Hello Transformers
- Vào năm 2017, các nhà nghiên cứu tại Google đã xuất bản một bài báo đề xuất một kiến trúc mạng nơ-ron mới để mô hình hóa trình tự (paper). Được đặt tên là
Transformer, kiến trúc này vượt trội hơn các Recurrent Neural Wetworks (RNN) trong các tác vụ dịch máy, cả về chất lượng dịch thuật và chi phí đào tạo. - Cùng lúc đó, có một phương pháp học chuyển giao hiệu quả (transfer learning) có tên là
ULMFiT(paper) cho thấy rằng việc đào tạo Long Short-Term Memory (LSTM) Networks trên một kho dữ liệu rất lớn và đa dạng có thể tạo ra một mô hình phân loại văn bản đạt ngưỡng state-of-the-art (SOTA) với ít dữ liệu được gắn nhãn sẵn. - Những tiến bộ này là chất xúc tác cho hai trong số những transformers tiếng nhất hiện nay:
Generative Pretrained Transformer(GPT) vàBidirectional Encoder Representations from Transformers(BERT). Bằng cách kết hợp kiến trúc Transformer với học không giám sát, các mô hình này không cần phải train từ những task cụ thể từ đầu và phá vỡ hầu hết mọi benchmark trong NLP với khoảng cách đáng kể. Kể từ khi phát hành GPT và BERT, rât nhiều các mô hình dựa trên kiến trúc transformer đã xuất hiện; dòng thời gian của các kiến trúc nổi bật nhất được thể hiện trong Hình 1-1.
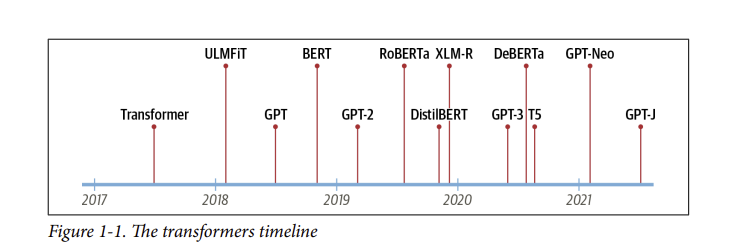
- Nhưng có vẻ chúng ta đang đi hơi nhanh. Để hiểu điều gì mới lạ về transformer, trước tiên chúng ta cần phải tìm hiểu:
- The encoder-decoder framework.
- Cơ chế chú ý.
- học chuyển giao (Transfer learning).
Trong blog này, chúng ta sẽ giới thiệu các khái niệm cốt lõi làm nền tảng cho sự phổ biến của transformer, xem xét một số task mà chúng vượt trội và kết thúc bằng cách xem xét hệ sinh thái của Hugging Face gồm các công cụ và thư viện.
- Hãy bắt đầu bằng cách khám phá The encoder-decoder framework và các kiến trúc của transformer.
1. The Encoder-Decoder Framework
- Trước khi có transformer, các kiến trúc lặp lại như LSTM là SOTA trong NLP. Các kiến trúc này chứa một vòng phản hồi (feedback loop) trong các kết nối mạng cho phép thông tin lan truyền từ bước này sang bước khác, khiến chúng trở nên lý tưởng để mô hình hóa dữ liệu tuần tự như văn bản. Như minh họa ở phía bên trái của Hình 1-2, một RNN nhận được một số đầu vào (có thể là một từ hoặc ký tự), input đi qua mạng và xuất ra một vectơ được gọi là trạng thái ẩn (hidden state). Đồng thời, mô hình cung cấp một số thông tin trở lại chính nó thông qua vòng phản hồi (feedback loop), sau đó nó có thể sử dụng trong bước tiếp theo. Điều này có thể được nhìn thấy rõ ràng hơn nếu chúng ta “mở cuộn” (unroll) vòng lặp như thể hiện ở phía bên phải của Hình 1-2: RNN chuyển thông tin về trạng thái của nó ở mỗi bước sang hoạt động tiếp theo trong trình tự. Điều này cho phép RNN theo dõi thông tin từ các bước trước đó và sử dụng nó cho các dự đoán đầu ra của nó.
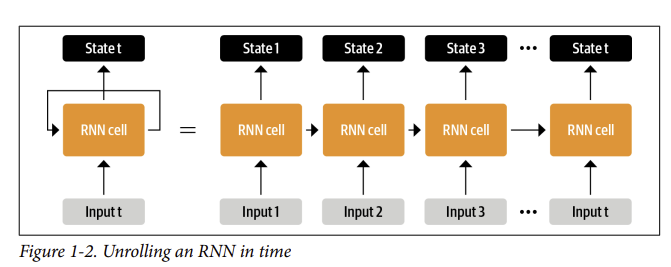
- Các kiến trúc này đã (và tiếp tục) được sử dụng rộng rãi cho các tác vụ NLP, xử lý giọng nói và chuỗi thời gian. Bạn có thể tìm thấy một giải thích tuyệt vời về khả năng của chúng trong bài đăng trên blog của Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks (có thể trong tương lai tôi sẽ dịch lại blog này).
- Một lĩnh vực mà RNN đóng một vai trò quan trọng là trong việc phát triển các hệ thống dịch máy, trong đó mục tiêu là ánh xạ một chuỗi các từ trong ngôn ngữ này sang ngôn ngữ khác. Loại nhiệm vụ này thường được giải quyết bằng bộ mã hóa-giải mã (encoder-decoder) hoặc kiến trúc trình tự đến trình tự (sequence-to-sequence), rất phù hợp cho các tình huống mà đầu vào và đầu ra đều là chuỗi có độ dài tùy ý. Công việc của bộ mã hóa là mã hóa thông tin từ chuỗi đầu vào thành một biểu diễn số thường được gọi là trạng thái ẩn cuối cùng (last hidden state). Trạng thái này sau đó được chuyển đến bộ giải mã, tạo ra trình tự đầu ra.
- Nói chung, các thành phần của bộ mã hóa và bộ giải mã có thể là bất kỳ loại kiến trúc mạng nơ-ron nào có thể mô hình hóa các chuỗi. Ví dụ được minh họa cho một cặp RNNs trong Hình 1-3, trong đó câu tiếng Anh “Transformers are great!” được mã hóa dưới dạng một vectơ trạng thái ẩn (hidden state) sau đó được giải mã để tạo ra bản dịch tiếng Đức “Transformer sind grossartig!” Các từ đầu vào được cung cấp tuần tự thông qua bộ mã hóa và các từ đầu ra được tạo từng từ một, từ trên xuống dưới.
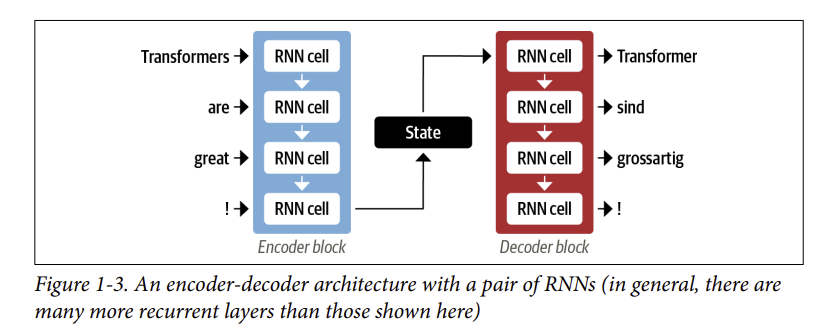
- Mặc dù nó đơn giản, một điểm yếu của kiến trúc này là trạng thái ẩn cuối cùng (final hidden state) của bộ mã hóa tạo ra một nút thắt cổ chai: nó phải đại diện cho ý nghĩa của toàn bộ chuỗi đầu vào vì đây là tất cả những gì bộ giải mã có quyền truy cập khi tạo đầu ra. Điều này đặc biệt khó khăn đối với các chuỗi dài, nơi thông tin ở đầu chuỗi có thể bị mất trong quá trình nén mọi thứ thành một biểu diễn cố định duy nhất.
- May mắn thay, có một cách thoát khỏi nút thắt cổ chai này bằng cách cho phép bộ giải mã có quyền truy cập vào tất cả các trạng thái ẩn của bộ mã hóa. Cơ chế chung cho điều này được gọi là Cơ chế chú ý (paper) và nó là một thành phần quan trọng trong nhiều kiến trúc mạng nơ-ron hiện đại. Hiểu được cơ chế chú ý được phát triển như thế nào đối với RNN sẽ giúp chúng ta hiểu được một trong những khối xây dựng chính của kiến trúc Transformer. Chúng ta hãy xem xét sâu hơn thôi nào.
2. Cơ chế chú ý (Attention Mechanisms)
- Ý tưởng chính đằng sau cơ chế chú ý là thay vì tạo ra một trạng thái ẩn duy nhất cho chuỗi đầu vào, bộ mã hóa xuất ra một trạng thái ẩn ở mỗi bước mà bộ giải mã có thể truy cập. Tuy nhiên, việc sử dụng tất cả các trạng thái cùng một lúc sẽ tạo ra một đầu vào khổng lồ cho bộ giải mã, vì vậy cần có một cơ chế để ưu tiên sử dụng trạng thái nào. Đây là lúc cơ chế chú ý xuất hiện: nó cho phép bộ giải mã gán các trọng lượng khác nhau, hoặc “chú ý”, cho từng trạng thái bộ mã hóa ở mỗi bước giải mã. Quá trình này được minh họa trong Hình 1-4:
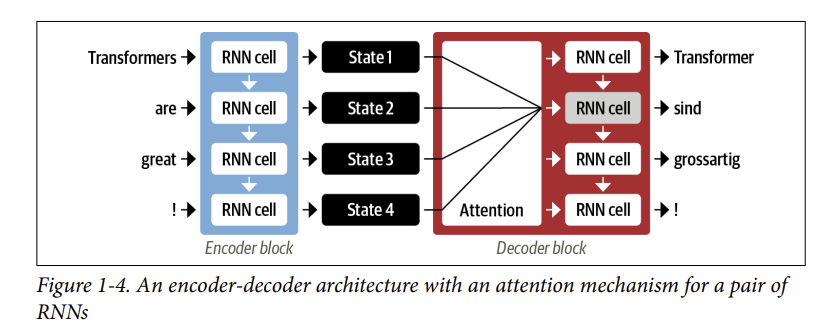
- Bằng cách tập trung vào mã thông báo đầu vào nào có liên quan nhất tại mỗi bước giải mã, các mô hình dựa trên sự chú ý này có thể tìm hiểu sự liên kết không tầm thường giữa các từ trong câu đã được dịch và các từ trong câu gốc. Ví dụ, Hình 1-5 trực quan hóa trọng số chú ý cho mô hình dịch tiếng Anh sang tiếng Pháp, trong đó mỗi pixel biểu thị một trọng lượng. Hình ảnh cho thấy cách bộ giải mã có thể căn chỉnh chính xác các từ “zone” và “Area”, mặc dù các từ này ở vị trí khác nhau trong câu tiếng Anh và tiếng Pháp.

- Mặc dù cơ chế chú ý cho phép tạo ra các bản dịch tốt hơn, nhưng vẫn có một thiếu sót lớn khi sử dụng các mô hình lặp lại (như RNN) cho bộ mã hóa và bộ giải mã: Nếu sử dụng RNN thì phải mã hóa tuần tự từng token của câu đầu vào chứ không thể mã hóa cùng một lúc, song song tất cả token.
- Với transformer, một kiến trúc mô hình mới đã được giới thiệu: loại bỏ hoàn toàn sự lặp lại, và thay vào đó dựa hoàn toàn vào một hình thức chú ý đặc biệt được gọi là tự chú ý (self-attention). Chúng ta sẽ đề cập đến self-attention vào blog khác, nhưng ý tưởng cơ bản là cho phép sự chú ý hoạt động trên tất cả các trạng thái trong cùng một lớp của mạng thần kinh. Điều này được thể hiện trong Hình 1-6, trong đó cả bộ mã hóa và bộ giải mã đều có cơ chế tự chú ý riêng, có đầu ra được đưa vào các feed-forward neural networks (FFNN). Kiến trúc này có thể được train nhanh hơn nhiều so với các mô hình lặp lại (recurrent models ) và mở đường cho nhiều đột phá gần đây trong NLP.
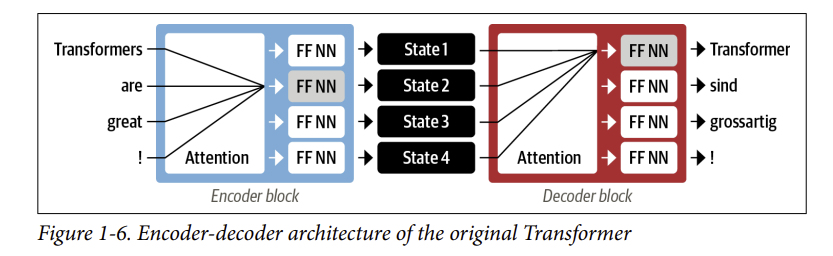
- Trong bài báo gốc của Transformer, mô hình dịch thuật được đào tạo từ đầu trên một kho dữ liệu lớn các cặp câu bằng nhiều ngôn ngữ khác nhau. Tuy nhiên, trong nhiều ứng dụng thực tế của NLP, chúng ta không có quyền truy cập vào một lượng lớn dữ liệu văn bản được gắn nhãn để đào tạo các mô hình của chúng ta. Tiếp theo chúng ta sẽ nói về học chuyển giao (transfer learning)
3. học chuyển giao trong NLP
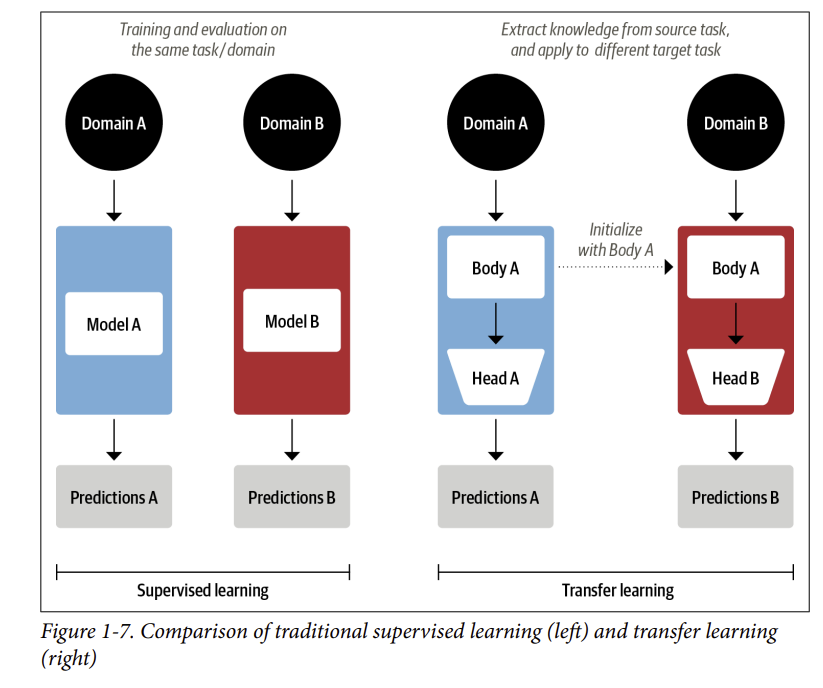
- Ngày nay, cách làm phổ biến trong thị giác máy tính là sử dụng học chuyển giao để đào tạo một mạng nơ-ron tích chập như ResNet trên một nhiệm vụ, sau đó điều chỉnh nó hoặc tinh chỉnh nó trên một nhiệm vụ mới. Điều này cho phép mạng sử dụng kiến thức học được từ nhiệm vụ ban đầu. Về mặt kiến trúc, điều này liên quan đến việc tách mô hình thành hai phần: một body và một head, trong đó head là một mạng lưới dành riêng cho nhiệm vụ cụ thể. Trong quá trình đào tạo, trọng số của body học các đặc điểm hữu ích của nhiệm vụ trước đó và các trọng số này được sử dụng để khởi tạo một mô hình mới cho nhiệm vụ mới. So với học có giám sát truyền thống, cách tiếp cận này thường tạo ra các mô hình chất lượng cao có thể được train hiệu quả hơn nhiều trên nhiều nhiệm vụ downstream và với ít dữ liệu được gắn nhãn hơn nhiều. So sánh hai cách tiếp cận được thể hiện trong Hình 1-7.
Trong thị giác máy tính, các mô hình đầu tiên sẽ được train trên các bộ dữ liệu quy mô lớn như ImageNet, chứa hàng triệu hình ảnh. Quá trình này được gọi là pretraining và mục đích chính của nó là dạy cho mô hình các tính năng cơ bản của hình ảnh, chẳng hạn như cạnh hoặc màu sắc. Các mô hình được đào tạo trước này sau đó có thể được tinh chỉnh theo một nhiệm vụ downstream như phân loại các loài hoa. Các mô hình được tinh chỉnh thường đạt được độ chính xác cao hơn so với các mô hình được train từ đầu trên cùng một lượng dữ liệu được gắn nhãn.
- Mặc dù học chuyển giao đã trở thành cách tiếp cận tiêu chuẩn trong thị giác máy tính, nhưng trong nhiều năm, người ta không rõ học chuyển giao tương tự cho NLP là gì. Do đó, các ứng dụng NLP thường yêu cầu một lượng lớn dữ liệu được gắn nhãn để đạt được hiệu suất cao. Và ngay cả thế, hiệu suất của các mô hình NLP đó cũng không thể so sánh với những gì mô hình khác đạt được trong lĩnh vực thị giác máy tính.
- Vào năm 2017 và 2018, một số nhóm nghiên cứu đã đề xuất các phương pháp tiếp cận mới đã làm cho học chuyển giao hoạt động trên NLP. Nó bắt đầu từ cái nhìn sâu sắc từ các nhà nghiên cứu tại OpenAI, những người đã đạt được hiệu suất mạnh mẽ trong nhiệm vụ phân loại cảm xúc bằng cách sử dụng các tính năng được trích xuất từ unsupervised pretraining (paper). Tiếp theo là ULMFiT, giới thiệu một framework chung để điều chỉnh các mô hình LSTM được đào tạo trước cho các nhiệm vụ khác nhau (Một công trình gần đây là ELMo (Embeddings from Language Models), cho thấy LSTM đào tạo trước có thể tạo ra các word embeddings chất lượng cao cho các nhiệm vụ downstream).
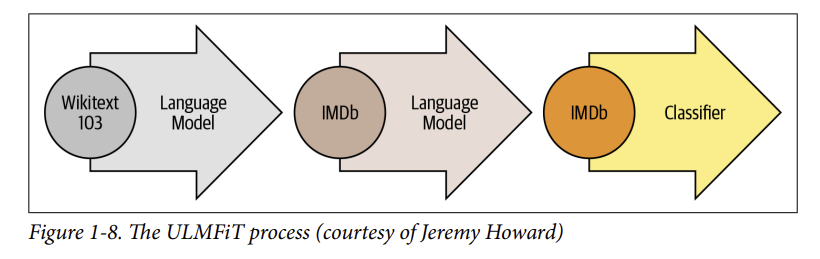
- Như minh họa trong Hình 1-8, ULMFiT bao gồm ba bước chính:
- Pretraining: Mục tiêu train ban đầu khá đơn giản: dự đoán từ tiếp theo dựa trên các từ trước đó. Nhiệm vụ này được gọi là mô hình hóa ngôn ngữ (language modeling). Sự hay ho của cách tiếp cận này nằm ở chỗ không cần dữ liệu được gắn nhãn và người ta có thể sử dụng văn bản có sẵn phong phú từ các nguồn như Wikipedia (Điều này đúng với tiếng Anh hơn là đối với hầu hết các ngôn ngữ trên thế giới, nơi có thể khó khăn để có được một kho dữ liệu lớn văn bản được số hóa. Tìm cách thu hẹp khoảng cách này là một lĩnh vực tích cực của nghiên cứu và hoạt động NLP).
- Domain adaptation: Một khi mô hình ngôn ngữ được đào tạo trước trên một kho dữ liệu quy mô lớn, bước tiếp theo là điều chỉnh nó cho phù hợp với kho dữ liệu mà bạn quan tâm (ví dụ: Mô hình được train trên Wikipedia và dữ liệu mà bạn quan tâm là các bài đánh giá phim trên IMDb, như trong Hình 1-8). Giai đoạn này vẫn sử dụng mô hình ngôn ngữ, nhưng bây giờ mô hình phải dự đoán từ tiếp theo trong kho dữ liệu mà bạn đang quan tâm.
- Fine-tuning: Trong bước này, mô hình ngôn ngữ được tinh chỉnh với một lớp phân loại nằm ở cuối mô hình cho nhiệm vụ cụ thể (ví dụ: phân loại cảm xúc của các bài đánh giá phim trong Hình 1-8).
Bằng cách giới thiệu một framework khả thi để pretraining và học chuyển giao (transfer learning) trong NLP, ULMFiT như một bệ phóng làm cho kiến trúc transformers cất cánh. Vào năm 2018, hai kiến trúc transformers kết hợp sự tự chú ý (self-attention) với học chuyển giao được ra mắt:
- GPT: Chỉ sử dụng phần bộ giải mã (decoder) của kiến trúc Transformer và cách tiếp cận mô hình hóa ngôn ngữ (language modeling) tương tự như ULMFiT. GPT đã được pretrain trên BookCorpus (paper) bao gồm 7.000 cuốn sách chưa xuất bản thuộc nhiều thể loại khác nhau bao gồm Phiêu lưu, Giả tưởng và Lãng mạn.
- BERT: Sử dụng phần bộ mã hóa (encoder) của kiến trúc Transformer và một hình thức mô hình ngôn ngữ đặc biệt được gọi là mô hình ngôn ngữ mặt nạ (masked language modeling). Mục tiêu của masked language modeling là dự đoán các từ được che giấu ngẫu nhiên trong một văn bản. Ví dụ: cho một câu như “Tôi đã nhìn vào [MASK] của tôi và thấy rằng [MASK] đã muộn”, mô hình cần dự đoán các từ có khả năng nhất cho các từ được che giấu được ký hiệu bằng [MASK]. BERT đã được đào tạo trước trên BookCorpus và Wikipedia tiếng Anh.
GPT và BERT đã tạo ra SOTA mới trên nhiều điểm chuẩn NLP và mở ra kỷ nguyên của Transformers.
4. Hugging Face Transformers: Thu hẹp khoảng cách
- Áp dụng kiến trúc học máy mới cho một nhiệm vụ mới có thể là một công việc phức tạp và thường bao gồm các bước sau:
- Triển khai kiến trúc mô hình trong code, thường dựa trên PyTorch hoặc TensorFlow.
- Load các pretrained weights (nếu có sẵn) từ server.
- Xử lý trước các đầu vào, chuyển chúng qua mô hình và áp dụng một số xử lý cho đầu ra (dành riêng cho mỗi nhiệm vụ cụ thể).
- Triển khai bộ nạp dữ liệu (dataloaders) và xác định hàm mất mát (loss functions) và trình tối ưu hóa (optimizers) để train mô hình.
- Mỗi bước này yêu cầu logic tùy chỉnh cho từng mô hình và nhiệm vụ. Thường thì (nhưng không phải lúc nào cũng thế), khi các nhóm nghiên cứu xuất bản một bài báo mới, họ cũng sẽ phát hành code cùng với trọng số mô hình. Tuy nhiên, code này hiếm khi có thể dùng ngay được và thường cần nhiều ngày chỉnh sửa để có thể sử dụng được.
- Đây chính là lúc 🤗 Transformers trở thành cứu cánh cho các nhà thực hành NLP! Thư viện này cung cấp một giao diện tiêu chuẩn hóa cho nhiều mô hình transformer khác nhau, cùng với code và công cụ để điều chỉnh các mô hình này cho những trường hợp sử dụng mới. Hiện tại, thư viện hỗ trợ ba framework học sâu chính (PyTorch, TensorFlow và JAX) và cho phép bạn dễ dàng chuyển đổi giữa chúng. Ngoài ra, nó còn cung cấp các thành phần đặc thù theo nhiệm vụ, giúp bạn dễ dàng tinh chỉnh các transformer cho các tác vụ downstream như phân loại văn bản (text classification), nhận dạng thực thể có tên (named entity recognition), và trả lời câu hỏi (question answering). Điều này giúp giảm thời gian cần thiết để một nhà thực hành train và test một số mô hình từ vài tuần xuống chỉ còn một buổi chiều!
- Bạn sẽ tự mình thấy điều này trong phần tiếp theo, nơi chúng ta chỉ cần với một vài dòng code, 🤗 Transformers có thể được áp dụng để giải quyết một số ứng dụng NLP phổ biến nhất mà bạn có thể gặp phải trong tự nhiên.
5. Các ứng dụng Transformer phổ biến
- Mỗi nhiệm vụ NLP đều bắt đầu bằng một đoạn văn bản, ví dụ như feedback của khách hàng:
1
2
3
4
5
6
7
text = """Dear Amazon, last week I ordered an Optimus Prime action figure
from your online store in Germany. Unfortunately, when I opened the package,
I discovered to my horror that I had been sent an action figure of Megatron
instead! As a lifelong enemy of the Decepticons, I hope you can understand my
dilemma. To resolve the issue, I demand an exchange of Megatron for the
Optimus Prime figure I ordered. Enclosed are copies of my records concerning
this purchase. I expect to hear from you soon. Sincerely, Bumblebee."""
- Tùy thuộc vào ứng dụng của bạn, văn bản bạn đang làm việc có thể là hợp đồng pháp lý, mô tả sản phẩm hoặc một cái gì đó hoàn toàn khác. Trong trường hợp phản hồi của khách hàng, bạn có thể muốn biết phản hồi là tích cực hay tiêu cực. Nhiệm vụ này được gọi là phân tích cảm xúc (sentiment analysis) và là một phần của chủ đề rộng hơn là phân loại văn bản (text classification). Bây giờ, chúng ta hãy xem những gì cần thiết để trích xuất cảm xúc từ đoạn văn bản của chúng ta bằng cách sử dụng 🤗 Transformers.
Phân loại văn bản (Text Classification)
- 🤗 Transformers có một API phân lớp cho phép bạn tương tác với thư viện ở nhiều mức độ trừu tượng khác nhau. Trong chương này, chúng ta sẽ bắt đầu với
pipeline, một công cụ trừu tượng hóa tất cả các bước cần thiết để chuyển đổi văn bản thô thành một tập hợp dự đoán từ một mô hình đã được tinh chỉnh (fine-tuned model).
Trong 🤗 Transformers, chúng ta khởi tạo một pipeline bằng cách gọi hàm pipeline() và cung cấp tên của tác vụ mà chúng ta quan tâm:
1
2
from transformers import pipeline
classifier = pipeline("text-classification")
- Lần đầu tiên bạn chạy code này, bạn sẽ thấy một vài thanh tiến trình xuất hiện vì
pipelinetự động tải xuống trọng số mô hình từ Hub Hugging Face. Lần thứ hai bạn khởi tạo quy trình, thư viện sẽ nhận thấy rằng bạn đã tải xuống trọng số và sẽ sử dụng phiên bản được lưu trong bộ nhớ đệm để thay thế. Theo mặc định, text-classification pipeline sử dụng mô hình được thiết kế để phân tích cảm xúc, nhưng nó cũng hỗ trợ phân loại đa lớp và đa nhãn. - Bây giờ chúng ta đã có
pipelinecủa mình, hãy tạo ra một số dự đoán! Mỗipipelinelấy một chuỗi văn bản (hoặc danh sách các chuỗi) làm đầu vào và trả về danh sách các dự đoán. Mỗi dự đoán là một từ điển Python, vì vậy chúng ta có thể sử dụngPandasđể hiển thị chúng một cách đẹp đẽ dưới dạngDataFrame:

- Trong trường hợp này, mô hình rất tự tin rằng văn bản có cảm xúc tiêu cực, điều này có ý nghĩa khi chúng ta đang giải quyết khiếu nại từ một khách hàng tức giận! Lưu ý rằng đối với các tác vụ phân tích cảm xúc,
pipelinechỉ trả về một trong hai nhãn POSITIVE hoặc NEGATIVE, vì nhãn còn lại có thể được suy ra bằng cách tính 1 - score. - Bây giờ chúng ta hãy xem xét một nhiệm vụ phổ biến khác, xác định các thực thể được đặt tên trong văn bản.
Nhận dạnng thực thể được đặt tên (Named Entity Recognition)
- Dự đoán cảm xúc về phản hồi của khách hàng là bước khởi đầu tốt, nhưng bạn thường muốn biết liệu phản hồi có liên quan đến một mặt hàng hoặc dịch vụ cụ thể hay không. Trong NLP, các đối tượng trong thế giới thực như sản phẩm, địa điểm hoặc con người được gọi là thực thể được đặt tên (named entities) và trích xuất chúng từ văn bản được gọi là nhận dạng thực thể được đặt tên (NER). Chúng tôi có thể áp dụng NER bằng cách tải
pipelinetương ứng:
1
2
3
ner_tagger = pipeline("ner", aggregation_strategy="simple")
outputs = ner_tagger(text)
pd.DataFrame(outputs)
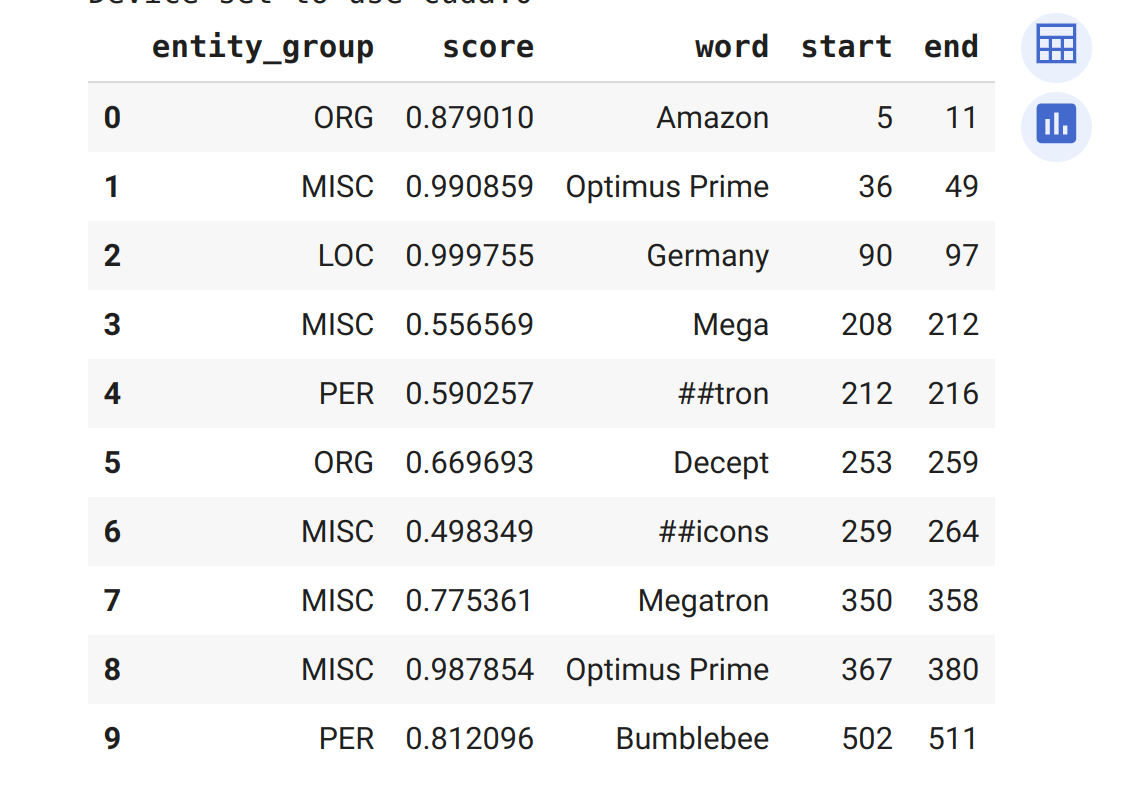
- Bạn có thể thấy rằng
pipelineđã phát hiện tất cả các thực thể và cũng gán một danh mục nhưORG(tổ chức),LOC(địa điểm) hoặcPER(người) cho mỗi thực thể đó. Ở đây, chúng tôi đã sử dụng tham sốaggregation_strategyđể nhóm các từ theo dự đoán của mô hình. Ví dụ, thực thể “Optimus Prime” được tạo thành từ hai từ, nhưng được gán một danh mục duy nhất: MISC (loại khác). Các điểm số cho chúng ta biết mô hình tự tin đến mức nào về các thực thể mà nó nhận diện. Chúng ta có thể thấy rằng mô hình ít tự tin nhất về “Decepticons” và từ “Mega”, cả hai đều không được nhóm thành một thực thể duy nhất.
Thấy những ký hiệu # trong cột từ ở bảng trên không? Chúng được tạo ra bởi tokenizer của mô hình, chia các từ thành các đơn vị nhỏ được gọi là token. Bạn sẽ tìm hiểu tất cả về cái này ở blog khác.
- Trích xuất tất cả các thực thể được đặt tên trong một văn bản thật tuyệt, nhưng đôi khi chúng ta muốn đặt câu hỏi về văn bản. Đấy là là lúc chúng ta đi tới nhiệm vụ nữa là trả lời câu hỏi (question answering).
Trả lời câu hỏi (Question Answering)
- Trong trả lời câu hỏi, chúng ta cung cấp cho mô hình một đoạn văn bản được gọi là ngữ cảnh (context), cùng với một câu hỏi mà chúng ta muốn mô hình câu trả lời. Sau đó, mô hình trả về khoảng văn bản tương ứng với câu trả lời. Hãy xem chúng ta nhận được gì khi đặt một câu hỏi cụ thể về phản hồi của khách hàng:
1
2
3
4
reader = pipeline("question-answering")
question = "What does the customer want ?"
outputs = reader(question = question, context = text)
pd.DataFrame([outputs])

Chúng ta có thể thấy rằng cùng với câu trả lời,
pipelinecũng trả về các chỉ số bắt đầu và kết thúc tương ứng câu trả lời (giống như NER). Loại đặc biệt này được gọi là trả lời câu hỏi trích xuất từ văn bản (extractive question answering) vì câu trả lời được trích xuất trực tiếp từ văn bản. Tất nhiên, đây có thể là câu trả lời không tốt cho các câu hỏi khác nhau, tôi sẽ viết một blog khác chi tiết hơn về question answering mà model có thể tự do trả lời câu hỏi.Với cách tiếp cận này, bạn có thể đọc và trích xuất thông tin liên quan một cách nhanh chóng từ phản hồi của khách hàng. Nhưng điều gì sẽ xảy ra nếu bạn nhận được một núi những lời phàn nàn dài dòng và bạn không có thời gian để đọc tất cả? Hãy xem liệu một mô hình tóm tắt có thể giúp ích hay không !
Tóm tắt (Summarization)
- Mục tiêu của tóm tắt văn bản là lấy một văn bản dài làm đầu vào và tạo ra một phiên bản ngắn với tất cả các sự kiện có liên quan. Đây là một nhiệm vụ phức tạp hơn nhiều so với những nhiệm vụ trước đây vì nó yêu cầu mô hình tạo ra văn bản mạch lạc. Chúng ta có thể khởi tạo một
pipelinenhư sau:
1
2
3
4
5
6
summarizer = pipeline("summarization")
outputs = summarizer(text, max_length=45, clean_up_tokenization_spaces=True)
print(outputs[0]['summary_text'])
# Outpus: Bumblebee ordered an Optimus Prime action figure from your online store in
#Germany. Unfortunately, when I opened the package, I discovered to my horror
#that I had been sent an action figure of Megatron instead.
- Bản tóm tắt này không quá tệ! Mặc dù một phần của văn bản gốc đã được sao chép, mô hình đã có thể nắm bắt được bản chất của vấn đề và xác định chính xác rằng “Bumblebee” (xuất hiện ở cuối) là tác giả của khiếu nại. Trong ví dụ này, bạn cũng có thể thấy rằng chúng ta đã chuyển tham số như
max_lengthvàclean_up_tokenization_spacesvàopipeline. Điều này cho phép chúng ta điều chỉnh output trong thời gian chạy. - Nhưng điều gì sẽ xảy ra khi bạn nhận được phản hồi bằng ngôn ngữ mà bạn không hiểu? Bạn có thể sử dụng Google Dịch hoặc bạn có thể sử dụng transformer của riêng mình để chuyển đổi nó cho bạn !
Dịch văn bản (Translation)
- Giống như tóm tắt, dịch văn bản là một nhiệm vụ trong đó đầu ra bao gồm văn bản được dịch. Hãy sử dụng một
pipelineđể dịch một văn bản tiếng Anh sang tiếng Đức:
1
2
3
4
5
6
7
8
9
10
11
12
13
translator = pipeline("translation_en_to_de",
model="Helsinki-NLP/opus-mt-en-de")
outputs = translator(text, clean_up_tokenization_spaces=True, min_length=100)
print(outputs[0]['translation_text'])
# Output: Sehr geehrter Amazon, letzte Woche habe ich eine Optimus Prime Action Figur aus
# Ihrem Online-Shop in Deutschland bestellt. Leider, als ich das Paket öffnete,
# entdeckte ich zu meinem Entsetzen, dass ich stattdessen eine Action Figur von
# Megatron geschickt worden war! Als lebenslanger Feind der Decepticons, Ich
# hoffe, Sie können mein Dilemma verstehen. Um das Problem zu lösen, Ich fordere
# einen Austausch von Megatron für die Optimus Prime Figur habe ich bestellt.
# Anbei sind Kopien meiner Aufzeichnungen über diesen Kauf. Ich erwarte, bald von
# Ihnen zu hören. Aufrichtig, Bumblebee.
- Một lần nữa, mô hình này đã tạo ra một bản dịch rất tốt sử dụng chính xác các đại từ chính thức của tiếng Đức, như “Ihrem” và “Sie”. Ở đây chúng ta cũng đã chỉ ra cách bạn có thể ghi đè mô hình mặc định trong
pipelineđể chọn mô hình tốt nhất cho ứng dụng của bạn — và bạn có thể tìm thấy mô hình cho hàng nghìn cặp ngôn ngữ trên Hugging Face Hub. Trước khi chúng ta lùi lại một bước và xem xét toàn bộ hệ sinh thái Hugging Face, chúng ta hãy xem xét một ứng dụng cuối cùng.
Tạo văn bản (Text Generation)
- Giả sử bạn muốn có thể trả lời phản hồi nhanh hơn cho phản hồi của khách hàng bằng cách có quyền truy cập vào chức năng tự động hoàn thành. Với mô hình tạo văn bản, bạn có thể thực hiện việc này như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
generator = pipeline("text-generation")
response = "Dear Bumblebee, I am sorry to hear that your order was mixed up."
prompt = text + "\n\nCustomer service response:\n" + response
outputs = generator(prompt, max_length=200)
print(outputs[0]['generated_text'])
# Ouput:
# Dear Amazon, last week I ordered an Optimus Prime action figure from your online
# store in Germany. Unfortunately, when I opened the package, I discovered to my
# horror that I had been sent an action figure of Megatron instead! As a lifelong
# enemy of the Decepticons, I hope you can understand my dilemma. To resolve the
# issue, I demand an exchange of Megatron for the Optimus Prime figure I ordered.
# Enclosed are copies of my records concerning this purchase. I expect to hear
# from you soon. Sincerely, Bumblebee.
# Customer service response:
# Dear Bumblebee, I am sorry to hear that your order was mixed up. The order was
# completely mislabeled, which is very common in our online store, but I can
# appreciate it because it was my understanding from this site and our customer
# service of the previous day that your order was not made correct in our mind and
# that we are in a process of resolving this matter. We can assure you that your
# order
- Bây giờ bạn đã thấy một vài ứng dụng thú vị của các mô hình transformers, bạn có thể tự hỏi việc training diễn ra ở đâu. Tất cả các mô hình mà chúng ta đã sử dụng trong blog này đều có sẵn công khai và đã được fine-tuned cho nhiệm vụ cụ thể. Tuy nhiên, nói chung, bạn sẽ muốn fine-tuned các mô hình trên dữ liệu của riêng mình và trong các blog khác, bạn sẽ học cách thực hiện điều đó.
- Nhưng train một mô hình chỉ là một phần nhỏ của bất kỳ dự án NLP nào — có thể xử lý dữ liệu một cách hiệu quả, chia sẻ kết quả với người khác và làm cho công việc của bạn có thể tái tạo cũng là những thành phần quan trọng. May mắn thay, 🤗 Transformers được bao quanh bởi một hệ sinh thái lớn gồm các công cụ hữu ích hỗ trợ phần lớn
pipelinehọc máy hiện đại. Chúng ta hãy xem xét.
6. The Hugging Face Ecosystem
- Những gì bắt đầu với 🤗 Transformers đã nhanh chóng phát triển thành một hệ sinh thái bao gồm nhiều thư viện và công cụ để tăng tốc các dự án NLP và máy học của bạn. Hệ sinh thái Hugging Face chủ yếu bao gồm hai phần: một họ thư viện (libraries) và Hub, như thể hiện trong Hình 1-9. Các thư viện cung cấp code trong khi Hub cung cấp trọng số mô hình được đào tạo trước, tập dữ liệu, tập lệnh cho các chỉ số đánh giá (metrics), v.v. Trong phần này, chúng ta sẽ có một cái nhìn ngắn gọn về các thành phần khác nhau.
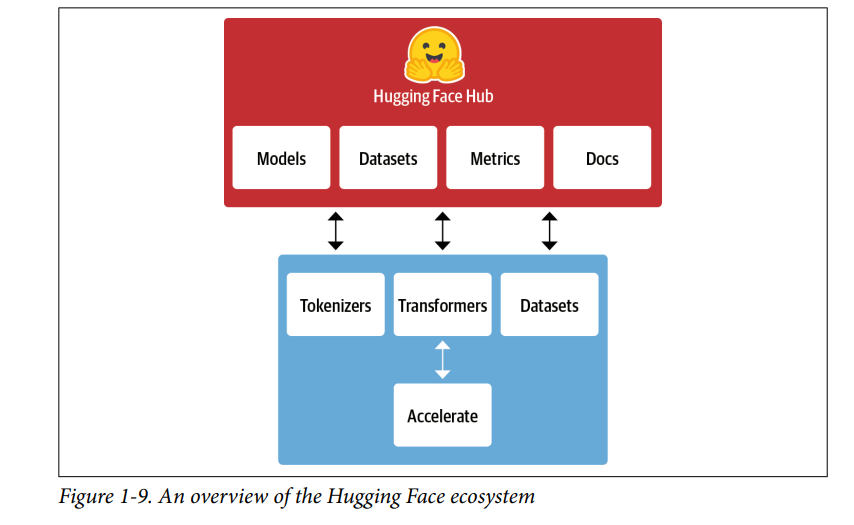
The Hugging Face Hub
- Như đã nêu trước đó, học chuyển giao là một trong những yếu tố quan trọng thúc đẩy sự thành công của transformers vì nó cho phép sử dụng lại các mô hình được đào tạo trước cho các nhiệm vụ mới. Do đó, điều quan trọng là có thể tải các mô hình được đào tạo trước một cách nhanh chóng và chạy thử nghiệm với chúng.
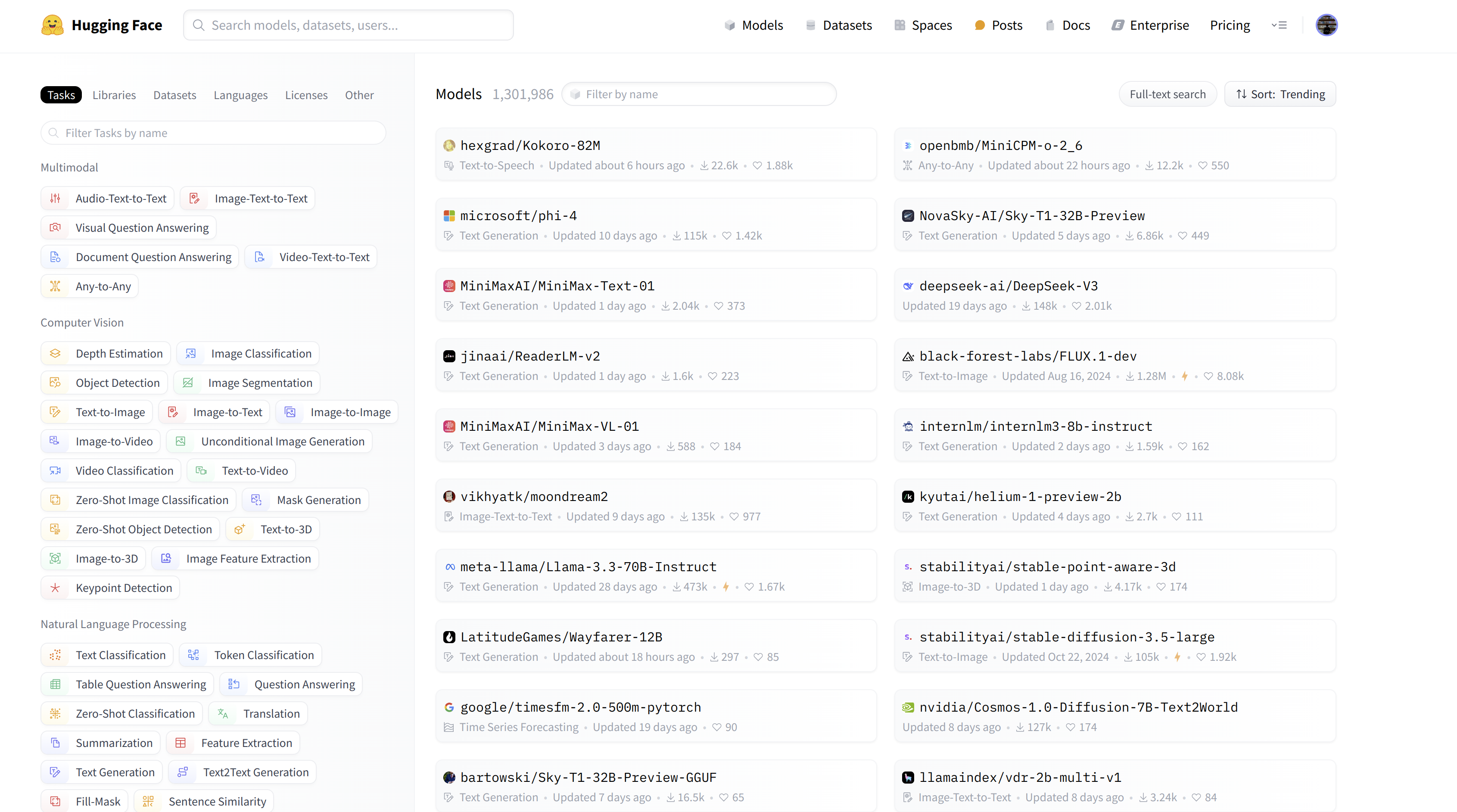
- Hugging Face Hub lưu trữ gần 1.5 triệu mô hình có sẵn miễn phí. Như trong hình dưới, có các filters cho các tasks, framework, dataset, v.v. được thiết kế để giúp bạn điều hướng Hub và nhanh chóng tìm thấy các công cụ bạn muốn. Như chúng ta đã thấy với
pipeline, việc tải một mô hình trong code của bạn thực sự chỉ cần một dòng code. Điều này làm cho việc thử nghiệm với một loạt các mô hình trở nên đơn giản và cho phép bạn tập trung vào các phần khác của dự án.
Ngoài trọng số mô hình, Hub cũng lưu trữ các bộ dữ liệu và tập lệnh để tính toán các chỉ số (metrics), cho phép bạn tái tạo các kết quả đã xuất bản hoặc tận dụng dữ liệu bổ sung cho ứng dụng của mình.
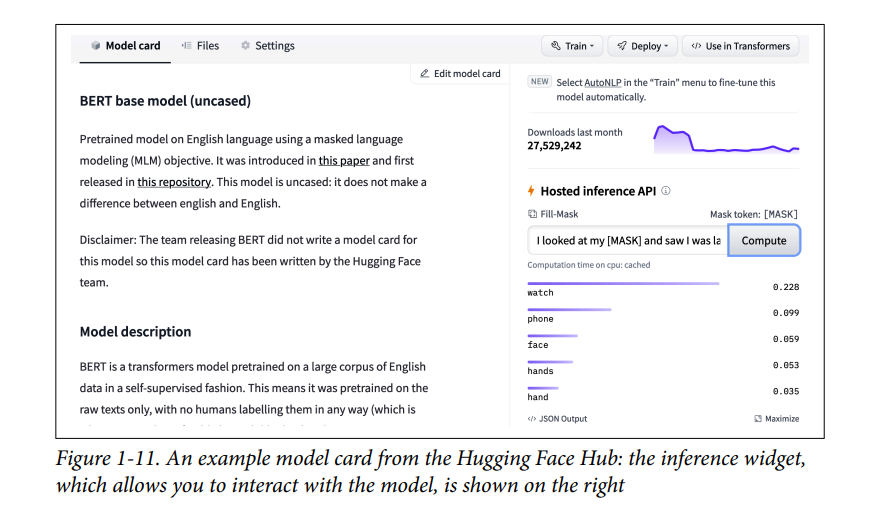
Hub cũng cung cấp model và dataset cards để ghi lại nội dung của các mô hình và bộ dữ liệu, đồng thời giúp bạn đưa ra quyết định sáng suốt về việc liệu chúng có phù hợp với bạn hay không. Một trong những tính năng thú vị nhất của Hub là bạn có thể thử bất kỳ mô hình nào trực tiếp thông qua các widget tương tác dành riêng cho nhiệm vụ khác nhau như trong Hình 1-11.
- Hãy tiếp tục tìm hiểu về 🤗 Tokenizers.
Hugging Face Tokenizers
- Đằng sau mỗi ví dụ về
pipelinemà chúng ta đã thấy trong blog này là tokenization - chia văn bản thô thành các phần nhỏ hơn được gọi là token. Chúng ta sẽ xem chi tiết điều này hoạt động như thế nào trong blog khác, nhưng bây giờ chỉ cần hiểu rằng token có thể là từ, một phần của từ hoặc có thể chỉ là các ký tự. Các mô hình Transformer được đào tạo trên các biểu diễn số của các token này, vì vậy việc thực hiện đúng bước này là khá quan trọng đối với toàn bộ dự án NLP! - 🤗 Tokenizers cung cấp nhiều chiến lược token và cực kỳ nhanh chóng trong việc tokenize văn bản nhờ phần Rust backend (Rust là một ngôn ngữ lập trình mà có hiệu suất cao). Nó cũng đảm nhận tất cả các bước xử lý trước và sau, chẳng hạn như chuẩn hóa đầu vào và chuyển đổi đầu ra mô hình sang định dạng cần thiết. Với 🤗 Tokenizers, chúng ta có thể tải tokenizer giống như cách chúng ta có thể tải trọng số mô hình được đào tạo trước với 🤗 Transformers.
- Chúng ta cần dataset và metrics để train và đánh giá các mô hình, vì vậy chúng ta hãy xem xét qua về 🤗 Datasets.
Hugging Face Dataset
- Tải, xử lý và lưu trữ dataset có thể là một quá trình rườm rà, đặc biệt là khi bộ dữ liệu quá lớn để vừa với RAM của máy tính xách tay của bạn. Ngoài ra, bạn thường cần triển khai các tập lệnh khác nhau để tải xuống dữ liệu và chuyển đổi nó thành định dạng tiêu chuẩn.
- 🤗 Datasets đơn giản hóa quá trình này bằng cách cung cấp giao diện tiêu chuẩn cho hàng nghìn bộ dữ liệu có thể được tìm thấy trên Hub. Nó cũng cung cấp bộ nhớ đệm thông minh (vì vậy bạn không phải làm lại quá trình xử lý trước mỗi khi chạy mã) và tránh các hạn chế về RAM bằng cách tận dụng một cơ chế đặc biệt được gọi là ánh xạ bộ nhớ lưu trữ nội dung của tệp trong bộ nhớ ảo và cho phép nhiều quy trình sửa đổi tệp hiệu quả hơn. Thư viện cũng có thể tương tác với các framework phổ biến như Pandas và NumPy, vì vậy bạn có thể dùng thoải mái các framework trên mà không cần phải lo gì.
- Tuy nhiên, có một bộ dữ liệu tốt và mô hình mạnh mẽ là vô giá trị nếu bạn không thể đo lường hiệu suất một cách đáng tin cậy. Thật không may, các chỉ số NLP cổ điển đi kèm với nhiều cách triển khai khác nhau có thể thay đổi một chút và dẫn đến kết quả lừa đảo. Bằng cách cung cấp các tập lệnh cho nhiều chỉ số, 🤗 Datasets giúp làm cho các thử nghiệm dễ tái tạo hơn và kết quả đáng tin cậy hơn.
- Với các thư viện 🤗 Transformers, 🤗 Tokenizers và 🤗 Datasets, chúng ta đã có mọi thứ chúng ta cần để train các mô hình transformer của riêng mình! Tuy nhiên, như chúng ta sẽ thấy trong blog khác, có những tình huống mà chúng ta cần kiểm soát fine-grained đối với training loop. Đó là nơi thư viện cuối cùng của hệ sinh thái phát huy tác dụng: 🤗 Accelerate.
Hugging Face Accelerate
Nếu bạn đã từng phải viết code bằng PyTorch, rất có thể bạn đã gặp một số vấn đề đau đầu khi cố gắng chuyển code chạy trên máy tính xách tay của bạn sang code chạy trên cụm của tổ chức bạn. 🤗 Accelerate thêm một lớp trừu tượng vào các training loop để xử lý tất cả các logic tùy chỉnh cần thiết cho cơ sở hạ tầng đào tạo. Điều này thực sự đẩy nhanh quy trình làm việc của bạn bằng cách đơn giản hóa việc thay đổi cơ sở hạ tầng khi cần thiết.
Điều này tóm tắt các thành phần cốt lõi của Hugging Face Ecosystem. Nhưng trước khi kết thúc chương này, chúng ta hãy xem xét một số thách thức phổ biến khi cố gắng triển khai transformer trong thế giới thực.
7. Những thử thách chính với Transformers
- Trong blog này, chúng ta đã có cái nhìn thoáng qua về một loạt các tác vụ NLP có thể được thực hiện với các mô hình transformers. Với sự truyền thông mạnh mẽ, có vẻ như khả năng của mô hình này là vô hạn. Tuy nhiên, bất chấp tính hữu ích của chúng, transformers còn lâu mới là một mô hình chất lượng đúng nghĩa. Dưới đây là một số thách thức liên quan đến chúng mà chúng ta sẽ khám phá:
- Language: Nghiên cứu NLP bị chi phối bởi ngôn ngữ tiếng Anh. Có một số mô hình cho các ngôn ngữ khác, nhưng khó tìm thấy các mô hình được đào tạo trước cho các ngôn ngữ hiếm hoặc ít tài nguyên.
- Data availability: Mặc dù chúng ta có thể sử dụng học chuyển giao để giảm đáng kể lượng dữ liệu được gắn nhãn mà các mô hình của chúng ta cần, nhưng nó vẫn còn quá ít để so sánh với dữ liệu được gắn nhãn mà con người cần để thực hiện nhiệm vụ đó.
- Working with long documents: Self-attention hoạt động cực kỳ tốt trên các văn bản dài đoạn văn, nhưng nó trở nên rất tốn kém khi chúng ta chuyển sang các văn bản dài hơn nữa như toàn bộ tài liệu.
- Opacity: Cũng như các mô hình học sâu khác, transformers ở một mức độ lớn là mờ đục (khó hiểu tại sao mô hình lại hoạt động như vậy). Thật khó hoặc không thể làm sáng tỏ “tại sao” một mô hình đưa ra một dự đoán nhất định. Đây là một thách thức đặc biệt khó khăn khi các mô hình này được triển khai để đưa ra các quyết định quan trọng.
- Bias: Các mô hình Transformer chủ yếu được đào tạo trước trên dữ liệu văn bản từ internet. Điều này in những thông tin phản cảm, sai lệch có trong dữ liệu vào các mô hình. Đảm bảo rằng những điều này không phân biệt chủng tộc, phân biệt giới tính hoặc những thông tin tệ hơn là một nhiệm vụ đầy thách thức.
- Mặc dù khó khăn, nhưng nhiều thách thức trong số này có thể được vượt qua. Chúng ta sẽ đề cập đến cách vượt qua những thử thách này ở blog khác.
8. Tổng kết
- Hy vọng rằng bây giờ bạn đã hào hứng học cách bắt đầu đào tạo và tích hợp các mô hình linh hoạt này vào các ứng dụng của riêng bạn! Bạn đã thấy trong chương này rằng chỉ với một vài dòng mã, bạn có thể sử dụng các mô hình hiện đại để phân loại, nhận dạng thực thể được đặt tên, trả lời câu hỏi, dịch và tóm tắt, nhưng đây thực sự chỉ là một phần rất nhỏ, còn nhiều phần khác đang chờ bạn phía trước.