Giải Tích Ma Trận
Để hiểu được rõ các normal equation trong machine learning thì bạn bắt buộc phải biết được phần này. Blog này được giữ y nguyên của Chương 2: Giải tích ma trận trong sách Machine Learning Cơ Bản nhưng có thêm phần code.
Trong blog này, nếu không nói gì thêm, chúng ta giả sử rằng các đạo hàm tồn tại. Tài liệu tham khảo chính của chương là Matrix calculus–Stanford
1 Đạo hàm của hàm trả về một số vô hướng
- Đạo hàm bậc nhất (first-order gradient) hay viết gọn là đạo hàm (gradient) của một hàm số $f(\mathbf{x}): \mathbb{R}^n \rightarrow \mathbb{R}$ theo $\mathbf{x}$ được định nghĩa là:
- Trong đó $\displaystyle\dfrac{\partial f(\mathbf{x})}{\partial x_i}$ là đạo hàm riêng của hàm số theo thành phần thứ $i$ của vector $\mathbf{x}$. Đạo hàm này được tính khi tất cả các biến, ngoài $x_i$, được giả sử là hằng số. Nếu không có thêm biến nào khác, $\nabla_{\mathbf{x}}f(\mathbf{x})$ thường được viết gọn là $\nabla f(\mathbf{x})$. Đạo hàm của hàm số này là một vector có cùng chiều với vector đang được lấy đạo hàm. Tức nếu vector được viết ở dạng cột thì đạo hàm cũng phải được viết ở dạng cột.
- Đạo hàm bậc hai (second-order gradient) của hàm số trên còn được gọi là Hessian và được định nghĩa như sau, với $\mathbb{S}^n \in \mathbb{R}^{n \times n}$ là tập các ma trận vuông đối xứng bậc $n$.
- Đạo hàm của một hàm số $f(\mathbf{X}): \mathbb{R}^{n \times m} \rightarrow \mathbb{R}$ theo ma trận $\mathbf{X}$ được định nghĩa là:

Cụ thể, để tính đạo hàm của một hàm $f: \mathbb{R}^{m\times n} \rightarrow \mathbb{R}$, ta tính đạo hàm riêng của hàm số đó theo từng thành phần của ma trận khi toàn bộ các thành phần khác được giả sử là hằng số. Tiếp theo, ta sắp xếp các đạo hàm riêng tính được theo đúng thứ tự trong ma trận.
Ví dụ: Xét hàm số $f: \mathbb{R}^2 \rightarrow \mathbb{R}$, $f(\mathbf{x}) = x_1 ^2 + 2x_1x_2 + \sin(x_1) + 2$. Đạo hàm bậc nhất theo $\mathbf{x}$ của hàm số đó là:
- Đạo hàm bậc hai theo $\mathbf{x}$, hay Hessian là:
- Chú ý rằng Hessian luôn là một ma trận đối xứng. Bạn có thể dùng thư viện
sympytrong python để tính đạo hàm, ví dụ dưới đây là tính đạo hàm bậc một với đầu vào là vector và đầu ra là số vô hướng:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import sympy as sp
# Khai báo biến vector x
x1, x2 = sp.symbols('x1 x2')
x = sp.Matrix([x1, x2])
# Định nghĩa hàm cần tính đạo hàm
f = x1**2 + 2*x1*x2 + sp.sin(x1) + 2
# Tính gradient (đạo hàm theo từng biến)
gradient = [sp.diff(f, xi) for xi in x]
# Hiển thị kết quả
print("Hàm:", f)
print("Gradient:", gradient)
- Ví dụ dưới đây là đạo hàm bậc hai của hàm trên:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import sympy as sp
# Khai báo các biến
x1, x2 = sp.symbols('x1 x2')
x = sp.Matrix([x1, x2])
# Định nghĩa hàm cần tính đạo hàm
f = x1**2 + 2*x1*x2 + sp.sin(x1) + 2
# Tính gradient (đạo hàm bậc 1)
gradient = sp.Matrix([sp.diff(f, xi) for xi in x]) # Gradient là vector
# Tính Hessian (đạo hàm bậc 2)
hessian = gradient.jacobian(x) # Hessian là ma trận
# Hiển thị kết quả
print("Hàm:", f)
print("Gradient:", gradient)
print("Hessian:")
sp.pprint(hessian) # In đẹp hơn
- Dưới đây là ví dụ nếu như đầu vào là ma trận và đầu ra là số vô hướng:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import sympy as sp
# Khai báo ma trận X (kích thước m x n)
m, n = 2, 2 # Ví dụ: ma trận 2x2
X = sp.MatrixSymbol('X', m, n) # Tạo ma trận ký hiệu
X_mat = sp.Matrix(m, n, lambda i, j: sp.Symbol(f'X{i+1}{j+1}')) # Ma trận cụ thể
# Định nghĩa hàm f (hàm số vô hướng)
f = sp.trace(X_mat.T * X_mat) + sp.det(X_mat) # Ví dụ: f = tr(X^T X) + det(X)
# Tính gradient (đạo hàm bậc 1 theo từng phần tử của X)
gradient = sp.Matrix([sp.diff(f, X_mat[i, j]) for i in range(m) for j in range(n)])
gradient = gradient.reshape(m, n) # Chuyển về dạng ma trận
# Hiển thị kết quả
print("Hàm f:")
sp.pprint(f)
print("\nGradient (đạo hàm bậc 1):")
sp.pprint(gradient)
2 Đạo hàm của hàm trả về một vector
- Những hàm số trả về một vector, hoặc gọn hơn hàm trả về vector được gọi là vector-valued function trong tiếng Anh.
- Xét một hàm trả về vector với đầu vào là một số thực $v(x): \mathbb{R} \rightarrow \mathbb{R}^n $:
- Đạo hàm của hàm số này theo $x$ là một vector hàng như sau:
- Đạo hàm bậc hai của hàm số này có dạng:
- Ví dụ: Cho một vector $\mathbf{a} \in \mathbb{R}^n$ và một hàm số vector-valued $v(x) = x\mathbf{a}$, đạo hàm bậc nhất và Hession của nó lần lượt là:
- Dưới đây là ví dụ python về tính đạo hàm bậc nhất và đạo hàm bậc hai của hàm trả về một vector:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from sympy import symbols, diff, Matrix
# Định nghĩa biến đầu vào
x = symbols('x')
# Định nghĩa hàm đầu vào (trả về một vector)
def f(x):
return Matrix([x**2, x**3, x + 1])
# Tính đạo hàm bậc nhất
vector_output = f(x)
jacobian = vector_output.jacobian([x])
# Tính đạo hàm bậc hai
second_derivative = jacobian.applyfunc(lambda expr: diff(expr, x))
print("Jacobian bậc 1 của hàm f(x) là:")
print(jacobian)
print("\nJacobian bậc 2 của hàm f(x) là:")
print(second_derivative)
- Xét một hàm trả về vector với đầu vào là một vector $h(\mathbf{x}):\mathbb{R}^k \rightarrow \mathbb{R}^n$, đạo hàm bậc nhất của nó là:
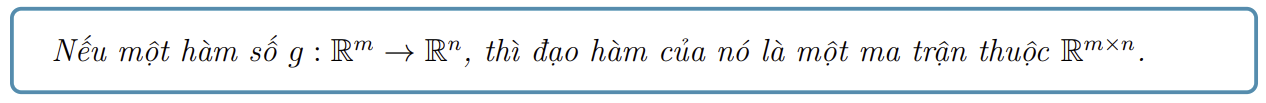
- Đây là code tính đạo hàm bậc nhất của hàm số trên:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from sympy import symbols, Matrix, diff
# Định nghĩa các biến đầu vào (vector đầu vào)
x1, x2 = symbols('x1 x2') # Vector đầu vào có 2 biến
X = Matrix([x1, x2]) # Vector đầu vào
# Định nghĩa hàm đầu vào (vector đầu ra)
def f(X):
x1, x2 = X[0], X[1]
return Matrix([x1**2 + x2, x1 * x2, x2**3])
# Tính đạo hàm bậc nhất (Jacobian)
vector_output = f(X)
jacobian = vector_output.jacobian(X)
print("Jacobian của hàm f(X) là:")
print(jacobian)
- Đạo hàm bậc hai của hàm số trên là một mảng ba chiều, chúng ta sẽ không nhắc đến ở đây.
- Trước khi đến phần tính đạo hàm của các hàm số thường gặp, chúng ta cần biết hai tính chất quan trọng khá giống với đạo hàm của hàm một biến.
3. Tính chất quan trọng của đạo hàm
3.1 Quy tắc tích (Product rule)
- Để cho tổng quát, ta giả sử biến đầu vào là một ma trận. Giả sử rằng các hàm số có chiều phù hợp để các phép nhân thực hiện được. Ta có:
- Biểu thức này giống như biểu thức chúng ta đã quen thuộc:
- Chú ý rằng với tích của vector và ma trận, ta không được sử dụng tính chất giao hoán.
3.2 Quy tắc chuỗi (Chain rule)
- Khi có các hàm hợp thì:
- Quy tắc này cũng giống với quy tắc trong hàm một biến:
- Một lưu ý nhỏ nhưng quan trọng khi làm việc với tích các ma trận là sự phù hợp về kích thước của các ma trận trong tích.
4. Đạo hàm của các hàm số thường gặp
4.1 $f(\mathbf{x}) = \mathbf{a}^T\mathbf{x}$
- Giả sử $\mathbf{a}, \mathbf{x} \in \mathbb{R}^n$, ta viết lại $f(\mathbf{x}) = \mathbf{a}^T\mathbf{x} = a_1 x_1 + a_2 x_2 + \dots + a_nx_n$.
- Có thể nhận thấy rằng $\dfrac{\partial f(\mathbf{x})}{\partial x_i} = a_i, ~\forall i = 1, 2\dots, n$
- Vậy, $ \nabla (\mathbf{a}^T \mathbf{x}) = \begin{bmatrix} a_1 a_2 \dots & a_n \end{bmatrix}^T = \mathbf{a} $. Ngoài ra, vì $\mathbf{a}^T\mathbf{x} = \mathbf{x}^T\mathbf{a}$ nên $\nabla_{\mathbf{x}} (\mathbf{x}^T\mathbf{a}) = \mathbf{a}$.
4.2 $f(\mathbf{x}) = \mathbf{\mathbf{A}\mathbf{x}}$
- Đây là một hàm trả về vector $f: \mathbb{R}^n \rightarrow \mathbb{R}^{m} $ với $\mathbf{x} \in \mathbb{R}^n, \mathbf{A} \in \mathbb{R}^{m\times n}$. Giả sử $\mathbf{a}_i$ là hàng thứ $i$ của ma trận $\mathbf{A}$. Ta có:
- Từ định nghĩa đạo hàm vởi hàm trả về vector với đầu vào là một vector và công thức gradient của $\mathbf{a}_i\mathbf{x}$, có thể suy ra:
- Từ đây suy ra đạo hàm của hàm số $f(\mathbf{x}) = \mathbf{x} = \mathbf{I\mathbf{x}}$ là:
2.4.3 $f(\mathbf{x}) = \mathbf{x}^T\mathbf{A} \mathbf{x}$
Với $\mathbf{x} \in \mathbb{R}^n, \mathbf{A} \in \mathbb{R}^{n\times n}$, áp dụng quy tắc tích ta có:
\[\begin{eqnarray} \nonumber \nabla f(\mathbf{x}) &=& \nabla \left(\left(\mathbf{x}^T\right) \left(\mathbf{Ax}\right)\right) \\\ \nonumber &=& \left(\nabla (\mathbf{x})\right) \mathbf{Ax} + \left(\nabla (\mathbf{Ax})\right)\mathbf{x} \\\ \nonumber & = & \mathbf{IAx} + \mathbf{A}^T\mathbf{x} \\\ \label{eqn:gdxTAx} & = & (\mathbf{A} + \mathbf{A}^T)\mathbf{x}. \end{eqnarray}\]Từ phương trình trên và $\nabla_{\mathbf{x}} ( \mathbf{Ax}) = \begin{bmatrix} \mathbf{a}_1^T & \mathbf{a}_2^T & \dots & \mathbf{a}_m^T \end{bmatrix} = \mathbf{A}^T$, ta có thể suy ra $\nabla^2 \mathbf{x}^T \mathbf{A} \mathbf{x} = \mathbf{A}^T + \mathbf{A}$.
Nếu $\mathbf{A}$ là một ma trận đối xứng, ta có:
- Nếu $\mathbf{A}$ là ma trận đơn vị, tức $f(\mathbf{x}) = \mathbf{x}^T\mathbf{Ix} = \mathbf{x}^T\mathbf{x} = |\mathbf{x}|_2^2$, ta có:
2.4.4 $f(\mathbf{x}) = |\mathbf{Ax} - \mathbf{b}|_2^2 $
- Có hai cách tính gradient của hàm số này:
- Cách 1: Trước hết, biến đổi
- Lấy đạo hàm cho từng số hạng rồi cộng lại ta có:
Cách 2: Sử dụng $\nabla (\mathbf{Ax} - \mathbf{b}) = \mathbf{A}^T$ và $\nabla |\mathbf{x}|_2^2 = 2\mathbf{x}$ và quy tắc chuỗi, ta cũng sẽ thu được kết quả tương tự.
Bảng dưới đây bao gồm đạo hàm của các hàm số thường gặp với biến là vector hoặc ma trận:

5. Kiểm tra đạo hàm
- Việc tính đạo hàm của hàm nhiều biến thông thường khá phức tạp và rất dễ mắc lỗi. Trong thực nghiệm, có một cách để kiểm tra liệu đạo hàm tính được có chính xác không. Cách này dựa trên định nghĩa của đạo hàm cho hàm một biến.
5.1 Xấp xỉ đạo hàm của hàm một biến
- Theo định nghĩa:
- Trên máy tính, ta có thể chọn $\varepsilon$ rất nhỏ, ví dụ $10^{-6}$, rồi xấp xỉ đạo hàm này bởi:
- Trên thực tế, công thức xấp xỉ đạo hàm hai phía thường được sử dụng:
- Cách tính này được gọi là numerical gradient. Biểu thức trên được sử dụng rộng rãi hơn để tính numerical gradient. Có hai cách giải thích cho vấn đề này.
Bằng giải tích
- Sử dụng khai triển Taylor với $\varepsilon$ rất nhỏ, ta có hai xấp xỉ sau:
- Từ đó ta có:
- Trong đó $O()$ là {Big O notation}. Từ đó, nếu xấp xỉ đạo hàm bằng công thức đầu tiên, sai số sẽ là $O(\varepsilon)$. Trong khi đó, nếu xấp xỉ đạo hàm bằng công thức thứ hai, sai số sẽ là $O(\varepsilon^2)$. Khi $\varepsilon$ rất nhỏ, $O(\varepsilon^2) \ll O(\varepsilon)$, tức cách đánh giá sử dụng công thức dưới có sai số nhỏ hơn, và vì vậy nó được sử dụng phổ biến hơn.
Bằng hình học
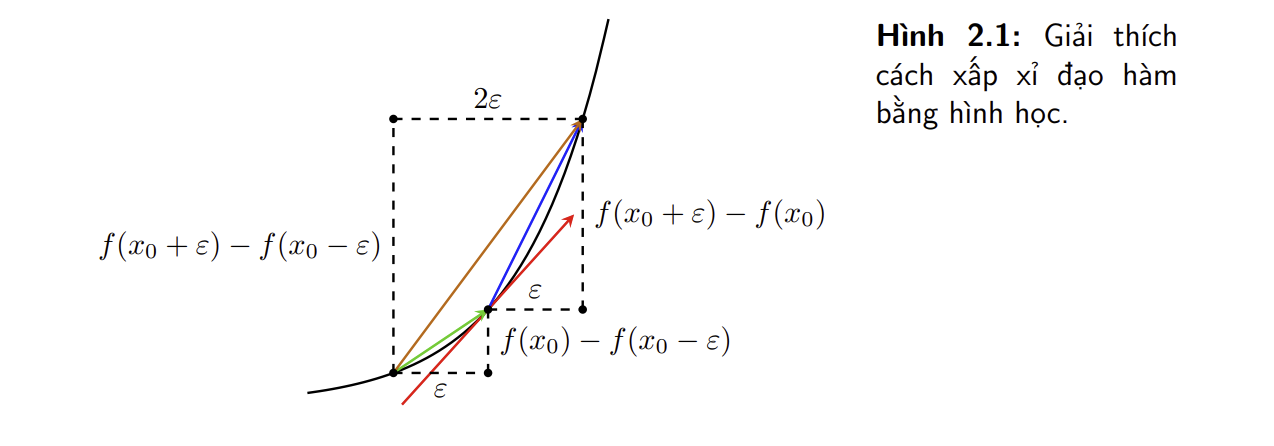
- Quan sát hình trên, vector màu đỏ là đạo hàm chính xác của hàm số tại điểm có hoành độ bằng $x_0$. Vector màu xanh lam và xanh lục lần lượt thể hiện cách xấp xỉ đạo hàm phía phải và phía trái. Vector màu nâu thể hiện cách xấp xỉ đạo hàm hai phía. Trong ba vector xấp xỉ đó, vector xấp xỉ hai phía màu nâu là gần với vector đỏ nhất nếu xét theo hướng.
- Sự khác biệt giữa các cách xấp xỉ còn lớn hơn nữa nếu tại điểm $x$, hàm số bị bẻ cong mạnh hơn. Khi đó, xấp xỉ trái và phải sẽ khác nhau rất nhiều. Xấp xỉ hai bên sẽ ổn định hơn.
- Từ đó ta thấy rằng xấp xỉ đạo hàm hai phía là xấp xỉ tốt hơn
6. Tổng Kết
- Học giải tích ma trận giúp ta hiểu được tại sao khi đạo hàm trên hàm mất mát lại ra được các công thức như trên trong các thuật toán học máy. Nếu chưa hiểu rõ thì hãy đọc lại một lần nữa vì phần này khá quan trọng. Để biết thêm chi tiết, vui lòng tham khảo Chương 2: Giải tích ma trận trong sách Machine Learning Cơ Bản