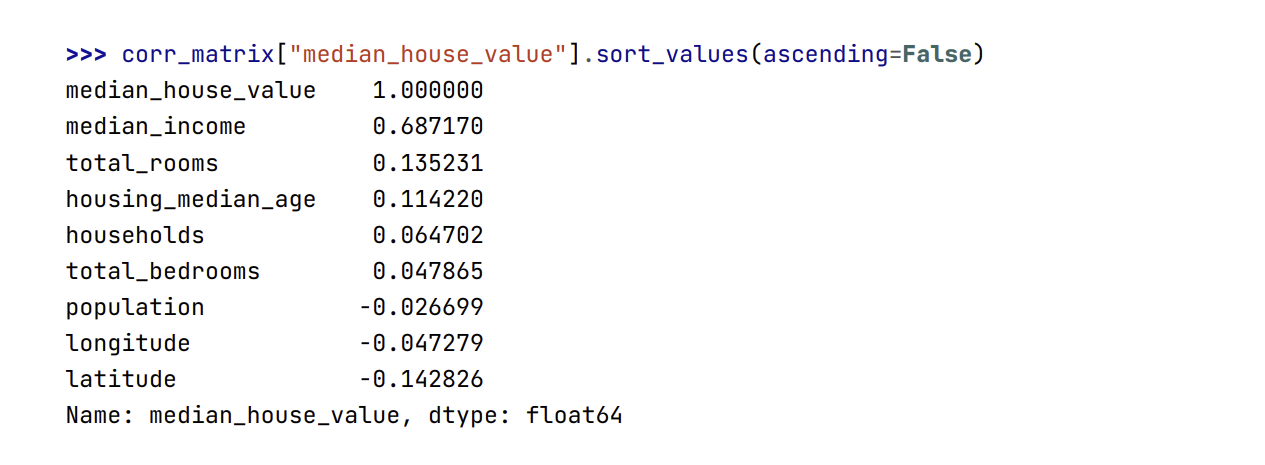
- Hệ số tương quan nằm trong khoảng từ −1 đến 1. Càng gần 1, mức tương quan càng dương; ví dụ, giá nhà trung vị có xu hướng tăng khi thu nhập trung vị tăng. Ngược lại, càng gần −1, mức tương quan càng âm; ta có thể thấy một sự tương quan âm nhỏ giữa vĩ độ và giá nhà trung vị (tức giá nhà hơi có xu hướng giảm dần khi đi lên phía Bắc). Cuối cùng, hệ số tương quan gần 0 nghĩa là không có sự tương quan tuyến tính nào.
📝 Note: Hệ số tương quan chỉ đo lường sự tương quan tuyến tính (“nếu x tăng thì y nhìn chung sẽ tăng hoặc giảm”). Nó có thể hoàn toàn bỏ qua các quan hệ phi tuyến trong dữ liệu (ví dụ, “nếu x gần 0 thì y tăng”). Hãy để ý rằng tất cả các đồ thị ở hàng dưới cùng đều có hệ số tương quan bằng 0, dù các trục tọa độ rõ ràng không độc lập với nhau: đây là các ví dụ về quan hệ phi tuyến. Thêm vào đó, trong hàng thứ hai, hệ số tương quan bằng 1 hoặc −1. Chú ý rằng điều này không liên quan gì đến độ dốc. Vì vậy, chiều cao của bạn tính bằng inch vẫn có hệ số tương quan bằng 1 với chiều cao của bạn tính bằng mét hoặc nano-mét.
- Một cách khác để kiểm tra mối quan hệ tương quan giữa các thuộc tính là sử dụng hàm
scatter_matrix()của pandas để vẽ đồ thị biểu diễn mối quan hệ giữa các thuộc tính so với nhau. Vì giờ có 11 thuộc tính, nên ta sẽ có $11^2 = 121$ đồ thị. Vì chúng không nằm vừa trong một blog nên hãy chỉ tập trung vào một vài thuộc tính hứa hẹn sẽ có tương quan cao với giá nhà trung vị:
1
2
3
4
5
6
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))
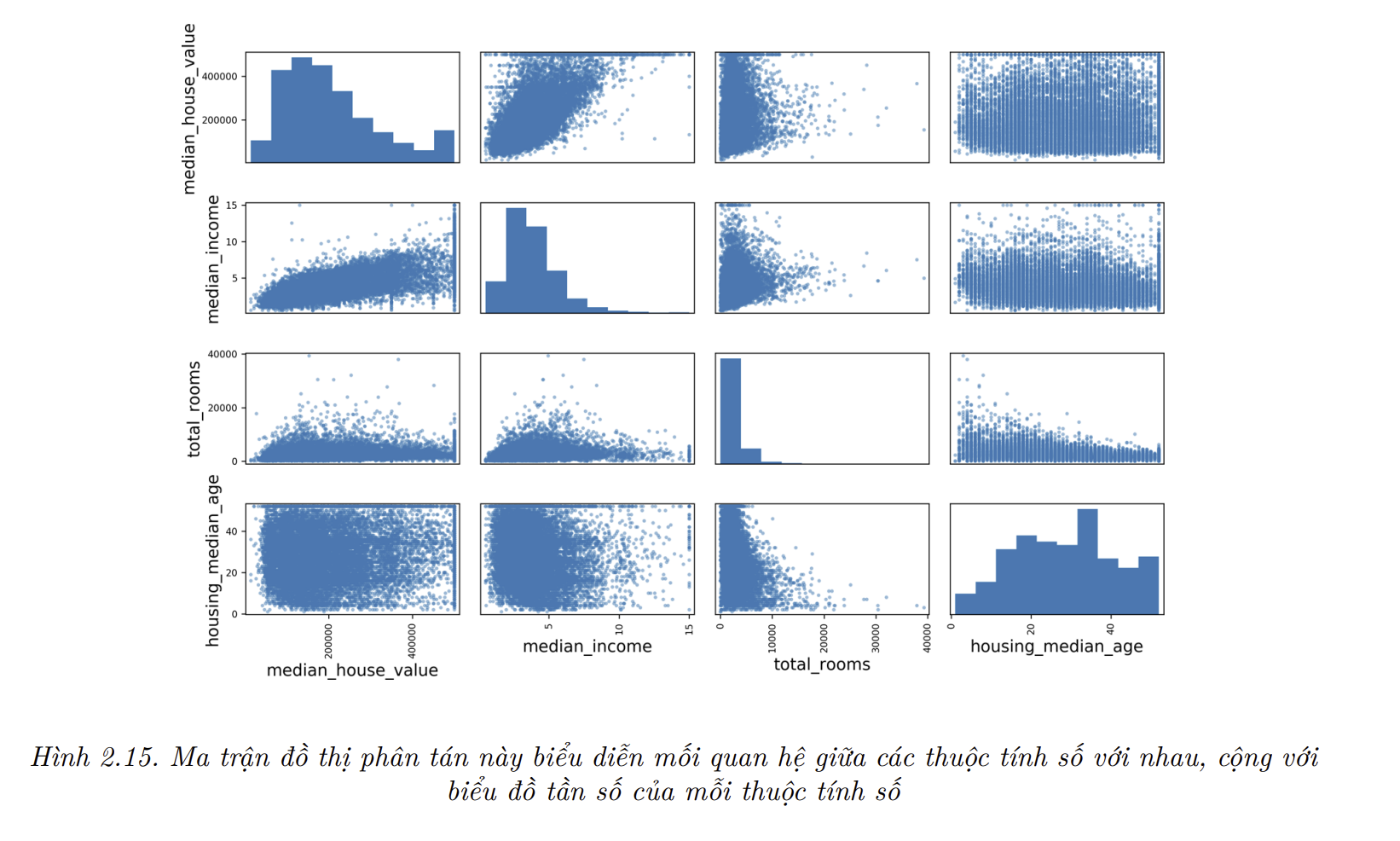
- Đường chéo chính sẽ đều là các đường thẳng nếu
pandasvẽ quan hệ từng biến đối với chính biến đó, và điều này không hữu ích cho lắm. Nên thay vào đó, pandas vẽ biểu đồ của từng thuộc tính. Thuộc tính có hứa hẹn nhất để dự đoán giá nhà trung vị là thu nhập trung vị, nên hãy phóng to đồ thị phân tác tương quan của chúng (Hình 2.16):
1
2
3
housing.plot(kind="scatter", x="median_income", y="median_house_value",
alpha=0.1)
plt.axis([0, 16, 0, 550000])
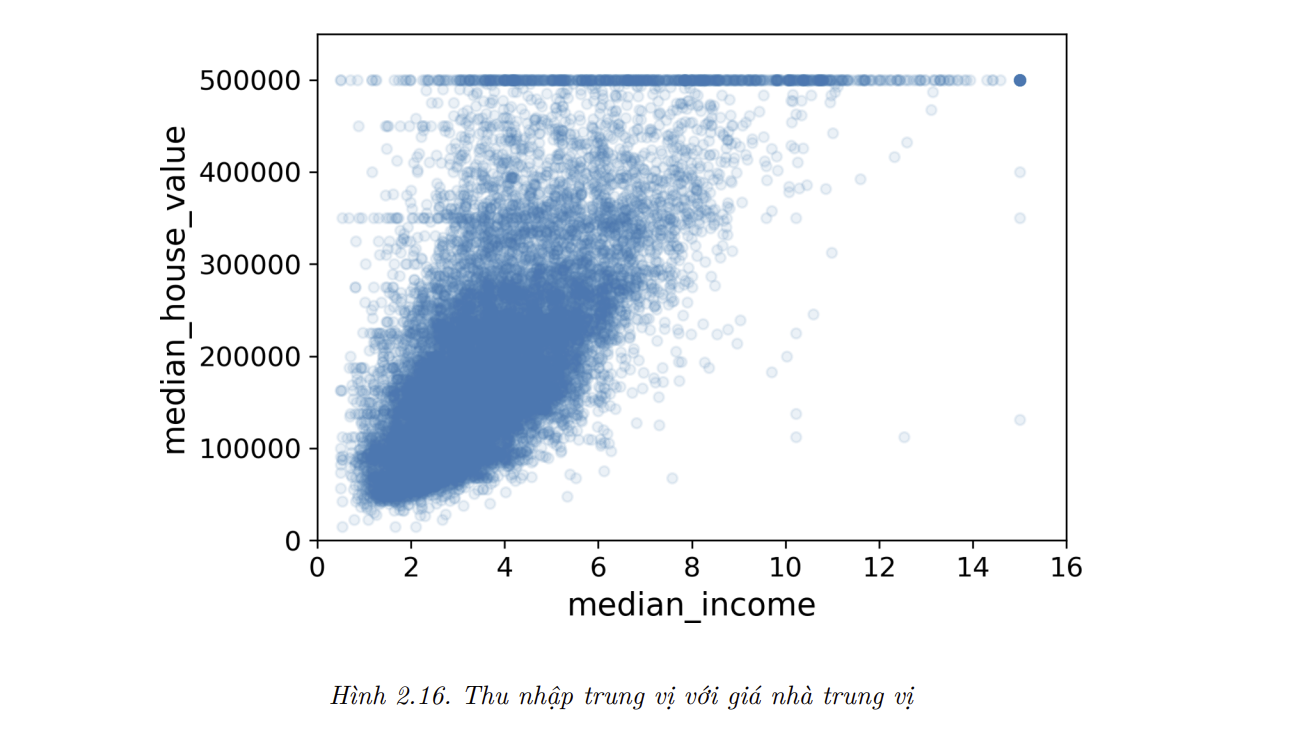
- Biểu đồ này nói lên vài điều. Đầu tiên, sự tương quan thật sự rất mạnh. Bạn có thể thấy rõ xu hướng đi lên trong khi các điểm dữ liệu thì không quá phân tán. Thứ hai, mức giá trần chúng ta thấy trước đó đã được biểu thị rõ ràng bằng một đường ngang tại 500,000 USD. Tuy nhiên, biểu đồ này cũng tiết lộ một vài đường ngang khó nhận thấy ngay: một đường quanh 450,000 USD, một đường khác ở khoảng 350,000 USD, một đường khác ở khoảng 280,000 USD, và một vài đường phía dưới nữa. Bạn có thể thử loại bỏ các quận tương ứng để ngăn thuật toán tái tạo lại những khuôn mẫu kì lạ này trong quá trình học.
Thí nghiệm Kết hợp các Thuộc tính
- Hy vọng rằng các mục trước đã giúp bạn nắm được một vài cách thức khám phá và hiểu dữ liệu. Bạn đã nhận thấy vài điểm kì lạ trong dữ liệu mà bạn muốn loại bỏ trước khi đưa vào các thuật toán Học Máy, cũng như tìm thấy các mối tương quan thú vị giữa các thuộc tính, đặc biệt là với thuộc tính mục tiêu. Bạn cũng nhận ra một vài thuộc tính có phân phối nặng đuôi (
tail-heavy distribution) và muốn biến đổi chúng (ví dụ như dùng hàm logarit). Tất nhiên, cách mỗi người xử lý sẽ thay đổi nhiều tùy theo nội dung, nhưng ý tưởng tương quan là như nhau. - Điều cuối cùng bạn có thể muốn làm trước khi chuẩn bị dữ liệu cho các thuật toán Học Máy là thử nghiệm bằng cách kết hợp các thuộc tính. Ví dụ như việc biết tổng số phòng sẽ có thể bổ sung một chút thông tin, nhưng nó có thể bổ sung bao nhiêu khi giá đình trung bình có 4 phòng? Thứ ta muốn là số phòng của mỗi hộ. Tương tự, bản thân thông tin tổng số phòng ngủ cũng không hữu ích cho lắm: ta có thể muốn nhìn nó về tổng số phòng. Ngoài ra số người trong mỗi gia đình có thể là một thuộc tính kết hợp thú vị. Hãy cùng tạo ra các thuộc tính mới này:
1
2
3
4
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
- Và giờ hãy nhìn lại ma trận tương quan:
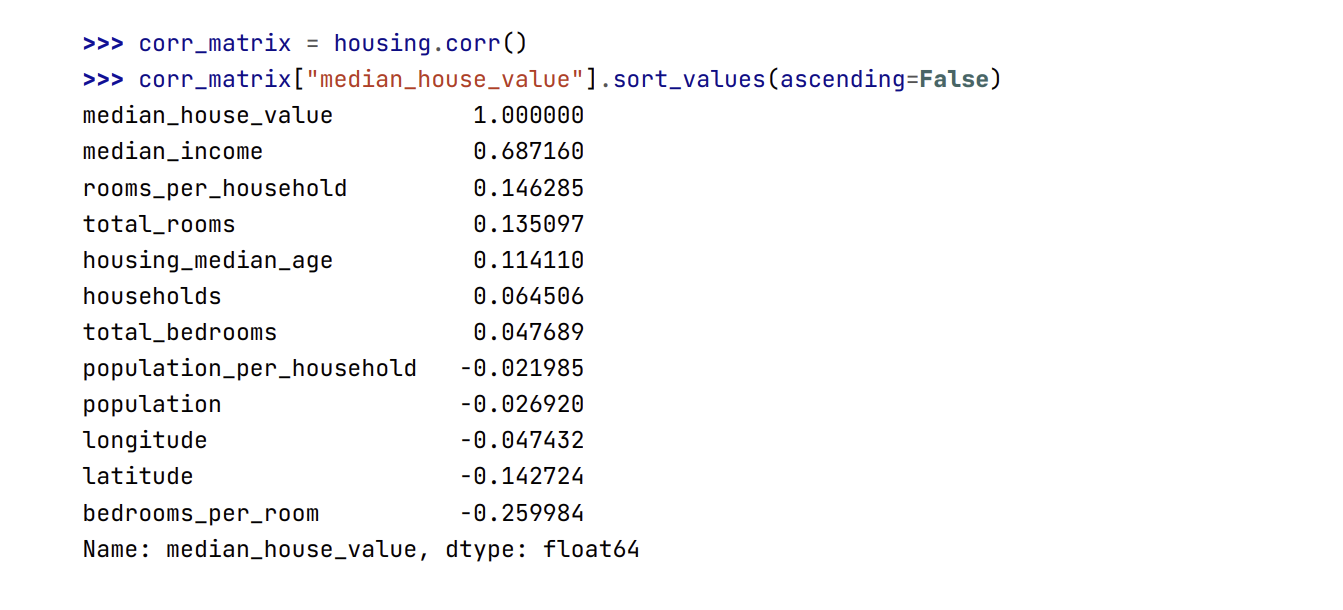
- Kết quả không tệ ! Thuộc tính mới
bedrooms_per_roomcó độ tương quan với giá nhà trung vị lớn hơn hẳntotal_roomshaytotal_bedrooms. Rõ ràng các ngôi nhà với tỉ lệ phòng ngủ/số phòng nhỏ hơn thường có xu hướng đắt hơn. Số phòng mỗi nhà rooms_per_household cũng mang nhiều thông tin hơn tổng số phòngtotal_roomstrong một quận, vì rõ ràng nhà càng lớn càng đắt. Việc kết hợp thuộc tính khi khám phá dữ liệu lần đầu không cần phải tuyệt đối tỉ mỉ. Ta chỉ cần có một khởi đầu tốt và nhanh chóng hiểu dữ liệu, để từ đó phát triển nguyên mẫu đầu tiên tương đối tốt. Nhưng đây là một quá trình lặp lại: khi đã có một nguyên mẫu, ta có thể phân tích đầu ra của nó để có nhiều thông tin hơn và quay lại bước khám phá này.
4. Chuẩn bị Dữ liệu cho các Thuật toán Học Máy
- Giờ là lúc chuẩn bị dữ liệu cho các thuật toán Học Máy. Thay vì thực hiện việc này thủ công, ta nên viết các hàm để làm điều đó, vì:
- Việc này cho phép ta áp dụng các phép biến đổi dễ dàng trên bất cứ tập dữ liệu nào (ví dụ khi ta có dữ liệu mới).
- Ta sẽ dần dần xây dựng một thư viện các hàm biến đổi để tái sử dụng trong tương lai.
- Ta có thể dùng các hàm này trong hệ thống thực để biến đổi dữ liệu mới trước khi đưa vào thuật toán.
- Ta có thể dễ dàng thử nhiều phép biến đổi và xem tổ hợp nào hoạt động tốt nhất.
- Nhưng trước hết, hãy quay lại với tập huấn luyện ban đầu (bằng cách sao chép
strat_train_setmột lần nữa). Cùng với đó, hãy tách các thuộc tính và nhãn, vì ta không nhất thiết muốn áp dụng cùng các phép biến đổi lên cả hai (chú ý rằng phương thứcdrop()tạo một bản sao của dữ liệu và không làm ảnh hưởng tớistrat_train_set):
1
2
3
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()
Làm sạch Dữ liệu
- Đa phần các thuật toán Học Máy không thể làm việc với các đặc trưng bị thiếu nên hãy viết một vài hàm xử lý vấn đề này. Trước đó ta đã thấy thuộc tính total_bedrooms có một vài giá trị bị thiếu, nên hãy xử lý nó. Ta có ba lựa chọn:
- Loại bỏ các quận tương ứng.
- Loại bỏ toàn bộ thuộc tính.
- Gán một giá trị nào đó (0, trung bình, trung vị, v.v.).
- Ta có thể thực hiện những việc này dễ dàng bằng các phương thức
dropna(),drop(), vàfillna()của DataFrame:
1
2
3
4
housing.dropna(subset=["total_bedrooms"]) # option 1
housing.drop("total_bedrooms", axis=1) # option 2
median = housing["total_bedrooms"].median() # option 3
housing["total_bedrooms"].fillna(median, inplace=True)
- Hãy tạo một bản sao của tập dữ liệu nhà ở, nhưng chỉ giữ lại các hàng chứa ít nhất một giá trị rỗng. Sau đó, sẽ dễ dàng hơn để hình dung chính xác những gì mỗi tùy chọn làm:
1
2
sample_incomplete_rows = housing[housing.isnull().any(axis=1)].head()
sample_incomplete_rows
- Ta sẽ thử cách 1 là loại bỏ các hàng chứa ít nhất một giá rỗng:
1
2
sample_incomplete_rows = sample_incomplete_rows.dropna(subset=["total_bedrooms"])
sample_incomplete_rows
- Ta sẽ thử cách 2 là loại bỏ luôn cột thuộc tính chứa giá trị rỗng:
1
2
sample_incomplete_rows = sample_incomplete_rows.drop("total_bedrooms", axis=1)
sample_incomplete_rows
- Ta sẽ thử cách 3 là thay thế các ô rỗng bằng giá trị
median:
1
2
3
median = housing["total_bedrooms"].median()
sample_incomplete_rows["total_bedrooms"].fillna(median, inplace=True) # option 3
sample_incomplete_rows
- Nếu chọn cách thứ 3, ta nên tính giá trị trung vị trên tập huấn luyện và dùng nó để gán cho các giá trị bị thiếu trong tập huấn luyện. Đừng quên lưu giá trị trung vị này, vì ta sẽ cần đến nó khi đánh giá và triển khai hệ thống thực để thay thế các giá trị bị thiếu trong tapajkiemer tra và trong dữ liệu mới.
Scikit-Learncung cấp một lớp hữu ích để xử lý giá trị bị thiếu:SimpleImputer. Để sử dụng nó, đầu tiên ta cần tạo một thực thể của lớpSimpleImputervà chỉ định rằng ta muốn thay các giá trị thiếu bằng trung vị của thuộc tính:
1
2
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy = "median")
- Vì trung vị chỉ có thể được tính cho các thuộc tính số, ta cần tạo bản sao của dữ liệu không chứa thuộc tính văn bản
ocean_proximity:
1
housing_num = housing.drop("ocean_proximity", axis = 1)
- Giờ ta có thể khớp thực thể
imputervới dữ liệu bằng phương thứcfit():
1
imputer.fit(housing_num)
- Thực thể
imputerchỉ đơn thuần tính trung vị của các thuộc tính và lưu kết quả vào biến thực thểstatistics_của nó. Hiện chỉ duy nhất thuộc tínhtotal_bedroomscó giá trị thiếu, nhưng ta không thể đảm bảo sẽ không có giá trị thiếu trong dữ liệu mới khi triển khai hệ thống, nên sẽ an toàn hơn nếu áp dụngimputercho tất cả các thuộc tính số:

- Giờ ta có thể dùng thực thể
imputernày để biến đổi tập huấn luyện bằng cấc thay thế dữ liệu thiếu bằng trung vị đã tính được:
1
X = imputer.transform(housing_num)
- Kết quả là một mảng
Numpythuần chứa các đặc trưng đã được biến đổi. Nếu ta muốn chuyển nó về dạngDataFramecủapandas, chỉ cần:
1
2
3
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index=housing.index)
housing_tr.loc[sample_incomplete_rows.index.values]
Xử lý các thuộc tính văn bản và hạng mục
- Cho đến nay chúng ta chỉ mới làm việc với các thuộc tính số, nên tiếp theo hãy cùng xem xét các thuộc tính văn bản. Trong tập dữ liệu này chỉ có một thuộc tính như vậy:
ocean_proximity. Hãy nhìn qua các giá trị của 10 mẫu đầu tiên:

Đây không phải là kiểu dữ liệu văn bản tùy ý: chỉ có một số lượng giới hạn các giá trị khả dụng, mỗi giá trị biểu diễn một hạng mục. Vì vậy thuộc tính này là thuộc tính hạng mục. Phần lớn các thuật toán Học Máy thích làm việc với các con số hơn, vậy nên hãy chuyển đổi các hạng mục này từ dạng văn bản sang dạng số. Để làm điều này, ta có thể sử dụng lớp OrdinalEncoder của Scikit-Learn:

- Ta có thể trích xuất danh sách hạng mục bằng thuộc tính
categories_. Đây là danh sách gồm các mảng một chiều chứa hạng mục tương ứng với mỗi thuộc tính hạng mục (trong trường hợp nà danh sách chỉ chứa một mảng vì chỉ có một thuộc tính hạng mục).

- Một số vấn đề với cách biểu diễn này là các thuật toán Học Máy sẽ giả định rằng hai giá trị gần nhau thì giống nhau hơn là hai giá trị cách xa nhau. Có thể điều này sẽ không thành vấn đề trong một số trường hợp (ví dụ: với các hạng mục có thứ tự như “kém”, “trung bình”, “tốt” và “xuất sắc”), nhưng rõ ràng điều này không đúng với cột
ocean_proximity(ví dụ: hạng mục 0 và 4 rõ ràng gần nhau hơn hạng mục 0 và 1). Để khắc phục vấn đề này, một số giải pháp phổ biến là sử dụng thuộc tính nhị phân cho mỗi hạng mục: một thuộc tính bằng 1 khi hạng mục là “<1H OCEAN” (và trái lại bằng 0), một thuộc tính khác bằng 1 khi hạng mục là “INLAND” (và trái lại bằng 0), v.v. Phương pháp này được gọi là biểu diễn one-hot (one-hot encoding), vì chỉ có một thuộc tính bằng 1 (hot), trong khi các thuộc tính khác sẽ bằng 0 (cold). Các thuộc tính mới đôi khi được gọi là thuộc tính giả (dummy attribute).Scikit-Learncung cấp lớpOneHotEncodergiúp biến đổi các giá trị hạng mục thành các vector one-hot:

- Lưu ý rằng đầu ra ở đây là một ma trận thưa (sparse matrix)
SciPythay vì một mảngNumPy. Điều này rất hữu ích khi bảng có thuộc tính hạng mục với hàng nghìn danh mục. Sau khi biểu diễn thành dạng one-hot, ta có một ma trận với hàng nghìn cột chứa đầy giá trị 0 ngoại trừ giá trị 1 duy nhất ở mỗi hàng. Việc sử dụng một lượng bộ nhớ khổng lồ chỉ để lưu trữ các số 0 sẽ rất lãng phí, vì thế ta có thể sử dụng một ma trận thưa và chỉ lưu trữ vị trí của các phần tử khác 0. Ta có thể sử dụng nó gần giống như một mảng hai chiều thông thường, tuy nhiên nếu bạn thực sự muốn chuyển đổi nó thành một mảngNumPy(dày đặc), chỉ cần gọi phương thứctoarray()như sau:

- Một lần nữa, ta có thể trích xuất danh sách các hạng mục bằng cách sử dụng thuộc tính
categories_của thực thể encoder:

💹 Mẹo: Nếu một thuộc tính hạng mục có số lượng hạng mục lớn (ví dụ: mã quốc gia, nghề nghiệp, giống loài), biểu diễn one-hot sẽ trả về rất nhiều đặc trưng đầu vào. Điều này có thể làm chậm quá trình huấn luyện và làm suy giảm chất lượng mô hình. Trong trường hợp này, ta có thể thay thế thuộc tính hạng mục bằng các đặc trưng số học có liên quan đến các hạng mục đó: ví dụ, có thể thay đặc trưng ocean_proximity bằng khoảng cách tới đại dương (tương tự, mã quốc gia có thể được thay bằng tổng dân số hoặc GDP đầu người). Ngoài ra, cũng có thể thay thế mỗi hạng mục bằng một vector ít chiều có được thông qua việc học, gọi là embedding. Biểu diễn của mỗi hạng mục sẽ được học trong quá trình huấn luyện. Đây là một ví dụ của học biểu diễn (representation learning).
Bộ Biến đổi Tùy chỉnh
Mặc dù
Scikit-Learncung cấp khá nhiều bộ biến đổi hữu dụng, ta vẫn sẽ cần thiết kế một bộ biến đổi dành riêng cho các tác vụ như dọn dẹp hay kết hợp các thuộc tính cụ thể. Ta sẽ muốn bộ biến đổi này hoạt động trơn tru cùng với các thành phần khác củaScikit-Learn(nhưpipeline). Để làm được điều này, ta chỉ cần tạo một lớp và khai báo ba phương thức:fit()(trả vềself),transform(), vàfit_transform()bởi vìScikit-Learndựa trênduck typing(chứ không phải tính kế thừa).Phương thức
fit_transform()sẽ có sẵn nếu ta thêmTransformerMixinlàm lớp cơ sở. Nếu thêmBaseEstimatorlàm lớp cơ sở (và tránh sử dụng*argsvà**kwargstrong phương thức khởi tạo), ta sẽ có thêm hai phương thức rất hữu ích cho việc tự động tinh chỉnh các siêu tham số làget_params()vàset_params().Ví dụ, đoạn mã sau lập trình một bộ biến đổi để ghép nối các thuộc tính kết hợp mà chúng ta đã thảo luận trước đó:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
Hãy tạo một chuyển đổi tùy chỉnh để thêm các thuộc tính bổ sung:
from sklearn.base import BaseEstimator, TransformerMixin
# column index
rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room=True): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X):
rooms_per_household = X[:, rooms_ix] / X[:, households_ix]
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)
- Trong ví dụ này, bộ biến đổi có một siêu tham số
add_bedrooms_per_room, mặc định được gán làTrue(việc cung cấp các giá trị mặc định hợp lý thường khá hữu ích). Siêu tham số này sẽ cho phép ta dễ dàng biết được liệu việc thêm thuộc tính này có giúp ích cho thuật toán Học Máy hay không. Tổng quát hơn, ta có thể thêm một siêu tham số để bật/tắt một bước chuẩn bị dữ liệu bất kỳ nếu không chắc chắn 100% về nó. Càng tự động hóa những bước chuẩn bị dữ liệu này, ta có thể thử nghiệm càng nhiều tổ hợp khác nhau, từ đó tăng khả năng tìm được cách kết hợp hiệu quả nhất (và tiết kiệm rất nhiều thời gian). - Lưu ý rằng tôi đã cố gắng mã hóa các chỉ số (3, 4, 5, 6) để có sự ngắn gọn và rõ ràng, nhưng sẽ gọn gàng hơn nhiều nếu bạn lấy chỉ số một cách linh động, như thế này:
1
2
3
col_names = "total_rooms", "total_bedrooms", "population", "households"
rooms_ix, bedrooms_ix, population_ix, households_ix = [
housing.columns.get_loc(c) for c in col_names] # get the column indices
- Ngoài ra,
housing_extra_attribslà một mảngNumPy, chúng ta đã mất tên cột (thật không may, đó là vấn đề với Scikit-Learn). Để khôi phụcDataFrame, bạn có thể chạy như sau:
1
2
3
4
5
housing_extra_attribs = pd.DataFrame(
housing_extra_attribs,
columns=list(housing.columns)+["rooms_per_household", "population_per_household"],
index=housing.index)
housing_extra_attribs.head()
Co giãn Đặc trưng
Một trong số những phép biến đổi quan trọng nhất mà ta cần thực hiện trên dữ liệu đó là co giãn đặc trưng (
feature scaling). Ngoại một số ít trường hợp ngoại lệ, các thuật toán Học Máy không hoạt động tốt khi các đặc trưng đầu vào có khoảng giá trị khác nhau. Vấn đề này xảy ra trong dữ liệu nhà ở: tổng số phòng nằm trong khoảng từ 6 tới 39,320, trong khi thu nhập trung vị chỉ dao động từ 0 tới 15. Lưu ý rằng việc co giãn các giá trị mục tiêu (nhãn) thường không cần thiết.Hai cách phổ biến nhất để đưa các thuộc tính về cùng một khoảng giá trị là: co giãn min-max (
min-max scaling) và chuẩn tắc hóa (standardization).- Co giãn min-max (còn được gọi là chuẩn hóa –
normalization) là phương pháp đơn giản nhất: các giá trị được dịch chuyển và co giãn sao cho chúng nằm trong khoảng từ 0 tới 1. Chúng ta thực hiện điều này bằng cách trừ đi giá trị nhỏ nhất và chia cho độ hiệu của giá trị lớn nhất và nhỏ nhất.Scikit-Learncung cấp một bộ biến đổi có tên làMinMaxScalerđể thực hiện phép biến đổi này. Bộ biến đổi này chứa siêu tham sốfeature_rangecho phép thay đổi khoảng giới hạn trong trường hợp ta không muốn sử dụng khoảng [0, 1]. - Chuẩn tắc hóa thì khác. Đầu tiên ta trừ đi giá trị trung bình (vì vậy các giá trị chuẩn tắc luôn có giá trị trung bình bằng 0), sau đó chia cho độ lệch chuẩn để phân phối thu được có phương sai đơn vị. Không giống như
min-max scaling, chuẩn tắc hóa không ràng buộc các giá trị phải nằm trong một khoảng cụ thể. Điều này có thể trở thành vấn đề đối với một số thuật toán (ví dụ như mạng nơ-ron thường yêu cầu đầu vào nằm trong khoảng từ 0 tới 1). Tuy nhiên, chuẩn tắc hóa lại ít bị ảnh hưởng bởi các điểm ngoại lai. Ví dụ, giả sử một quận có thu nhập trung bình bằng 100 (do nhầm lẫn). Khi đómin-max scalingsẽ co tất cả các giá trị khác từ [0, 15] xuống [0, 0.15], còn chuẩn tắc hóa sẽ không bị ảnh hưởng đáng kể.Scikit-Learncung cấp một bộ biến đổi gọi là StandardScaler cho việc chuẩn tắc hóa.
📝 Note: Cùng với tất cả các bộ biến đổi khác, ta chỉ được khớp bộ co giãn cho dữ liệu huấn luyện, không phải toàn bộ dữ liệu (bao gồm tập kiểm tra). Sau đó ta mới sử dụng nó để biến đổi tập huấn luyện và tập kiểm tra (và cả dữ liệu mới). Tức là nếu như bạn muốn sử dụng min-max scaling thì bạn chỉ được phép tính giá trị min và max trên bộ huấn luyện rồi áp dụng công thức (x - min) / (max - min) cho toàn bộ tập (cả tập kiểm tra).
Pipeline biến đổi
- Có thể thấy, có khá nhiều bước biến đổi dữ liệu cần được thực hiện theo đúng trình tự. May mắn thay,
Scikit-Learncung cấp lớpPipelinenhằm thực hiện các chuỗi biến đổi như vậy. Dưới đây là mộtpipelinenhỏ dành cho các thuộc tính số:
1
2
3
4
5
6
7
8
9
10
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
- Phương thức khởi tạo của
Pipelinenhận một danh sách các cặp tên/bộ ước lượng để định nghĩa một chuỗi các bước. Tất cả các bộ ước lượng phải là bộ biến đổi (tức phải có phương thứcfit_transform()), ngoại trừ bộ ước lượng cuối cùng. Tên gọi có thể được đặt một cách bất kỳ (miễn sao chúng độc nhất và không chứa dấu gạch dưới kép, __), và chúng sẽ trở nên hữu ích cho việc điều chỉnh siêu tham số sau này. Khi ta gọi phương thức
fit()của pipeline, nó sẽ lần lượt gọi phương thứcfit_transform()của tất cả các bộ biến đổi, ngoại trừ bộ ước lượng cuối cùng sẽ gọi phương thứcfit(). Đầu ra từ bộ biến đổi trước sẽ là tham số cho bộ biến đổi phía sau.Pipeline này có các phương thức giống bộ ước lượng cuối cùng. Trong ví dụ này, bộ ước lượng cuối cùng là bộ biến đổi
StandardScaler, vì thế phương thứctransform()(và cảfit_transform()mà ta đã dùng) của pipeline này sẽ thực hiện tất cả các phép biến đổi trên tập dữ liệu theo đúng trình tự.- Cho đến nay, ta đã xử lý các cột dữ liệu hạng mục và các cột dữ liệu số một cách riêng biệt. Sẽ thuận tiện hơn nếu ta có một bộ biến đổi có thể xử lý tất cả các cột, và áp dụng những phép biến đổi phù hợp cho từng loại cột. Từ phiên bản
0.20,Scikit-Learnđã giới thiệuColumnTransformercho mục đích này, và tiện tốt đó là nó hoạt động rất tốt vớiDataFramecủapandas. Hãy sử dụng nó để thực hiện các phép biến đổi trên tập dữ liệu nhà ở:
1
2
3
4
5
6
7
8
9
10
11
12
from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(housing)
Đầu tiên ta khai báo lớp
ColumnTransformer, lấy danh sách chứa tên các cột có giá trị số và danh sách chứa tên các cột có giá trị hạng mục, rồi khởi tạo một đối tượngColumnTransformer. Phương thức khởi tạo đòi hỏi một danh sách cáctuple, mỗituplechứa tên, bộ biến đổi và danh sách tên (hoặc chỉ số) của các cột mà ta muốn áp dụng bộ biến đổi này. Ở ví dụ này, các cột chứa giá trị số sẽ được biến đổi bởinum_pipelineđã định nghĩa phía trên, và các cột chứa giá trị hạng mục sẽ được biến đổi bằngOneHotEncoder. Cuối cùng, ta áp dụng đối tượngColumnTransformernày lên dữ liệu nhà ở: nó sẽ áp dụng mỗi phép biến đổi lên các cột phù hợp và nối đầu ra theo cột (axis=1, các bộ biến đổi đều phải trả về số hàng giống nhau).Chú ý rằng
OneHotEncodertrả về một ma trận thưa, cònnum_pipelinetrả về một ma trận dày đặc. Khi kết quả trả về chứa cả ma trận thưa lẫn ma trận dày đặc,ColumnTransformersẽ ước lượng mật độ của ma trận cuối cùng (tức tỉ lệ các phần tử khác không), rồi trả về một ma trận thưa nếu mật độ này nhỏ hơn một ngưỡng cho trước (mặc định thìsparse_threshold=0.3). Trong ví dụ này, nó trả về một ma trận dày đặc. Đã xong, giờ ta có mộtpipelinetiện xử lý có khả năng nhận toàn bộ dữ liệu giá nhà và áp dụng các phép biến đổi phù hợp lên từng cột.
💹 Mẹo: Ngoài việc sử dụng một bộ biến đổi, ta cũng có thể sử dụng “drop” nếu muốn bỏ cột, hoặc “passthrough” nếu muốn giữ nguyên cột. Mặc định, những cột còn lại (tức những cột không xuất hiện trong các danh sách trên) sẽ bị loại bỏ, nhưng ta có thể đặt tham số remainder thành bất cứ bộ biến đổi nào (hoặc “passthrough”) nếu ta muốn xử lý chúng theo kiểu khác.
- Nếu bạn đang sử dụng
Scikit-Learn 0.19hoặc cũ hơn, bạn có thể dùng một thư viện bên thứ ba nhưsklearn-pandas, hoặc tự lập trình một phép biến đổi hoạt động tương tự nhưColumnTransformer. Một phương án khác là sử dụng lớpFeatureUnionđể áp dụng các phép biến đổi khác nhau rồi gộp nối các kết quả đầu ra. Tuy nhiên sẽ sẽ không thể chỉ định các cột khác nhau cho mỗi phép biến đổi, mà chúng sẽ đều được áp dụng cho toàn bộ dữ liệu. Vấn đề này có thể được khắc phục bằng cách tự lập trình một phép biến đổi để chọn cột.
5. Chọn và Huấn luyện Mô hình
- Ta đã định nghĩa xong bài toán, thu thập và khám phá dữ liệu, lấy mẫu tập huấn luyện và tập kiểm tra, rồi viết pipeline chứa các phép biến đổi để làm sạch và chuẩn bị dữ liệu cho các thuật toán Học Máy một cách tự động. Cuối cùng thì ta đã sẵn sàng để chọn và huấn luyện một mô hình Học Máy.
Huấn luyện và Đánh giá trên tập Huấn luyện
- Tin tốt là nhờ có những bước phía trên, mọi thứ sẽ trở nên đơn giản hơn nhiều. Đầu tiên, hãy huấn luyện một mô hình Hồi quy Tuyến tính, như ta đã làm trong chương trước:
1
2
3
4
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
- Rất tốt! Bây giờ ta đã có một mô hình Hồi quy Tuyến tính khả dụng. Hãy cùng thử nó với một vài mẫu dữ liệu từ tập huấn luyện:
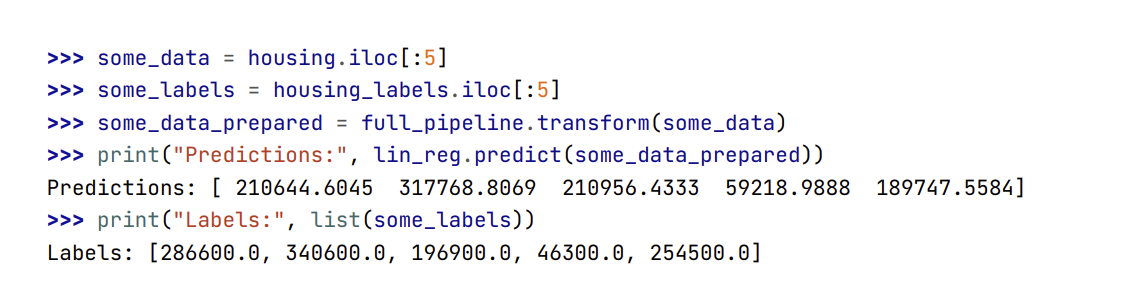
- Nó có hoạt động, dù các dự đoán chưa được chính xác cho lắm (dự đoán đầu tiên bị lệch khoảng 40%!). Hãy đo RMSE của mô hình này trên toàn bộ tập huấn luyện bằng hàm
mean_squared_error()có sẵn trongScikit-Learn, ngoài ra thì bạn có thể đo MAE bằng hàmmean_absolute_error():

Có vẫn hơn không, nhưng rõ ràng kết quả này không tốt: giá trị
median_housing_valuesở hầu hết các quận nằm trong khoảng 120,000 USD và 265,000 USD, nên sai lệch khoảng 68,628 USD chưa thể làm ta hài lòng. Đây là một ví dụ cho việc mô hình dưới khớp dữ liệu huấn luyện. Khi điều này xảy ra, có thể các đặc trưng không cung cấp đủ thông tin để đưa ra dự đoán tốt, hoặc cũng có thể mô hình vẫn chưa đủ mạnh. Như ta đã thấy ở chương trước, những phương pháp chính để giải quyết vấn đề dưới khớp là chọn một mô hình mạnh hơn, cung cấp đặc trưng tốt hơn cho thuật toán hoặc giảm các điều kiện ràng buộc lên mô hình. Mô hình này chưa được điều chỉnh nên ta có thể loại trừ phương án cuối cùng. Ta có thể thử thêm các đặc trưng khác (ví dụ như log của dân số), nhưng trước tiên hãy thử sử dụng một mô hình phức tạp hơn để xem kết quả ra sao.Hãy huấn luyện một
DecisionTreeRegressor. Đây là một mô hình mạnh mẽ và có khả năng tìm ra các quan hệ phi tuyến trong dữ liệu. Chắc hẳn giờ bạn đã thấy quen thuộc với đoạn mã bên dưới:
1
2
3
4
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor()
tree_reg.fit(housing_prepared, housing_labels)
- Sau khi mô hình đã được huấn luyện xong, hãy đánh giá nó trên tập huấn luyện:

- Gì thế này!? Không hề có sai lệch? Liệu có phải mô hình này hoàn hảo tuyệt đối không? Tất nhiên, khả năng cao là mô hình đã quá khớp dữ liệu một cách nặng nề. Làm thế nào để xác nhận điều này? Như đề cập ở trên, ta không muốn động vào tập kiểm tra cho đến khi sẵn sàng triển khai một mô hình đáng tin cậy. Vì vậy, ta cần phải dành riêng một phần của tập huấn luyện cho việc kiểm định mô hình và phần còn lại cho việc huấn luyện.
Kiểm định Chéo: Phương pháp Đánh giá tốt hơn
- Môt cách để đánh giá mô hình Cây Quyết định là sử dụng hàm
train_test_split()để chia tập huấn luyện thành một tập huấn luyện nhỏ hơn và một tập kiểm định, rồi huấn luyện mô hình trên tập huấn luyện nhỏ và đánh giá nó trên tập kiểm định. Ta sẽ cần làm việc nhiều hơn một chút, nhưng cũng không có gì quá khó khăn và phương án này hoạt động khá tốt. - Một phương án tuyệt vời khác là sử dụng tính năng kiểm định chéo
K-fold(K-fold cross-validation) củaScikit-Learn. Đoạn mã dưới đây chia ngẫu nhiên tập huấn luyện thành 10 tập con riêng biệt gọi làfold, rồi huấn luyện và đánh giá mô hình Cây Quyết định 10 lần, mỗi lần chọn một fold khác nhau để đánh giá và huấn luyện trên 9 fold còn lại. Kết quả là một mảng chứa 10 điểm số đánh giá:
1
2
3
4
5
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
📝 Note: Tính năng kiểm định chéo của Scikit-Learn làm việc với một hàm lợi ích (càng cao càng tốt) thay vì một hàm chi phí (càng thấp càng tốt), nên hàm tính điểm là hàm đối của MSE (tức có giá trị âm). Đây là lý do tại sao đoạn mã trên tính -scores trước khi lấy căn bậc hai.
- Hãy cùng xem kết quả:

- Giờ thì Cây Quyết định không còn tốt như trước nữa. Thực chất, có vẻ nó hoạt động tệ hơn cả Mô Hình Hồi Quy Tuyến Tính ! Chú ý rằng kiểm định chéo không chỉ giúp ta ước tính chất lượng của mô hình, mà nó còn đánh giá độ chính xác của ước tính này (tức độ lệch chuẩn). Cây Quyết Định có điểm số khoảng 71,407 +- 2,439. Ta sẽ không có được thông tin này nếu chỉ dùng một tập kiểm định. Tuy nhiên, kiểm định chéo lại đi kèm với chi phí của việc huấn luyện mô hình nhiều lần, nên không phải lúc nào nó cũng khả thi.
- Để chắc chắn hơn, hãy tính điểm số tương tự như trên cho mô hình Hồi Quy Tuyến tính:
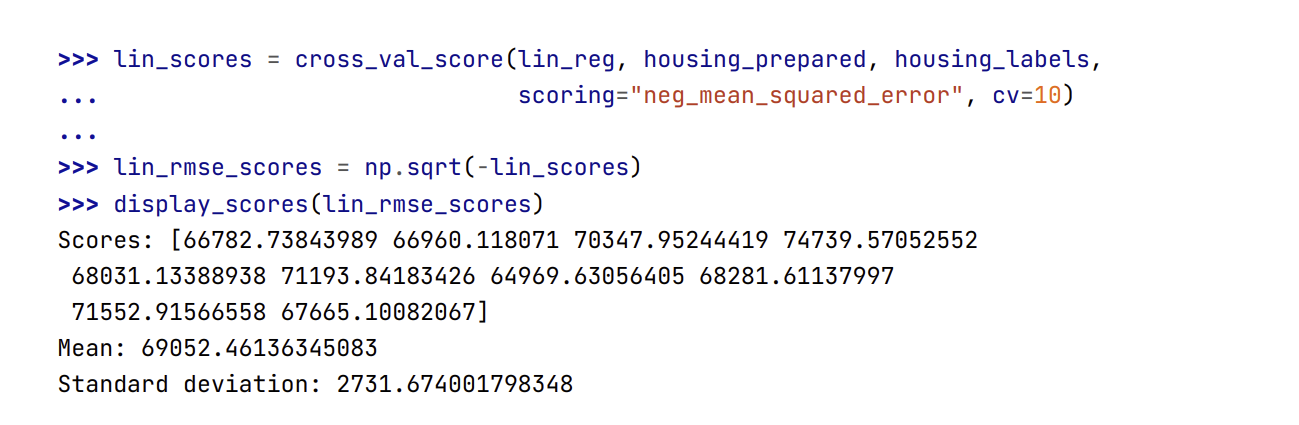
- Quả thật, mô hình Cây Quyết định quá khớp nặng tới mức nó hoạt động tệ hơn cả mô hình Hồi Quy Tuyến Tính.
- Giờ hãy thử một mô hình cuối cùng:
RandomForestRegressor. Như ta sẽ thấy trong blog khác, Rừng Ngẫu nhiên hoạt động bằng cách huấn luyện nhiều Cây Quyết định với các tập con đặc trưng ngẫu nhiên, rồi lấy trung bình dự đoán của chúng. Xây dựng một mô hình dựa trên nhiều mô hình khác được gọi là HọcEnsemble, và đây thường là một cách tốt để cải thiện hơn nữa các thuật toán ML mà nguồn tương tự như với các mô hình khác:
1
2
3
4
5
6
7
8
9
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor(n_estimators=100, random_state=42)
forest_reg.fit(housing_prepared, housing_labels)
housing_predictions = forest_reg.predict(housing_prepared)
forest_mse = mean_squared_error(housing_labels, housing_predictions)
forest_rmse = np.sqrt(forest_mse)
forest_rmse
18603.515021376355
1
2
3
4
5
6
from sklearn.model_selection import cross_val_score
forest_scores = cross_val_score(forest_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
forest_rmse_scores = np.sqrt(-forest_scores)
display_scores(forest_rmse_scores)
Scores: [49519.80364233 47461.9115823 50029.02762854 52325.28068953
49308.39426421 53446.37892622 48634.8036574 47585.73832311
53490.10699751 50021.5852922 ]
Mean: 50182.303100336096
Standard deviation: 2097.0810550985693
Kết quả này tốt hơn rất nhiều. Rừng Ngẫu nhiên có vẻ rất hứa hẹn. Tuy nhiên, lưu ý rằng điểm số trên tập huấn luyện vẫn thấp hơn nhiều so với trên tập kiểm định, có nghĩa là mô hình vẫn quá khớp trên tập huấn luyện. Các giải pháp khả thi cho hiện tượng quá khớp là đơn giản hóa mô hình, ràng buộc mô hình (tức điều chuẩn), hoặc thu thập nhiều dữ liệu huấn luyện hơn nữa. Tuy nhiên, trước khi tìm hiểu sâu hơn về mô hình Rừng Ngẫu nhiên, bạn nên thử nhiều mô hình Học Máy khác nhau (ví dụ: thuật toán Máy Vector Hỗ trợ các hạt nhân khác nhau, hay các mạng nơ-ron), chứ không nên dành quá nhiều thời gian để tinh chỉnh các siêu tham số. Mục tiêu là để chọn ra một vài mô hình triển vọng (từ hai đến năm mô hình).
Bạn nên lưu mọi mô hình đã thử nghiệm để có thể dễ dàng quay lại làm việc với bất kỳ mô hình nào. Hãy đảm bảo rằng bạn lưu cả siêu tham số và tham số đã được huấn luyện, điểm số kiểm định chéo và có thể cả các dự đoán thực tế. Điều này sẽ cho phép bạn dễ dàng so sánh điểm số giữa các loại mô hình và so sánh các loại lỗi mà chúng mắc phải. Bạn có thể dễ dàng lưu các mô hình trong
Scikit-Learnbằng cách sử dụng mô-đunpicklecủa Python hoặc sử dụngjoblib, một thư viện hiệu quả hơn trong việc chuỗi hóa các mảng Numpy lớn (bạn có thể cài đặt thư viện này bằng cách sử dụng pip):
1
2
3
4
5
6
import joblib
joblib.dump(my_model, "my_model.pkl")
# and later...
my_model_loaded = joblib.load("my_model.pkl")
6. Tinh chỉnh mô hình
- Giả sử ta có một danh sách những mô hình triển vọng và cần được tinh chỉnh. Hãy xem qua một vài cách để thực hiện việc này:
Tìm kiếm dạng Lưới
- Một lựa chọn là tinh chỉnh thủ công đến khi tìm được một bộ các giá trị siêu tham số ưng ý. Cách này thực sự rất nhàm chán và ta có thể không có đủ thời gian để khám phá nhiều cách kết hợp khác nhau.
- Thay vào đó, hãy sử dụng
GridSearchCVtrongScikit-Learnđể tìm kiếm một bộ siêu tham số phù hợp. Ta chỉ cần chỉ rõ những siêu tham số muốn tinh chỉnh và các giá trị nào cần thử, rồi GridSearchCV sẽ sử dụng phương pháp kiểm định chéo để đánh giá tất cả các cách kết hợp khả thi của các giá trị siêu tham số. Ví dụ, đoạn mã dưới đây sẽ tìm kiếm bộ giá trị tốt nhất cho các siêu tham số củaRandomForestRegressor:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from sklearn.model_selection import GridSearchCV
param_grid = [
# try 12 (3×4) combinations of hyperparameters
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
# then try 6 (2×3) combinations with bootstrap set as False
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor(random_state=42)
# train across 5 folds, that's a total of (12+6)*5=90 rounds of training
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error',
return_train_score=True)
grid_search.fit(housing_prepared, housing_labels)
💹 Mẹo: Khi không biết giá trị nào sẽ phù hợp với một siêu tham số, một cách tiếp cận đơn giản là thử các lũy thừa liên tiếp của 10 (hoặc một số nhỏ hơn nếu bạn muốn tìm kiếm chi tiết hơn, như với siêu tham số n_estimators trong ví dụ này).
- Đối số
param_gridtrên yêu cầuScikit-Learnphải: đầu tiên đánh giá tất cả $3 × 4 = 12$ cách kết hợp củan_estimatorsvàmax_featuresđược mô tả trong dict đầu tiên (hiện tại bạn không cần quan tâm về ý nghĩa của các siêu tham số này; chúng sẽ được giải thích trong blog khác), sau đó thử tất cả $2 x 3 = 6$ cách kết hợp của hai siêu tham số đó trong dict thứ hai, nhưng lần này vớibootstrapđược đặt làFalsethay vì giá trị mặc địnhTrue. Tìm kiếm dạng lưới sẽ khám phá $12 + 6 = 18$ cách kết hợp của các giá trị siêu tham số trong RandomForestRegressor và huấn luyện mỗi mô hình 5 lần (vì dùng phương pháp kiểm định chéo 5 fold). Nói cách khác, sẽ có tổng cộng $18 × 5 = 90$ lần huấn luyện! Việc này có thể sẽ khá tốn thời gian, nhưng sau khi hoàn thành, bạn có thể tìm được bộ giá trị tốt nhất cho các siêu tham số như sau:
1
grid_search.best_params_
{‘max_features’: 8, ‘n_estimators’: 30}
💹 Mẹo: Vì 8 và 30 là giá trị lớn nhất được kiểm định, bạn nên thử tìm kiếm lại với giá trị lớn hơn; điểm số có thể sẽ tiếp tục được cải thiện.
- Bạn cũng có thể thu được bộ ước lượng tốt nhất một cách trực tiếp như sau:

📝 Note: Nếu GridSearchCV được khởi tạo với refit = True (là giá trị mặc định), thì ngay sau khi tìm được bộ ước lượng tốt nhất theo kiểm định chéo, nó sẽ huấn luyện laiji mô hình trên toàn bộ tập dữ liệu huấn luyện một lần nữa. Đây thường là một ý tưởng hay vì đưa thêm nhiều dữ liệu hơn nữa sẽ có khả căng cải thiện chất lượng của mô hình.
- Và điểm số đánh giá cũng sẽ được trả về:
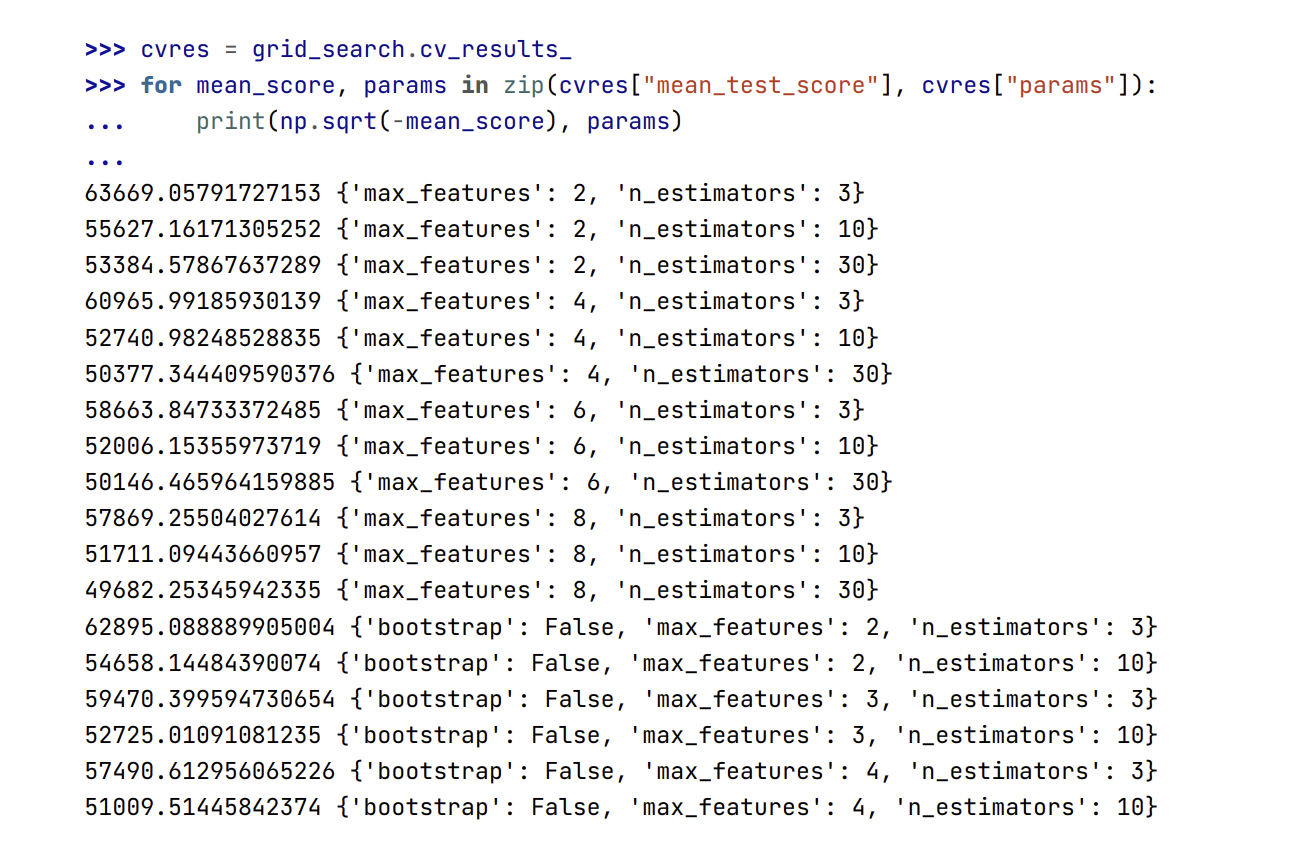
- Trong ví dụ này, chúng ta tìm được mô hình tốt nhất bằng cách đặt giá trị siêu tham số
max_featureslà 8 vàn_estimatorslà 30. Điểm RMSE cho cách kết hợp này là 49,682, tốt hơn một chút so với các giá trị mặc định của siêu tham số trước đó (là 50,182). Chúc mừng, bạn đã tinh chỉnh thành công mô hình tốt nhất của mình !
💹 Mẹo: Đừng quên rằng bạn có thể coi một số bước chuẩn bị dữ liệu là siêu tham số. Ví dụ, tìm kiếm dạng lưới sẽ tự động kiểm tra xem có nên thêm một đặc trưng hay không (ví dụ: sử dụng siêu tham số add_bedroom_per_room trong bộ chuyển đổi CombineAttributesAdder). Tương tự, bạn cũng có thể sử dụng tìm kiếm dạng lưới để tối ưu hóa cách xử lý tốt nhất các mẫu ngoại lai, các đặc trưng bị khuyết, lựa chọn đặc trưng, v.v.
Tìm kiếm Ngẫu Nhiên
Tìm kiếm dạng lưới có thể được dùng để khám phá tương đối ít các cách kết hợp như trong ví dụ trước, nhưng khi không gian tìm kiếm siêu tham số lớn hơn thì ta nên ưu tiên dùng
RandomizedSearchCV. Lớp này có thể được sử dụng tương tự như lớpGridSearchCV, nhưng thay vì thử tất cả các cách kết hợp khả thi, nó sẽ đánh giá một số cách kết hợp ngẫu nhiên nhất định bằng cách chọn một giá trị ngẫu nhiên cho mỗi siêu tham số tại mỗi lần lặp. Phương pháp này có hai lợi ích chính sau đây:Nếu ta để thuật toán tìm kiếm ngẫu nhiên chạy 1,000 lần lặp, nó sẽ khám phá 1,000 giá trị khác nhau cho mỗi siêu tham số (thay vì chỉ một vài giá trị trên mỗi siêu tham số như trong tìm kiếm dạng lưới).
Chỉ cần nhập số lần lặp, ta sẽ kiểm soát tốt hơn tài nguyên tính toán được phân bổ cho việc tìm kiếm siêu tham số.
Dưới đây là ví dụ:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {
'n_estimators': randint(low=1, high=200),
'max_features': randint(low=1, high=8),
}
forest_reg = RandomForestRegressor(random_state=42)
rnd_search = RandomizedSearchCV(forest_reg, param_distributions=param_distribs,
n_iter=10, cv=5, scoring='neg_mean_squared_error', random_state=42)
rnd_search.fit(housing_prepared, housing_labels)
cvres = rnd_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
49150.70756927707 {‘max_features’: 7, ‘n_estimators’: 180}
51389.889203389284 {‘max_features’: 5, ‘n_estimators’: 15}
50796.155224308866 {‘max_features’: 3, ‘n_estimators’: 72}
50835.13360315349 {‘max_features’: 5, ‘n_estimators’: 21}
49280.9449827171 {‘max_features’: 7, ‘n_estimators’: 122}
50774.90662363929 {‘max_features’: 3, ‘n_estimators’: 75}
50682.78888164288 {‘max_features’: 3, ‘n_estimators’: 88}
49608.99608105296 {‘max_features’: 5, ‘n_estimators’: 100}
50473.61930350219 {‘max_features’: 3, ‘n_estimators’: 150}
64429.84143294435 {‘max_features’: 5, ‘n_estimators’: 2}
Phương pháp Ensemble
- Một cách nữa để tinh chỉnh hệ thống là thử kết hợp các mô hình hoạt động tốt nhất. Nhóm (hoặc “ensemble”) các mô hình riêng lẻ này thường sẽ hoạt động tốt hơn so với một mô hình riêng lẻ tốt nhất (giống như Rừng Ngẫu nhiên hoạt động tốt hơn Cây Quyết định riêng lẻ), đặc biệt nếu các mô hình riêng lẻ mắc các lỗi rất khác nhau. Chúng ta sẽ trình bày chi tiết hơn trong blog khác.
Phân tích các Mô hình Tốt nhất và Lỗi của Chúng
- Ta thường có thêm những hiểu biết sâu hơn về bài toán bằng cách kiểm tra các mô hình tốt nhất. Ví dụ: RandomForestRegressor có thể tính được độ quan trọng tương đối của mỗi thuộc tính để đưa ra dự đoán chính xác:

- Hãy in ra các điểm số thể hiện độ quan trọng cùng với tên các thuộc tính tương ứng:
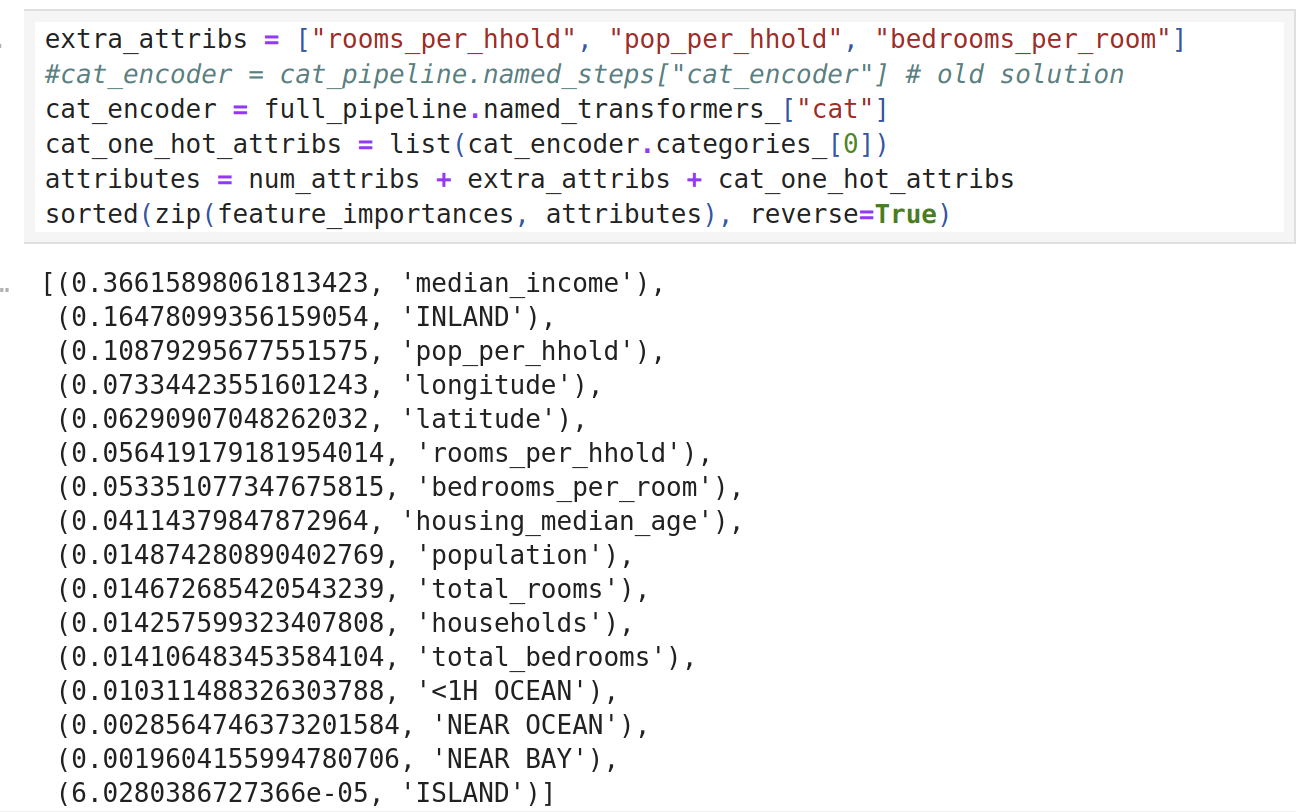
- Với thông tin này, bạn có thể thử loại bỏ một số đặc trưng ít hữu dụng (ví dụ: dường như chỉ có đặc trưng
ocean_proximitylà hữu dụng, nên có thể thử loại bỏ các đặc trưng khác). - Ta cũng nên xem xét các lỗi cụ thể mà hệ thống mắc phải, từ đó cố gắng hiểu nguyên nhân và tìm ra cách khắc phục vấn đề (như thêm các đặc trưng, bổ sung hoặc loại bỏ các đặc trưng không có giá trị, loại bỏ các mẫu ngoại lai, v.v).
Đánh giá Hệ Thống trên Tập Kiểm Tra
- Sau khi tinh chỉnh xong các mô hình, tq đã có một hệ thống hoạt động đủ tốt. Bây giờ là lúc để đánh giá mô hình cuối cùng trên tập dữ liệu kiểm tra. Không có gì đặc biệt về quá trình này: chỉ cần lấy các đặc trưng và nhãn từ tập kiểm tra, chạy
full_pipelineđể biến đổi dữ liệu (gọi hàmtransform()thay vìfit_transform(), bởi ta không muốn khớp trên tập kiểm tra!), và đánh giá mô hình cuối cùng trên tập kiểm tra:
1
2
3
4
5
6
7
8
9
10
11
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
final_rmse
47873.26095812988
- Trong một số trường hợp, ước lượng điểm cho sai số khái quát sẽ không đủ thuyết phục để triển khai mô hình: nếu mô hình này chỉ tốt hơn 0.1% so với mô hình đang được triển khai thì sao ? Bạn có thể muốn biết mức độ chính xác của ước lượng này. Để làm vậy, ta có thể tính toán khoảng tin cậy 95% cho lỗi khái quát bằng cách sử dụng
scipy.stats.interval()
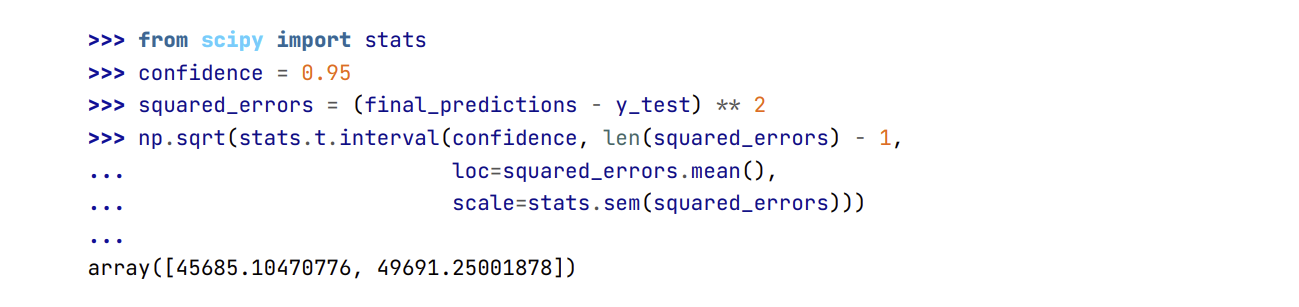
Nếu ta đã tinh chỉnh siêu tham số nhiều lần, chất lượng mô hình thường sẽ kém hơn một chút so với kết quả thu được từ kiểm định chéo (vì hệ thống lúc này đã được tinh chỉnh để hoạt động tốt trên dữ liệu kiểm định và nhiều khả năng sẽ không hoạt động tốt như vậy trên dữ liệu chưa biết). Việc này không xảy ra trong ví dụ trên, nhưng khi gặp trường hợp này, ta phải hạn chế việc tinh chỉnh siêu tham số để đạt kết quả cao hơn trên tập kiểm tra. Rất có thể mức cải thiện này sẽ không khái quát tốt trên dữ liệu mới.
Giờ đã đến giai đoạn tiến triển khai dự án: ta cần trình bày giải pháp của mình (nhấn mạnh những gì đã học được, những gì hiệu quả và không hiệu quả, các giả định và hạn chế của hệ thống), viết tài liệu chi tiết và chuẩn bị thuyết trình với minh họa rõ ràng cùng các ngôn từ dễ nói (ví dụ: “thu nhập trung vị là đặc trưng số một để dự đoán giá nhà ở”). Trong ví dụ về giá nhà ở California, chất lượng cuối cùng của hệ thống không tốt hơn so với kết quả của các chuyên gia (thường kém khoảng 20%), nhưng có lẽ ta vẫn nên triển khai hệ thống, đặc biệt nếu điều này giúp các chuyên gia tiết kiệm thời gian để họ có thể thực hiện các tác vụ thú vị và hiệu quả hơn.
7. Triển khai, Theo dõi, và Bảo trì Hệ thống
- Thật tuyệt! Hệ thống đã được chấp thuận để triển khai! Bây giờ ta cần chỉnh trang lại mã nguồn, viết tài liệu và kiểm thử, v.v., để chuẩn bị sẵn sàng vận hành. Sau đó, ta có thể triển khai mô hình vào môi trường vận hành (
production environment). Để làm điều này, ta có thể lưu mô hìnhScikit-Learnđã được huấn luyện (ví dụ: sử dụngjoblib), bao gồm toàn bộpipelinetiền xử lý dữ liệu, sau đó nạp mô hình này vào môi trường vận hành và sử dụng chúng để dự đoán bằng cách gọi phương thứcpredict(). Ví dụ, có thể mô hình sẽ được sử dụng trong một trang web: người dùng sẽ nhập dữ liệu về một quán mới và nhấp vào nút Dự đoán Giá. Thao tác này sẽ gửi một truy vấn chứa dữ liệu đến máy chủ của trang web, máy chủ sẽ chuyển tiếp đến ứng dụng web và gọi phương thứcpredict()của mô hình (nên nạp mô hình ngay khi khởi động máy chủ, thay vì nạp mỗi lần mô hình được sử dụng). Ngoài ra, ta có thể đóng gói mô hình trong một dịch vụ web chuyển dùng mà ứng dụng của bạn có thể truy vấn thông quaREST API(xem thêm Hình 2.17). Điều này giúp ta dễ dàng nâng cấp mô hình lên các phiên bản mới mà không làm gián đoạn ứng dụng. Nó cũng đơn giản hóa việc mở rộng quy mô, vì ta có thể khởi tạo nhiều dịch vụ web nếu cần cân bằng tải (load-balance) các truy vấn đến từ ứng dụng cho các dịch vụ này. Hơn nữa, nó cho phép ứng dụng web sử dụng bất kỳ ngôn ngữ nào, không chỉ Python.
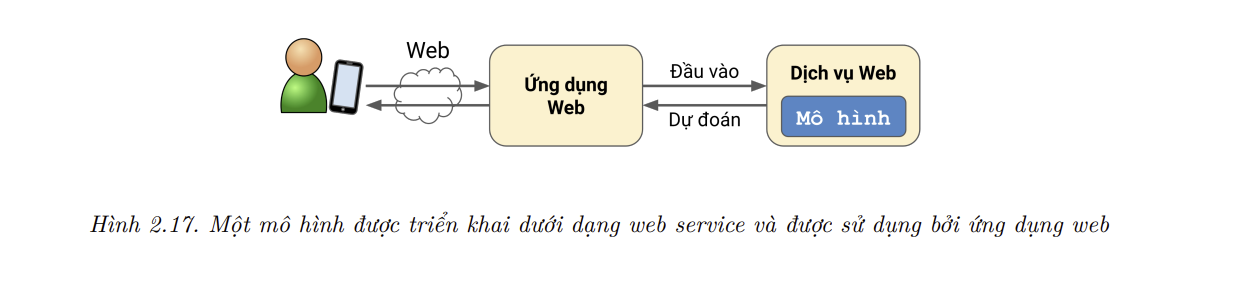
Một chiến lược phổ biến khác là triển khai mô hình trên điện toán đám mây, chẳng hạn như
Google Cloud AI Platform(tên gọi trước làGoogle Cloud ML Engine): chỉ cần lưu mô hình bằngjoblibvà tải lênGoogle Cloud Storage(GCS), sau đó tạo phiên bản mô hình mới tại Google Cloud AI Platform và trỏ nó tới tệp GCS. Chỉ đơn giản vậy thôi! Cách này cung cấp một dịch vụ web đơn giản đảm nhận việc cân bằng tải và mở rộng quy mô. Dịch vụ web trên sẽ nhận các yêu cầu dạng JSON chứa dữ liệu đầu vào (ví dụ: của một quán) và trả về các phần hồi JSON có chứa các dự đoán. Sau đó, ta có thể sử dụng dịch vụ web này trong trang web của mình (hoặc bất kỳ môi trường vận hành nào đang được sử dụng). Việc triển khai những mô hình TensorFlow trên nền tảng AI (sẽ được đề cập trong blog khác) không khác nhiều so với việc triển khai mô hìnhScikit-Learn.Nhưng triển khai sản phẩm không có nghĩa là đã hoàn thành công việc. Ta cũng cần viết mã giám sát để kiểm tra định kỳ chất lượng của hệ thống và kích hoạt cảnh báo khi nó giảm đi. Đây có thể là một sự giám nghiệm nghiêm trọng, khả năng cao là do một thành phần bị hỏng trong cơ sở hạ tầng, nhưng hãy lưu ý rằng nó cũng có thể là do một sự giảm nhẹ không được chú ý một thời gian dài. Điều này khá phổ biến với các mô hình có xu hướng “suy giảm chất lượng” theo thời gian: thật vậy, thế giới luôn thay đổi, vì vậy mô hình được huấn luyện trên dữ liệu của năm ngoái có thể sẽ không thích ứng được với dữ liệu hiện nay.
📝 Note: Ngay cả một mô hình đơn giản như phân loại ảnh mèo và chó cũng có thể cần phải huấn luyện lại thường xuyên. Lý do không phải vì chó và mèo sẽ biến đổi trong một số mặt chiều mà vì máy ảnh liên tục thay đổi, cùng với định dạng, độ sắc nét, độ sáng và tỷ lệ kích thước ảnh. Hơn nữa, mọi người có thể yêu thích các giống chó khác vào năm tới, hoặc gia cố thể đội cho vật nuôi của mình những chiếc mũ nhỏ xinh – không ai có thể biết trước được.
Vì vậy, ta luôn cần theo dõi chất lượng hiện tại của mô hình. Nhưng phải làm điều đó như thế nào? Thật ra nó phụ thuộc vào nhiều yếu tố. Trong một số trường hợp, chất lượng của mô hình có thể được suy ra từ các phép đo mục tiêu. Ví dụ, nếu mô hình của bạn là một phần của hệ thống đề xuất và nó đề xuất các sản phẩm mà người dùng có thể quan tâm thì thật dễ dàng để theo dõi số lượng sản phẩm được đề xuất đã bán mỗi ngày. Nếu con số này giảm xuống (so với các sản phẩm không được đề xuất), thì khả năng cao là do mô hình. Điều này có thể là do pipeline dữ liệu bị hỏng, hoặc có lẽ mô hình cần được huấn luyện lại trên dữ liệu mới (như đã được lưu ý ngay sau đây).
Tuy nhiên, không phải lúc nào bạn cũng có thể xác định được chất lượng của mô hình mà không cần bất kỳ phân tích nào của con người. Ví dụ, giả sử bạn đã huấn luyện một mô hình phân loại ảnh để phát hiện lỗi sản phẩm trên dây chuyền sản xuất. Làm thế nào để nhận biết rằng bao bì nếu chất lượng không đạt cũng được mô hình giảm xuống, trước khi nhận thấy phản hồi bị lỗi trực tiếp từ khách hàng? Một giải pháp là gửi cho người đánh giá tất cả các bức ảnh mà mô hình đã phân loại (đặc biệt là những bức ảnh mà mô hình không chắc chắn lắm). Tùy từng tác vụ mà người đánh giá phải là chuyên gia, hoặc họ cũng có thể là người thường, chẳng hạn như công nhân trên nền tảng cung ứng cộng đồng (ví dụ: Amazon Mechanical Turk). Trong một số ứng dụng, người đánh giá thậm chí có thể là chính người dùng, ví dụ như thông qua khảo sát hoặc captcha.
Dù bằng cách nào, ta cũng cần đặt một hệ thống giám sát (có hoặc không có người đánh giá để đánh giá trực tiếp mô hình), cũng như tất cả các quy trình có liên quan để xác định những gì cần làm trong trường hợp thất bại và làm sao để chuẩn bị ứng phó. Thật không may, thực tế thì việc này thường tốn nhiều công sức hơn việc xây dựng và huấn luyện một mô hình.
Nếu dữ liệu tiếp tục thay đổi, ta sẽ cần cập nhật tập dữ liệu và huấn luyện lại mô hình thường xuyên, do đó ta nên tự động hóa toàn bộ quá trình càng nhiều càng tốt. Dưới đây là một số việc có thể được tự động hóa:
Thường xuyên thu thập dữ liệu mới và gán nhãn (ví dụ: sử dụng người đánh giá).
Viết mã để huấn luyện mô hình và tinh chỉnh siêu tham số một cách tự động. Mã này có thể chạy tự động, ví dụ như sau mỗi ngày hoặc mỗi tuần, tùy thuộc vào nhu cầu của bạn.
Viết mã để đánh giá cả mô hình mới và mô hình cũ trên tập kiểm tra được cập nhật, và triển khai mô hình nếu chất lượng của nó không bị giảm sút (nếu giảm thì hãy tìm nguyên nhân).
Ta cũng nên đảm bảo rằng ta đã đánh giá chất lượng dữ liệu đầu vào của mô hình. Thỉnh thoảng chất lượng mô hình sẽ giảm nhẹ do chất lượng tín hiệu kém (ví dụ, một cảm biến bị trục trặc gửi đi các giá trị ngẫu nhiên, hoặc dữ liệu là công việc của một nhóm khác chưa được cập nhật), nhưng có thể mất một lúc trước khi chất lượng giảm sút đủ để kích hoạt cảnh báo. Nếu kiểm soát đầu vào của mô hình, ta có thể nắm bắt điều này sớm hơn. Vì vậy, ta có thể kích hoạt cảnh báo nếu có nhiều đầu vào bị thiếu đặc trưng, hoặc nếu giá trị trung bình và độ lệch chuẩn khác quá nhiều so với tập huấn luyện, hoặc một đặc trưng hàng mục bắt đầu chứa những hạng mục mới.
Cuối cùng, hãy giữ bản sao lưu cho mỗi mô hình và có quy trình cũng như công cụ để quay trở lại mô hình trước đó một cách nhanh chóng nếu mô hình mới bất đầu hoạt động kém hẳn đi vì lý do nào đó. Bản sao lưu cũng giúp ta dễ dàng so sánh mô hình mới với các mô hình trước đó. Tương tự, ta nên giữ bản sao lưu cho mỗi phiên bản dữ liệu để có thể quay trở lại tập dữ liệu trước đó nếu dữ liệu mới có vấn đề (ví dụ, nếu dữ liệu mới chứa nhiều điểm ngoại lai). Bản sao lưu dữ liệu cũng cho phép ta đánh giá bất kỳ mô hình nào trên bất kỳ tập dữ liệu nào trước đó.
💹 Mẹo: Bạn có thể muốn tạo một số tập con từ tập kiểm tra để đánh giá chất lượng của mô hình trên một phần cụ thể của dữ liệu. Ví dụ, bạn muốn có một tập con chỉ chứa dữ liệu gần đây nhất, hoặc một tập kiểm tra cho những loại đầu vào cụ thể (ví dụ, quán nằm trong dãy đất liền với quán ven biển). Việc này này giúp bạn hiểu sâu hơn về điểm mạnh và điểm yếu của mô hình.
- Có thể thấy, Học Máy cần khá nhiều cơ sở hạ tầng, vì vậy không có gì bất ngờ nếu dự án ML đầu tiên của bạn hao tốn nhiều công sức và thời gian để xây dựng và triển khai. May mắn thay, một khi tất cả các cơ sở hạ tầng đã ổn định, chặng đường từ ý tưởng đến sản phẩm thực tế sẽ ngắn hơn rất nhiều.
8. Thực Hành
Hy vọng rằng chương này đã giúp bạn hiểu về một dự án Học Máy cũng như cung cấp những công cụ bạn có thể sử dụng để huấn luyện một hệ thống hiệu quả. Có thể thấy, đa số công việc tập trung vào bước chuẩn bị dữ liệu: xây dựng công cụ kiểm soát, thiết lập quy trình đánh giá bằng con người, và tự động hóa việc huấn luyện mô hình một cách thường xuyên. Các thuật toán Học Máy dĩ nhiên cũng đóng vai trò quan trọng, nhưng bạn nên hiểu rõ về quy trình tổng thể và biết thấu đáo ba hoặc bốn thuật toán thay vì dành trọn thời gian để khám phá những thuật toán nâng cao.
Nếu bạn chưa làm điều đó, vậy thì bây giờ đã đến lúc để bạn mở laptop, chọn một tập dữ liệu mà bạn quan tâm, cố gắng thực hiện quy trình từ đầu đến cuối. Một nơi tốt để bắt đầu là một website dành cho các cuộc thi như Kaggle: bạn sẽ có một tập dữ liệu, một mục tiêu rõ ràng, và nhiều người để chia sẻ kinh nghiệm. Chúc bạn thực hành vui vẻ!
Bài tập
Hãy thử sử dụng một bộ hồi quy SVM (
sklearn.svm.SVR) với một vài siêu tham số nhưkernel="linear"(với những giá trị khác nhau cho C) hoặckernel="rbf"(với các giá trị khác nhau cho C và gamma). Đừng vội quan tâm đến những siêu tham số này là gì. Chất lượng của mô hình SVR tốt nhất như thế nào?Hãy thử thay
GridSearchCVbằngRandomizedSearchCV.Hãy thêm một bộ biến đổi vào
pipelineđể chỉ chọn ra những thuộc tính quan trọng nhất.Thử tạo một
pipelineđơn giản có thể thực hiện tự việc chuẩn bị dữ liệu đến việc đưa ra dự đoán cuối cùng.Tự động khám phá một số tùy chọn trong việc chuẩn bị dữ liệu bằng cách sử dụng
GridSearchCV.