Multilingual Named Entity Recognition
Cho đến nay trong cuốn sách này, chúng ta đã áp dụng transformers để giải quyết các nhiệm vụ NLP trên kho dữ liệu tiếng Anh - nhưng bạn sẽ làm gì khi tài liệu của bạn được viết bằng tiếng Hy Lạp, tiếng Swahili hoặc Klingon ? Một cách tiếp cận là tìm kiếm Hugging Face Hub để tìm pretrained language model phù hợp và fine-tune nó theo nhiệm vụ hiện tại. Tuy nhiên, các pretrained model này có xu hướng chỉ hoạt động tốt cho các ngôn ngữ “phổ biến” như tiếng Đức, tiếng Nga hoặc tiếng Anh, nơi có nhiều văn bản web có sẵn để pretraining. Một thách thức phổ biến khác nảy sinh khi kho dữ liệu của bạn là đa ngôn ngữ, bạn ó thể xây dựng nhiều model, mỗi model là một ngôn ngữ riêng nhưng nó không phải là ý tưởng hay.
May mắn thay, có một lớp các transformers đa ngôn ngữ đến để giải cứu bạn. Giống như BERT, các mô hình này masked language modeling như một mục tiêu pretraining, nhưng chúng được đào tạo trên các văn bản được viết một trăm ngôn ngữ. Bằng cách pretrained với kho dữ liệu khổng lồ trên nhiều ngôn ngữ, các transformers đa ngôn ngữ này cho phép chuyển đổi đa ngôn ngữ bằng zeroshot. Điều này có nghĩa là một mô hình được fine-tuned trên một ngôn ngữ có thể được áp dụng cho những ngôn ngữ khác mà không cần train thêm ! Điều này cũng làm cho các mô hình này rất phù hợp cho “code-switching”, trong đó người nói xen kẽ giữa hai hoặc nhiều ngôn ngữ trong ngữ cảnh của một cuộc trò chuyện duy nhất.
Trong chương này, chúng ta sẽ khám phá cách một mô hình transformers có tên là XLM-RoBERTa (được giới thiệu trong Chương 3) 1 có thể được fine-tuned để thực hiện nhiệm vụ name enity recognition (NER) trên một số ngôn ngữ. Như chúng ta đã thấy trong Chương 1, NER là một nhiệm vụ NLP phổ biến xác định các thực thể như con người, tổ chức hoặc vị trí địa lý trong văn bản. Các thực thể này có thể được sử dụng cho các ứng dụng khác nhau như thu thập thông tin chi tiết từ các tài liệu của công ty, nâng cao chất lượng của các công cụ tìm kiếm hoặc chỉ đơn giản là xây dựng cơ sở dữ liệu có cấu trúc từ kho dữ liệu.
Đối với chương này, giả sử rằng chúng ta muốn thực hiện NER cho một khách hàng có trụ sở tại Thụy Sĩ, nơi có bốn ngôn ngữ khác nhau (với tiếng Anh thường đóng vai trò là cầu nối giữa chúng). Hãy bắt đầu bằng cách lấy một kho dữ liệu đa ngôn ngữ phù hợp cho vấn đề này,
Zero-shot transfer hoặc zero-shot learning thường đề cập đến nhiệm vụ train một mô hình trên một bộ nhãn và sau đó đánh giá nó trên một bộ nhãn khác. Trong bối cảnh của transformer, zero-shot learning cũng có thể đề cập đến các tình huống mà một mô hình ngôn ngữ như GPT-3 được đánh giá trên một nhiệm vụ downstream mà nó thậm chí không được fine-tuned.
1. The Dataset
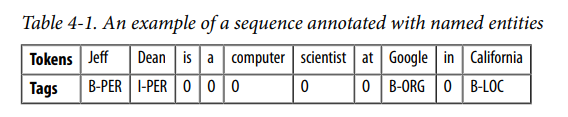
Trong chương này, chúng ta sẽ sử dụng một bộ dữ liệu con của Cross-lingual TRansfer Evaluation of Multilingual Encoders (XTREME) benchmark được gọi là WikiANN hoặc PAN-X. Bộ dữ liệu này bao gồm các bài viết trên Wikipedia bằng nhiều ngôn ngữ, bao gồm bốn ngôn ngữ được sử dụng phổ biến nhất ở Thụy Sĩ: tiếng Đức (62,9%), tiếng Pháp (22,9%), tiếng Ý (8,4%) và tiếng Anh (5,9%). Mỗi bài viết được chú thích bằng thẻ LOC (location), PER (person) và ORG (organization) ở định dạng “inside-outside-beginning” (IOB2). Ở định dạng này, nhãn “B” cho biết điểm bắt đầu của một thực thể và các tokens liên tiếp thuộc cùng một thực thể được đặt nhãn là “I”. Nhãn “O” cho biết mã thông báo không thuộc về bất kỳ thực thể nào. Ví dụ câu sau:
Jeff Dean is a computer scientist at Google in California
Có định dạng IBO2 như bảng 4-1:
Để load dữ liệu, chúng ta sẽ cần biết dataset configuration nào để truyền vào hàm load_dataset(). Bất cứ khi nào bạn đang xử lý một tập dữ liệu có nhiều miền, bạn có thể sử dụng hàm get_dataset_config_names() để tìm ra những tập con nào có sẵn:
1
2
3
4
5
from datasets import get_dataset_config_names
xtreme_subsets = get_dataset_config_names("xtreme")
print(f"XTREME has {len(xtreme_subsets)} configurations")
# XTREME has 183 configurations
Whoa, rất nhiều cấu hình! Hãy thu hẹp tìm kiếm bằng cách chỉ tìm kiếm các cấu hình bắt đầu bằng “PAN”:
1
2
3
panx_subsets = [s for s in xtreme_subsets if s.startswith("PAN")]
panx_subsets[:3]
# ['PAN-X.af', 'PAN-X.ar', 'PAN-X.bg']
OK, có vẻ như chúng ta đã xác định cú pháp của các tập con PAN-X: mỗi tập có hậu tố gồm hai chữ cái dường như là mã ngôn ngữ ISO 639-1. Điều này có nghĩa là để tải kho dữ liệu của Đức, chúng ta chuyển từ de vào tham số name của load_dataset() như sau:
1
2
3
from datasets import load_dataset
load_dataset("xtreme", name = "PAN-X.de")
Để tạo ra một kho dữ liệu Thụy Sĩ thực tế, chúng tôi sẽ lấy mẫu ngữ liệu tiếng Đức (de), tiếng Pháp (fr), tiếng Ý (it) và tiếng Anh (en) từ PAN-X theo tỷ lệ nói của chúng. Điều này sẽ tạo ra sự mất cân bằng ngôn ngữ rất phổ biến trong các bộ dữ liệu trong thế giới thực, nơi việc thu thập các ví dụ được gắn nhãn bằng ngôn ngữ thiểu số có thể tốn kém do thiếu các chuyên gia lĩnh vực thông thạo ngôn ngữ đó. Bộ dữ liệu mất cân bằng này sẽ mô phỏng một tình huống phổ biến khi làm việc trên các ứng dụng đa ngôn ngữ và chúng ta sẽ xem cách chúng ta có thể xây dựng một mô hình hoạt động trên tất cả các ngôn ngữ.
Để theo dõi từng ngôn ngữ, hãy tạo một từ điển Python defaultdict, chúng ta sẽ lấy mã ngôn ngữ làm khóa và kho dữ liệu PAN-X thuộc loại DatasetDict làm giá trị:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from collections import defaultdict
from datasets import DatasetDict
langs = ["de", "fr", "it", "en"]
fracs = [0.629, 0.229, 0.084, 0.059]
panx_ch = defaultdict(DatasetDict)
for lang,frac in zip(langs,fracs):
ds = load_dataset("xtreme", name = f"PAN-X.{lang}")
for split in ds:
panx_ch[lang][split] = (
ds[split]
.shuffle(seed = 0)
.select(range(int(frac * ds[split].num_rows)))
)
Ở đây chúng ta đã sử dụng phương thức shuffle() để đảm bảo rằng chúng ta không vô tình làm sai lệch các phân tách tập dữ liệu của mình, trong khi select() cho phép chúng ta giảm từng kho dữ liệu theo các giá trị trong fracs. Hãy xem chúng ta có bao nhiêu ví dụ cho mỗi ngôn ngữ trong các tập huấn luyện bằng cách truy cập thuộc tính Dataset.num_rows:
1
2
3
import pandas as pd
pd.DataFrame({lang: [panx_ch[lang]["train"].num_rows] for lang in langs}, index = ["Number of training examples"])

Theo như dữ liệu, chúng ta có nhiều ví dụ bằng tiếng Đức hơn tất cả các ngôn ngữ khác cộng lại, vì vậy chúng ta sẽ sử dụng nó như một điểm bắt đầu để thực hiện zero-shot cross-lingual transfer sang tiếng Pháp, tiếng Ý và tiếng Anh. Hãy kiểm tra các những ví dụ trong kho dữ liệu của Đức:
1
2
3
4
5
6
7
element = panx_ch["de"]["train"][0]
for key, value in element.items():
print(f"{key}: {value}")
# tokens: ['2.000', 'Einwohnern', 'an', 'der', 'Danziger', 'Bucht', 'in', 'der', 'polnischen', 'Woiwodschaft', 'Pommern', '.']
# ner_tags: [0, 0, 0, 0, 5, 6, 0, 0, 5, 5, 6, 0]
# langs: ['de', 'de', 'de', 'de', 'de', 'de', 'de', 'de', 'de', 'de', 'de', 'de']
Chúng ta thấy rằng cột ner_tags tương ứng với ánh xạ của từng thực thể với một vài số nguyên (ID). Điều này hơi khó hiểu đối với mắt người, vì vậy hãy tạo một cột mới với các thẻ LOC, PER và ORG quen thuộc. Để làm điều này, trước tiên cần lưu ý là đối tượng Dataset của chúng ta có một thuộc tính features chỉ định các kiểu dữ liệu cơ bản được liên kết với mỗi cột:
1
2
3
4
5
6
for key, value in panx_ch["de"]["train"].features.items():
print(f"{key}: {value}")
# tokens: Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)
# ner_tags: Sequence(feature=ClassLabel(names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC'], id=None), length=-1, id=None)
# langs: Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)
Lớp Sequence chỉ định một trường chứa danh sách các features, trong trường hợp này, ner_tags tương ứng với danh sách các ClassLabel. Hãy chọn feature này từ training set như sau:
1
2
3
4
tags = panx_ch["de"]["train"].features["ner_tags"].feature
print(tags)
# ClassLabel(names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC'], id=None)
Chúng ta có thể sử dụng phương thức ClassLabel.int2str() mà chúng ta đã gặp trong Chương 2 để tạo một cột mới trong tập train với tên lớp cho mỗi thẻ. Chúng ta sẽ sử dụng phương thức map() để trả về một dict với khóa tương ứng với tên cột mới và giá trị dưới dạng danh sách các tên lớp:
1
2
3
4
def create_tag_names(batch):
return {"ner_tags_str": [tags.int2str(idx) for idx in batch["ner_tags"]]}
panx_de = panx_ch["de"].map(create_tag_names)
Bây giờ chúng ta đã có các thẻ ở định dạng con người có thể đọc được, hãy xem các token và thẻ căn chỉnh như thế nào cho ví dụ đầu tiên trong tập train:
1
2
3
de_example = panx_de["train"][0]
pd.DataFrame([de_example["tokens"], de_example["ner_tags_str"]],
['Tokens', 'Tags'])

Sự hiện diện của các thẻ LOC có ý nghĩa vì câu “2.000 Einwohnern an der Danziger Bucht in der polnischen Woiwodschaft Pommern” có nghĩa là “2,000 inhabitants at the Gdansk Bay in the Polish voivodeship of Pomerania” trong tiếng Anh, và Vịnh Gdansk là một vịnh ở biển Baltic, trong khi “voivodeship” tương ứng với một nhà nước ở Ba Lan.
Để kiểm tra nhanh rằng chúng ta không có bất kỳ sự mất cân bằng bất thường nào trong các thẻ, hãy tính toán tần số của từng thực thể trên mỗi phân tách:
1
2
3
4
5
6
7
8
9
10
from collections import Counter
split2freqs = defaultdict(Counter)
for split, dataset in panx_de.items():
for row in dataset["ner_tags_str"]:
for tag in row:
if tag.startswith("B"):
tag_type = tag.split("-")[1]
split2freqs[split][tag_type] += 1
pd.DataFrame.from_dict(split2freqs, orient = "index")
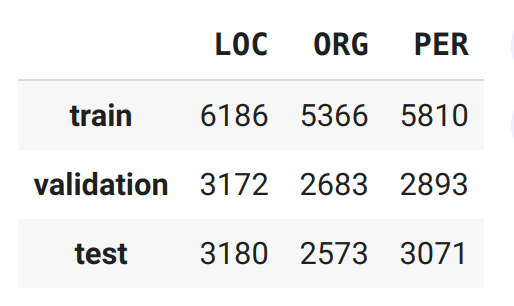
Điều này có vẻ tốt — sự phân phối của các tần số PER, LOC và ORG gần giống nhau cho mỗi bộ, vì vậy bộ validation và bộ test sẽ cung cấp một thước đo tốt về khả năng khái quát hóa của nhiệm vụ NER. Tiếp theo, chúng ta hãy xem xét một số mô hình transformers multilingual phổ biến và cách chúng có thể được điều chỉnh để giải quyết nhiệm vụ NER.
2. Multilingual Transformers
Các transformers multilingual giống với kiến trúc và quy trình đào tạo tương tự như các mô hình transformers bình thường, ngoại trừ kho dữ liệu được sử dụng để pretrained bao gồm các tài liệu bằng nhiều ngôn ngữ. Một đặc điểm đáng chú ý của cách tiếp cận này là mặc dù không nhận được thông tin rõ ràng để phân biệt giữa các ngôn ngữ, nhưng các biểu diễn ngôn ngữ kết quả có thể khái quát hóa tốt giữa các ngôn ngữ cho nhiều nhiệm vụ downstream khác nhau. Trong một số trường hợp, khả năng thực hiện chuyển giao đa ngôn ngữ này có thể tạo ra kết quả cạnh tranh với các mô hình đơn ngữ, giúp tránh nhu cầu đào tạo một mô hình cho mỗi ngôn ngữ!
Để đo lường tiến trình chuyển giao đa ngôn ngữ cho NER, bộ dữ liệu CoNLL-2002 và CoNLL-2003 thường được sử dụng làm benchmark cho tiếng Anh, tiếng Hà Lan, tiếng Tây Ban Nha và tiếng Đức. Benchmark này bao gồm các bài báo được chú thích với các danh mục LOC, PER và ORG giống như PAN-X, nhưng nó chứa một nhãn MISC bổ sung cho các thực thể linh tinh không thuộc ba nhóm trước. Các mô hình transformers multilingual thường được đánh giá theo ba cách khác nhau:
- en: Fine-tuned trên bộ train của ngôn ngữ Tiếng Anh và sau đó đánh giá trên bộ test của các ngôn ngữ khác.
- each: Fine-tuned và đánh giá trên từng ngôn ngữ một.
- all: Fine-tuned trên tất cả bộ dữ liệu train của tất cả ngôn ngữ, sau đó đánh giá tren tập test của tất cả ngôn ngữ hợp lại.
Chúng ta sẽ áp dụng một chiến lược đánh giá tương tự cho nhiệm vụ NER, nhưng trước tiên chúng ta cần chọn một mô hình để đánh giá. Một trong những mô hình transformers multilingual đầu tiên là mBERT, sử dụng cùng một kiến trúc và mục tiêu pretrained như BERT nhưng thêm các bài viết Wikipedia từ nhiều ngôn ngữ vào pretraining corpus. Kể từ đó, mBERT đã được thay thế bởi XLM-RoBERTa (hay viết tắt là XLM-R), vì vậy đó là mô hình mà chúng ta sẽ xem xét trong chương này.
Như chúng ta đã thấy trong Chương 3, XLM-R chỉ sử dụng MLM như một mục tiêu pretrained cho 100 ngôn ngữ, nhưng được phân biệt bởi kích thước khổng lồ của pretraining corpus so với những mô hình tiền nhiệm của nó: kết xuất Wikipedia cho mỗi ngôn ngữ và 2,5 terabyte dữ liệu Common Crawl từ web. Kho dữ liệu này lớn hơn vài bậc so với những ngôn ngữ được sử dụng trong các mô hình trước đó và cung cấp một sự gia tăng đáng kể tín hiệu cho các ngôn ngữ có nguồn tài nguyên thấp như tiếng Miến Điện và tiếng Swahili, nơi chỉ có một số lượng nhỏ các bài viết trên Wikipedia tồn tại.
Phần RoBERTa trong tên của mô hình đề cập đến thực tế là phương pháp pretrained cũng giống như đối với các mô hình RoBERTa bình thường. Các nhà phát triển của RoBERTa đã cải thiện một số khía cạnh của BERT, đặc biệt là bằng cách loại bỏ hoàn toàn nhiệm vụ dự đoán câu tiếp theo. XLM-R cũng loại bỏ language embedding được sử dụng trong XLM và sử dụng SentencePiece để tokenize trực tiếp các văn bản thô. Bên cạnh tính chất đa ngôn ngữ, một sự khác biệt đáng chú ý giữa XLM-R và RoBERTa là kích thước của từ vựng đặc biệt: 250.000 token so với 55.000!
XLM-R là một lựa chọn tuyệt vời cho các tác vụ NLU đa ngôn ngữ. Trong phần tiếp theo, chúng ta sẽ khám phá cách nó có thể tokenize hiệu quả trên nhiều ngôn ngữ.
3. A Closer Look at Tokenization
Thay vì sử dụng bộ mã hóa WordPiece, XLM-R sử dụng một bộ mã hóa có tên là SentencePiece được train trên văn bản thô của 100 ngôn ngữ. Để cảm nhận về cách so sánh SentencePiece với WordPiece, hãy tải tokenizer BERT và XLM-R theo cách thông thường với 🤗 Transformers:
1
2
3
4
5
6
from transformers import AutoTokenizer
bert_model_name = "bert-base-cased"
xlmr_model_name = "xlm-roberta-base"
bert_tokenizer = AutoTokenizer.from_pretrained(bert_model_name)
xlmr_tokenizer = AutoTokenizer.from_pretrained(xlmr_model_name)
Bằng cách mã hóa một chuỗi văn bản nhỏ, chúng ta cũng có thể truy xuất các token mà mỗi mô hình đã sử dụng trong quá trình pretraining:
1
2
3
4
5
6
7
text = "Jack Sparrow loves New York!"
bert_tokens = bert_tokenizer(text).tokens()
xlmr_tokens = xlmr_tokenizer(text).tokens()
print(bert_tokens)
print(xlmr_tokens)
# ['[CLS]', 'Jack', 'Spa', '##rrow', 'loves', 'New', 'York', '!', '[SEP]']
# ['<s>', '▁Jack', '▁Spar', 'row', '▁love', 's', '▁New', '▁York', '!', '</s>']
Ở đây chúng ta thấy rằng thay vì các token [CLS] và [SEP] mà BERT sử dụng cho các nhiệm vụ phân loại câu, XLM-R sử dụng và <\s> để biểu thị sự bắt đầu và kết thúc của một chuỗi. Các token được thêm vào trong giai đoạn cuối cùng của quá trình tokenization, như chúng ta sẽ thấy tiếp theo.
The Tokenizer Pipeline
Cho đến nay, chúng ta đã coi tokenization là một hoạt động duy nhất chuyển đổi chuỗi thành số nguyên mà chúng ta có thể truyền qua mô hình. Điều này không hoàn toàn chính xác và nếu chúng ta xem xét kỹ hơn, chúng ta có thể thấy rằng nó thực sự là một quy trình xử lý đầy đủ thường bao gồm bốn bước, như thể hiện trong Hình 4-1.

Chúng ta hãy xem xét kỹ hơn từng bước xử lý và minh họa hiệu quả của chúng bằng câu ví dụ “Jack Sparrow loves New York!”:
Normalization: Bước này tương ứng với tập hợp các thao tác bạn áp dụng cho một chuỗi thô để làm cho nó “sạch hơn”. Các thao tác phổ biến bao gồm loại bỏ khoảng trắng và xóa các ký tự có dấu. Unicode Normalization là một hoạt động chuẩn hóa phổ biến khác được áp dụng bởi nhiều tokenizer để đối phó với thực tế là thường tồn tại nhiều cách khác nhau để viết cùng một ký tự. Điều này có thể làm cho hai phiên bản của chuỗi “giống nhau” (tức là với cùng một chuỗi ký tự trừu tượng) xuất hiện khác nhau; Các sơ đồ Unicode Normalization như NFC, NFD, NFKC và NFKD thay thế các cách khác nhau để viết cùng một ký tự bằng các dạng tiêu chuẩn. Một ví dụ khác về chuẩn hóa là lowercasing. Nếu mô hình dự kiến chỉ chấp nhận và sử dụng các ký tự viết thường, kỹ thuật này có thể được sử dụng để giảm kích thước của từ vựng mà nó yêu cầu. Sau khi chuẩn hóa, chuỗi ví dụ của chúng ta sẽ giống như “jack sparrow loves new york!”
Pretokenization: Bước này chia một văn bản thành các đối tượng nhỏ hơn, đưa ra một giới hạn trên, nghĩa là token của bạn sẽ trông như thế nào khi kết thúc quá trình đào tạo. Một cách tốt để nghĩ về điều này là pretokenizer sẽ chia văn bản của bạn thành “từ” và token cuối cùng của bạn sẽ là một phần của những từ đó. Đối với các ngôn ngữ cho phép điều này (tiếng Anh, tiếng Đức và nhiều ngôn ngữ Đông Âu), các chuỗi thường có thể được chia thành các từ trên khoảng trắng và dấu câu. Ví dụ, bước này có thể biến đổi [“jack”, “sparrow”, “loves”, “new”, “york”, “!”]. Sau đó, các từ này đơn giản hơn để chia thành các từ con với các thuật toán Byte-Pair Encoding (BPE) hoặc thuật toán Unigram trong bước tiếp theo của quy trình. Tuy nhiên, đối với một số ngôn ngữ như tiếng Trung, tiếng Nhật, tiếng Hàn, việc tách từ không đơn giản như vậy, vì chúng không có dấu cách giữa các từ. Trong trường hợp này, nên sử dụng thư viện xử lý ngôn ngữ riêng biệt thay vì tiền tách từ theo cách thông thường.
Tokenizer model: Khi các văn bản đầu vào được Normalization và Pretokenization, Tokenizer model sẽ áp dụng mô hình phân tách các từ con trên các từ. Đây là một phần của quy trình cần được train trên kho dữ liệu của bạn (hoặc đã được train trước nếu bạn đang sử dụng pretrained tokenizer). Vai trò của mô hình là chia các từ thành các từ con để giảm kích thước của từ vựng và cố gắng giảm số lượng token ngoài từ điển. Một số thuật toán tokenization phổ biến, bao gồm BPE, Unigram và WordPiece. Ví dụ của chúng ta có thể trông giống như [jack, spa, rrow, loves, new, york, !] khi tokenizer được áp dụng. Lưu ý rằng tại thời điểm này, chúng ta không còn còn một danh sách các chuỗi mà chúng ta là một danh sách các số nguyên (input IDs); Để giữ cho ví dụ minh họa, tôi đã giữ lại các từ nhưng bỏ dấu ngoặc kép để biểu thị sự biến đổi từ thành số nguyên (thực tế đầu ra có dạng [1,43,65,175,23,44,67]).
Postprocessing: Đây là bước cuối cùng của quy trình tokenization, trong đó một số chuyển đổi bổ sung có thể được áp dụng trên danh sách token — ví dụ: thêm token đặc biệt ở đầu hoặc cuối chuỗi. Ví dụ, BERT-style tokenizer sẽ thêm các token đặc biệt như sau: [CLS, jack, spa, rrow, loves, new, york, !, SEP]. Chuỗi này (hãy nhớ rằng đây sẽ là một dãy số nguyên, không phải các token bạn thấy ở đây) sau đó có thể được đưa vào mô hình.
Quay trở lại so sánh XLM-R và BERT, bây giờ chúng ta hiểu rằng SentencePiece thêm token và thay vì [CLS] và [SEP] trong bước Postprocessing (như một quy ước, chúng ta sẽ tiếp tục sử dụng [CLS] và [SEP] trong các hình minh họa đồ họa). Hãy quay lại với SentencePiece tokenizer để xem điều gì làm cho nó trở nên đặc biệt.
The SentencePiece Tokenizer
SentencePiece Tokenizer dựa trên một thuật toán tách từ được gọi là Unigram và mã hóa mỗi văn bản đầu vào dưới dạng một chuỗi các ký tự Unicode. Tính năng cuối cùng này đặc biệt hữu ích cho kho dữ liệu đa ngôn ngữ vì nó cho phép SentencePiece không biết về trọng âm, dấu câu và thực tế là nhiều ngôn ngữ, như tiếng Nhật, không có ký tự khoảng trắng. Một tính năng đặc biệt khác của SentencePiece là khoảng trắng được gán ký hiệu Unicode U + 2581, hoặc là ký tự “___”, còn được gọi là ký tự khối một phần tư. Điều này cho phép SentencePiece detokenize một chuỗi mà không có sự mơ hồ và không dựa vào các pretokeniz dành riêng cho ngôn ngữ. Trong ví dụ của chúng ta từ phần trước, chúng ta có thể thấy rằng thuật toán WordPiece đã làm mất thông tin rằng không có khoảng trắng giữa “York” và “!”. Ngược lại, SentencePiece giữ nguyên khoảng trắng trong văn bản được mã hóa để chúng ta có thể quay trở lại văn bản thô mà không mơ hồ:
1
2
3
"".join(xlmr_tokens).replace(u"\u2581", " ")
# <s> Jack Sparrow loves New York!</s>
Bây giờ chúng ta đã hiểu cách thức hoạt động của thuật toán SentencePiece, hãy xem cách chúng ta có thể encode ví dụ đơn giản trên trong một hình dạng phù hợp với nhiệm vụ NER. Điều đầu tiên cần làm là load pretrained model với token classification head. Nhưng thay vì load head này trực tiếp từ 🤗 Transformers, chúng ta sẽ tự làm nó! Bằng cách đi sâu hơn vào 🤗 Transformers API, chúng ta có thể thực hiện điều này chỉ với một vài bước.
4. Transformers for Named Entity Recognition
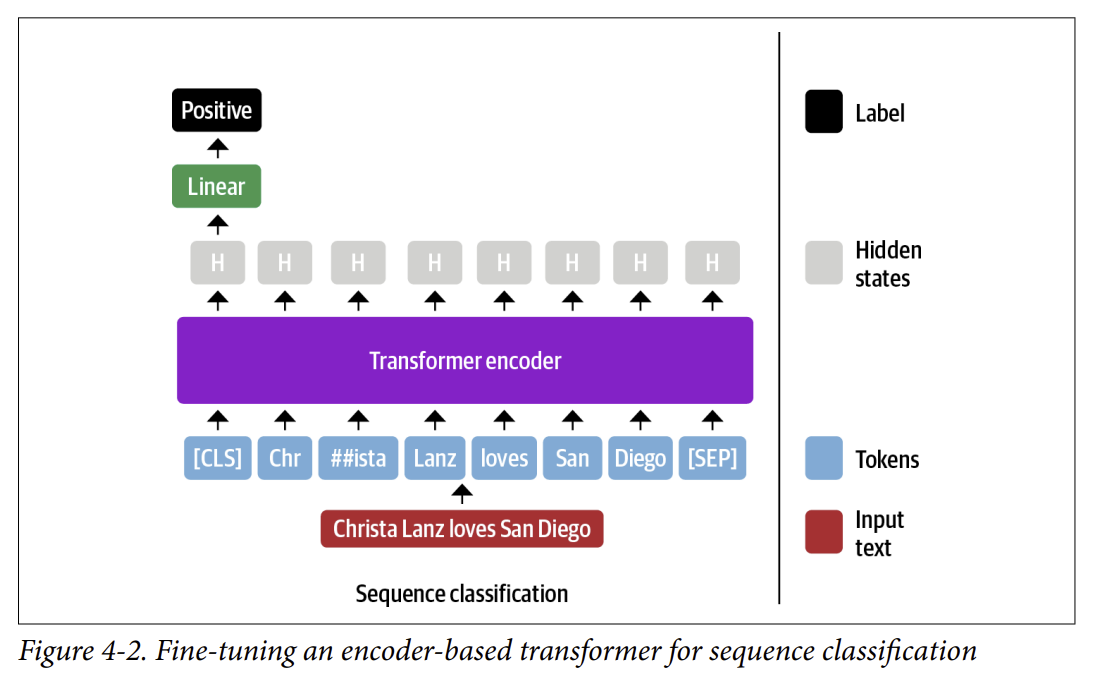
Trong Chương 2, chúng ta thấy rằng để phân loại văn bản, BERT sử dụng token đặc biệt [CLS] để đại diện cho toàn bộ chuỗi văn bản. Biểu diễn này sau đó được đưa qua một lớp fully connected hoặc dense layer để xuất ra sự phân phối của tất cả các giá trị nhãn rời rạc, như thể hiện trong Hình 4-2.
BERT và kiến trúc encoder-only transformers khác có cách tiếp cận tương tự đối với NER, ngoại trừ việc biểu diễn của mỗi input token được đưa vào cùng một lớp fully connected layer để outout ra phân phối của từng token. Vì lý do này, NER thường được đóng khung như một token classification task. Quá trình này trông giống như sơ đồ trong Hình 4-3.
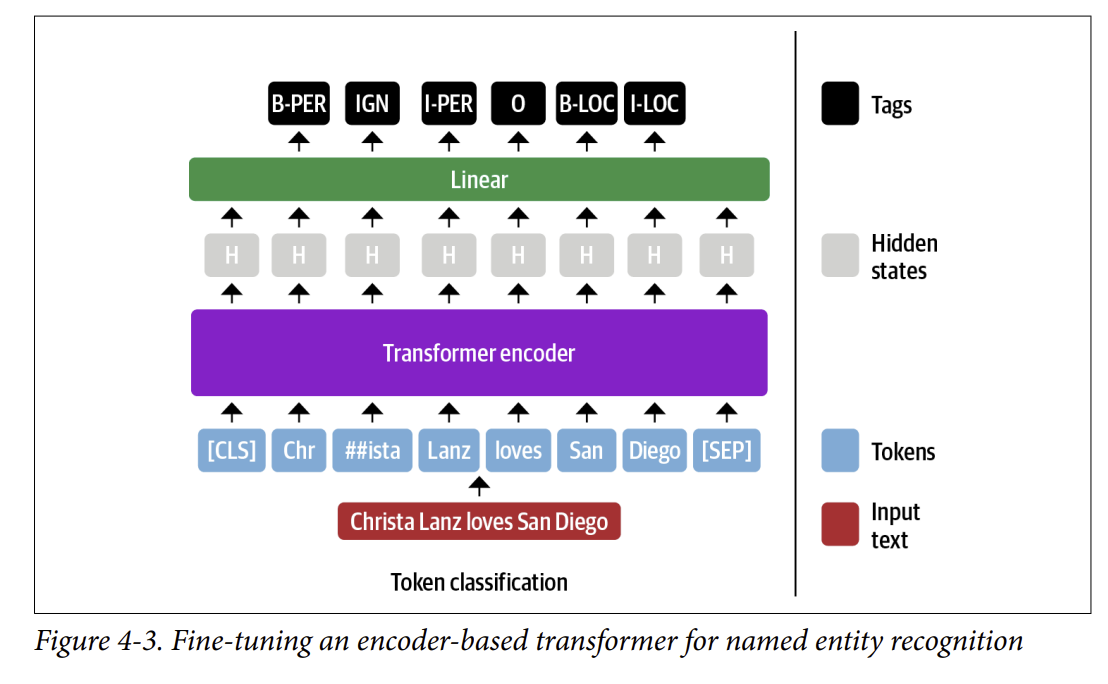
Chúng ta nên xử lý các từ con như thế nào trong nhiệm vụ phân loại token ? Ví dụ, tên “Christa” trong Hình 4-3 được mã hóa thành các từ con là “Chr” và “##ista”, vậy cái nào nên được gán nhãn B-PER ?
Trong bài báo BERT, các tác giả đã gán nhãn này cho từ con đầu tiên (“Chr” trong ví dụ của chúng ta) và bỏ qua từ con sau (“##ista”). Đây là quy ước mà chúng ta sẽ áp dụng ở đây và chúng ta sẽ gán thẻ các từ phụ bị bỏ qua bằng IGN. Sau đó, chúng ta có thể dễ dàng truyền nhãn dự đoán của từ con đầu tiên sang các từ con tiếp theo trong bước postprocessing. Chúng ta cũng có thể chọn bao gồm biểu diễn của từ con “##ista” bằng cách gán cho nó một bản sao của nhãn B-LOC, nhưng điều này vi phạm định dạng IOB2.
May mắn thay, tất cả các khía cạnh kiến trúc mà chúng ta đã thấy trong BERT đều được chuyển sang XLM-R vì kiến trúc của nó dựa trên RoBERTa, giống hệt với BERT! Tiếp theo, chúng ta sẽ xem cách 🤗 Transformers hỗ trợ nhiều tác vụ khác với những sửa đổi nhỏ.
5. The Anatomy of the Transformers Model Class
🤗 Transformers được tổ chức xung quanh các lớp chuyên dụng cho từng kiến trúc và nhiệm vụ. Các lớp mô hình liên quan đến các nhiệm vụ khác nhau được đặt tên theo quy tắc <ModelName>For<Task>, hoặc AutoModelFor<Task> khi sử dụng các lớp AutoModel.
Tuy nhiên, cách tiếp cận này có một số hạn chế. Để thúc đẩy việc đi sâu hơn vào API Transformers, hãy xem xét kịch bản sau: Giả sử bạn có một ý tưởng tuyệt vời để giải quyết một bài toán NLP mà bạn đã suy nghĩ từ lâu bằng một mô hình Transformer. Bạn lên lịch một cuộc họp với sếp, trình bày ý tưởng và thuyết phục rằng nếu giải quyết được bài toán này, doanh thu của bộ phận sẽ tăng lên. Ấn tượng với bài thuyết trình đầy màu sắc của bạn và những viễn cảnh lợi nhuận, sếp hào phóng cho bạn một tuần để xây dựng bản thử nghiệm (proof-of-concept).
Phấn khích với kết quả, bạn bắt đầu ngay lập tức. Bạn khởi động GPU và mở một sổ tay (notebook). Bạn chạy lệnh:
1
from transformers import BertForTaskXY
(Lưu ý rằng TaskXY là một nhiệm vụ giả định bạn muốn giải quyết). Và rồi, một dòng chữ màu đỏ đáng sợ hiện lên trên màn hình:
1
ImportError: cannot import name BertForTaskXY
Ồ không, không hề có mô hình BERT nào dành cho trường hợp sử dụng của bạn! Làm sao bạn có thể hoàn thành dự án trong một tuần nếu phải tự xây dựng toàn bộ mô hình từ đầu?! Bạn thậm chí nên bắt đầu từ đâu?
Đừng hoảng sợ! 🤗 Transformers được thiết kế để giúp bạn dễ dàng mở rộng các mô hình có sẵn cho các trường hợp sử dụng cụ thể của mình. Bạn có thể tải trọng số từ các mô hình đã được huấn luyện trước và sử dụng các hàm trợ giúp cho từng nhiệm vụ cụ thể. Điều này giúp bạn xây dựng mô hình tùy chỉnh với chi phí thấp nhất có thể. Trong phần này, chúng ta sẽ xem cách triển khai một mô hình tùy chỉnh.
Bodies and Head
Khái niệm chính làm cho 🤗 Transformers trở nên linh hoạt là việc tách kiến trúc thành thân (body) và đầu (head), như đã đề cập trong Chương 1. Chúng ta đã thấy rằng khi chuyển từ nhiệm vụ tiền huấn luyện sang nhiệm vụ hạ nguồn (downstream task), chúng ta cần thay thế lớp cuối cùng của mô hình bằng một lớp phù hợp với nhiệm vụ mới. Lớp cuối này được gọi là đầu mô hình (model head) - đây là phần đặc thù theo nhiệm vụ (task-specific). Phần còn lại của mô hình được gọi là thân mô hình (body) - bao gồm vector nhúng token và các lớp transformer, phần này không phụ thuộc vào nhiệm vụ (task-agnostic).
Cấu trúc này cũng được phản ánh trong mã nguồn của 🤗 Transformers:
- Thân mô hình được triển khai trong các lớp như
BertModelhoặcGPT2Model, trả về trạng thái ẩn (hidden states) của lớp cuối cùng. - Mô hình theo nhiệm vụ như
BertForMaskedLMhoặcBertForSequenceClassificationsử dụng mô hình gốc và thêm đầu mô hình lên trên trạng thái ẩn, như minh họa trong Hình 4-4.
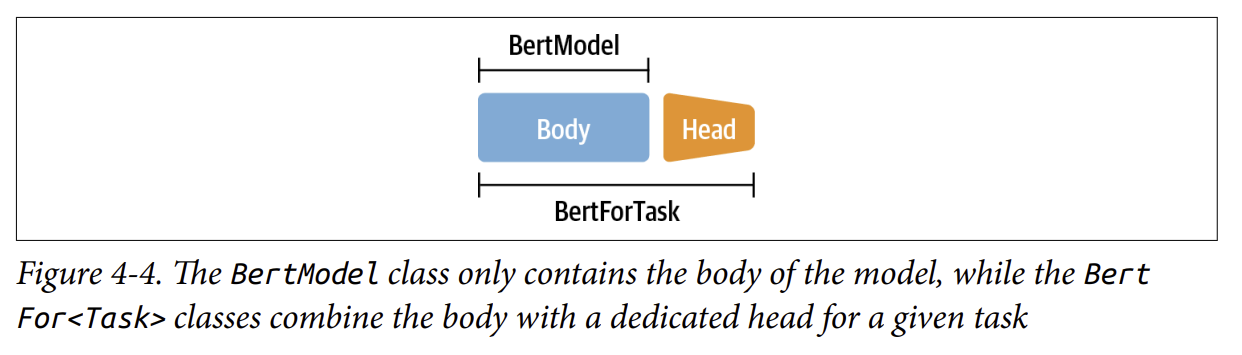
Như chúng ta sẽ thấy tiếp theo, sự tách biệt giữa thân và đầu này cho phép chúng ta xây dựng một đầu tùy chỉnh cho bất kỳ tác vụ nào và chỉ cần gắn nó lên trên một mô hình được đào tạo trước.
Creating a Custom Model for Token Classification
Hãy cùng thực hiện bài tập xây dựng đầu phân loại token tùy chỉnh cho XLMR. Vì XLM-R sử dụng kiến trúc mô hình tương tự như RoBERTa, chúng tôi sẽ sử dụng RoBERTa làm base model, nhưng được tăng cường với các cài đặt dành riêng cho XLM-R. Lưu ý rằng đây là một bài để chỉ cho bạn cách xây dựng một mô hình tùy chỉnh cho nhiệm vụ của riêng bạn. Đối với nhiệm vụ phân loại token, một lớp XLMRobertaForTokenClassification đã tồn tại mà bạn có thể import nó từ thư viện 🤗 Transformers. Nếu muốn, bạn có thể chuyển sang phần tiếp theo và chỉ cần sử dụng phần đó mà không cần phải đọc phần này.
Để bắt đầu, chúng ta cần một cấu trúc dữ liệu đại diện cho trình gắn thẻ XLM-R NER. Như một phỏng đoán đầu tiên, chúng ta sẽ cần một đối tượng cấu hình để khởi tạo mô hình và một hàm forward() để tạo ra các kết quả đầu ra. Hãy tiếp tục và xây dựng lớp XLM-R của chúng ta để phân loại token.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import torch.nn as nn
from transformers import XLMRobertaConfig
from transformers.modeling_outputs import TokenClassifierOutput
from transformers.models.roberta.modeling_roberta import RobertaModel
from transformers.models.roberta.modeling_roberta import RobertaPreTrainedModel
class XLMRobertaForTokenClassification(RobertaPreTrainedModel):
config_class = XLMRobertaConfig
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
# Load model body
self.roberta = RobertaModel(config, add_pooling_layer = False)
# Set up token classification head
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Load and init weights
self.init_weights()
def forward(self, input_ids = None, attention_mask = None, token_type_ids = None, labels = None, **kwargs):
# Use model body to get encoder representations
# Remove 'num_items_in_batch' from kwargs if present
kwargs.pop('num_items_in_batch', None)
outputs = self.roberta(input_ids, attention_mask = attention_mask, token_type_ids = token_type_ids, **kwargs)
sequence_output = self.dropout(outputs[0])
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
return TokenClassifierOutput(loss = loss, logits = logits, hidden_states = outputs.hidden_states, attentions = outputs.attentions)
Lớp config_class đảm bảo rằng các thiết lập tiêu chuẩn của XLM-R được sử dụng khi chúng ta khởi tạo một mô hình mới. Nếu bạn muốn thay đổi các tham số mặc định, bạn có thể làm điều này bằng cách ghi đè các thiết lập mặc định trong cấu hình.
Với phương thức super(), chúng ta gọi hàm khởi tạo của lớp RobertaPreTrainedModel. Đây là một lớp trừu tượng xử lý việc khởi tạo hoặc tải trọng số đã được huấn luyện trước. Sau đó, chúng ta tải phần thân mô hình (model body), tức là RobertaModel, và mở rộng nó bằng cách thêm một đầu phân loại (classification head) riêng, bao gồm một tầng dropout và một tầng feed-forward tiêu chuẩn.
Lưu ý rằng chúng ta đặt add_pooling_layer=False để đảm bảo tất cả các trạng thái ẩn (hidden states) đều được trả về, thay vì chỉ trả về trạng thái liên quan đến token [CLS]. Cuối cùng, chúng ta khởi tạo tất cả các trọng số bằng cách gọi phương thức init_weights(), phương thức này được kế thừa từ RobertaPreTrainedModel. Điều này sẽ giúp tải các trọng số đã huấn luyện trước cho phần thân mô hình và khởi tạo ngẫu nhiên trọng số cho đầu phân loại token của chúng ta.
Điều duy nhất còn lại là định nghĩa mô hình sẽ thực hiện những gì trong quá trình lan truyền xuôi (forward pass) bằng cách triển khai phương thức forward(). Trong quá trình này, dữ liệu đầu vào trước tiên sẽ được đưa qua thân mô hình. Có nhiều biến đầu vào, nhưng hiện tại chúng ta chỉ cần quan tâm đến input_ids và attention_mask.
Trạng thái ẩn (hidden state), là một phần của thân mô hình, sau đó được đưa qua tầng dropout và tầng phân loại (classification layer). Nếu chúng ta cũng cung cấp nhãn đầu ra (output labels) trong forward pass, ta có thể tính trực tiếp hàm mất mát (loss).
Nếu có mặt nạ chú ý (attention mask), chúng ta cần xử lý thêm một chút để đảm bảo chỉ tính toán mất mát trên các token không bị che (unmasked tokens). Cuối cùng, chúng ta đóng gói tất cả đầu ra vào một đối tượng TokenClassifierOutput, giúp truy cập các phần tử theo một cấu trúc named tuple quen thuộc như trong các chương trước.
Chỉ cần triển khai hai phương thức trong một lớp đơn giản, chúng ta có thể xây dựng một mô hình transformer tùy chỉnh. Và vì chúng ta kế thừa từ lớp PreTrainedModel, chúng ta có quyền truy cập ngay vào các tiện ích mạnh mẽ của 🤗 Transformers, chẳng hạn như from_pretrained()!
Bây giờ, hãy cùng tìm hiểu cách tải trọng số đã huấn luyện trước vào mô hình tùy chỉnh của chúng ta.
Loading a Custom Model
Bây giờ chúng ta đã sẵn sàng để tải mô hình phân loại token (token classification model). Chúng ta cần cung cấp một số thông tin bổ sung ngoài tên mô hình, bao gồm:
- Các tag dùng để gán nhãn cho từng thực thể.
- Ánh xạ của mỗi tag sang một ID và ngược lại.
Tất cả thông tin này có thể được lấy từ biến tags, vốn là một đối tượng ClassLabel có thuộc tính names, giúp chúng ta tạo ra ánh xạ như sau:
1
2
index2tag = {idx: tag for idx, tag in enumerate(tags.names)}
tag2index = {tag: idx for idx, tag in enumerate(tags.names)}
Chúng ta sẽ lưu các ánh xạ này và thuộc tính tags.num_classes vào đối tượng AutoConfig, mà chúng ta đã tìm hiểu trong Chương 3. Khi truyền các tham số từ khóa vào phương thức from_pretrained(), chúng ta có thể ghi đè các giá trị mặc định:
1
2
3
4
5
6
7
from transformers import AutoConfig
xlmr_config = AutoConfig.from_pretrained(xlmr_model_name,
num_labels=tags.num_classes,
id2label=index2tag,
label2id=tag2index)
Lớp AutoConfig chứa bản thiết kế kiến trúc (blueprint) của mô hình. Khi chúng ta tải một mô hình bằng AutoModel.from_pretrained(model_ckpt), tập tin cấu hình (configuration file) tương ứng với mô hình đó sẽ tự động được tải xuống. Tuy nhiên, nếu muốn chỉnh sửa một số thông tin như số lượng lớp (number of classes) hoặc tên nhãn (label names), chúng ta có thể tải cấu hình trước và tùy chỉnh theo mong muốn.
Bây giờ, chúng ta có thể tải trọng số của mô hình như bình thường bằng phương thức from_pretrained(), đồng thời truyền tham số config để sử dụng cấu hình đã thiết lập.
Lưu ý rằng chúng ta không cần tự hiện thực việc tải trọng số đã huấn luyện trước trong lớp mô hình tùy chỉnh, vì điều này đã được thực hiện sẵn khi kế thừa từ RobertaPreTrainedModel:
1
2
3
4
5
6
7
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
xlmr_model = (XLMRobertaForTokenClassification
.from_pretrained(xlmr_model_name, config=xlmr_config)
.to(device))
Để kiểm tra nhanh xem tokenizer và mô hình đã được khởi tạo đúng chưa, chúng ta thử dự đoán (predictions) trên một chuỗi có sẵn các thực thể quen thuộc
1
2
3
4
input_ids = xlmr_tokenizer.encode(text, return_tensors="pt")
pd.DataFrame([xlmr_tokens, input_ids[0].numpy()],
index=["Tokens", "Input IDs"])
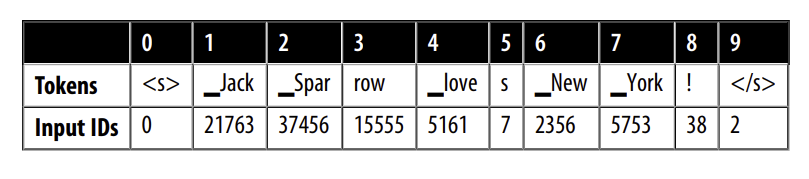
Như bạn có thể thấy, các token bắt đầu () và kết thúc () có ID lần lượt là $0$ và $2$.
Bây giờ, chúng ta cần truyền đầu vào cho mô hình và trích xuất dự đoán bằng cách lấy argmax để chọn lớp có xác suất cao nhất cho mỗi token:
1
2
3
4
5
6
7
8
outputs = xlmr_model(input_ids.to(device)).logits
predictions = torch.argmax(outputs, dim=-1)
print(f"Number of tokens in sequence: {len(xlmr_tokens)}")
print(f"Shape of outputs: {outputs.shape}")
# Number of tokens in sequence: 10
# Shape of outputs: torch.Size([1, 10, 7])
Chúng ta thấy logits có kích thước là [batch_size, num_tokens, num_tags], mỗi token thì đưa ra xác suất của 7 khả năng thẻ trong nhiệm vụ NER. Chúng ta có thể xem nhanh qua cách pretrained model dự đoán như sau:
1
2
preds = [tags.names[p] for p in predictions[0].cpu().numpy()]
pd.DataFrame([xlmr_tokens, preds], index=["Tokens", "Tags"])
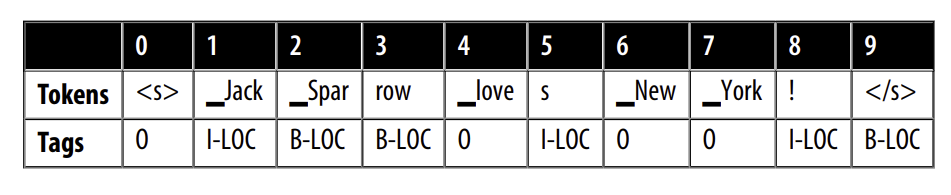
Không có gì đáng ngạc nhiên, lớp token classification của chúng ta với trọng lượng ngẫu nhiên hoạt động rất tệ; Hãy fine-tune trên một số dữ liệu được dán nhãn để làm cho nó tốt hơn! Trước khi làm như vậy, hãy để tóm gón tất cả các bước trước đó vào một hàm để tái sử dụng sau này:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def tag_text(text, tags, model, tokenizer):
# Tách các token, bao gồm cả ký tự đặc biệt
tokens = tokenizer(text).tokens()
# Mã hóa văn bản thành ID
input_ids = xlmr_tokenizer(text, return_tensors="pt").input_ids.to(device)
# Lấy xác suất dự đoán trên 7 nhãn
outputs = model(input_ids)[0]
# Lấy nhãn có xác suất cao nhất
predictions = torch.argmax(outputs, dim=2)
# Chuyển thành DataFrame
preds = [tags.names[p] for p in predictions[0].cpu().numpy()]
return pd.DataFrame([tokens, preds], index=["Tokens", "Tags"])
Tokenizing Texts for NER
Bây giờ chúng ta đã xác định rằng tokenizer và mô hình có thể mã hóa một ví dụ đơn lẻ, bước tiếp theo là mã hóa toàn bộ tập dữ liệu để có thể đưa vào mô hình XLM-R để fine-tune. Như đã thấy trong Chương 2, thư viện 🤗 Datasets cung cấp cách nhanh chóng để token hóa một Dataset bằng phương thức map(). Để thực hiện điều này, chúng ta cần định nghĩa một hàm như sau:
1
function(examples: Dict[str, List]) -> Dict[str, List]
Ở đây, examples tương đương với một slide của Dataset, ví dụ: `panx_de[‘train’][:10]. Vì XLM-R tokenizer trả về ID token cho đầu vào mô hình, chúng ta cần bổ sung thêm attention mask và ID nhãn để gán thông tin về nhãn của từng token.
Theo tài liệu của 🤗 Transformers, hãy xem cách áp dụng nó với một câu tiếng Đức đơn giản. Bước đầu tiên, trích xuất danh sách từ và nhãn dưới dạng danh sách thông thường:
1
words, labels = de_example["tokens"], de_example["ner_tags"]
Tiếp theo, chúng ta tokenize từng từ và sử dụng tham số is_split_into_words để báo cho tokenizer rằng chuỗi đầu vào đã được chia thành các từ riêng lẻ:
1
2
3
tokenized_input = xlmr_tokenizer(de_example["tokens"], is_split_into_words=True)
tokens = xlmr_tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
pd.DataFrame([tokens], index=["Tokens"])

Trong ví dụ trên, ta thấy rằng tokenizer đã tách từ “Einwohner” thành hai phần nhỏ: “_Einwohner” và “n”. Vì quy ước nhãn B-LOC chỉ gán cho token đầu tiên của từ, chúng ta cần một cách để ánh xạ subword vào cùng một từ gốc. Rất may, tokenized_input là một lớp có chứa phương thức word_ids(), giúp giải quyết vấn đề này:
1
2
word_ids = tokenized_input.word_ids()
pd.DataFrame([tokens, word_ids], index=["Tokens", "Word IDs"])

Ở đây, chúng ta có thể thấy rằng word_ids đã ánh xạ từng subword vào chỉ mục tương ứng trong chuỗi words, vì vậy subword đầu tiên, “2.000”, được gán chỉ mục 0, trong khi “Einwohner” và “n” được gán chỉ mục 1 (vì “Einwohner” là từ thứ hai trong words). Chúng ta cũng có thể thấy rằng các token đặc biệt như và được ánh xạ thành None. Hãy đặt -100 làm nhãn cho các token đặc biệt này và các subword mà chúng ta muốn loại bỏ trong quá trình huấn luyện:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
if word_idx is None or word_idx == previous_word_idx:
label_ids.append(-100)
elif word_idx != previous_word_idx:
label_ids.append(labels[word_idx])
previous_word_idx = word_idx
labels = [index2tag[l] if l != -100 else "IGN" for l in label_ids]
index = ["Tokens", "Word IDs", "Label IDs", "Labels"]
pd.DataFrame([tokens, word_ids, label_ids, labels], index=index)
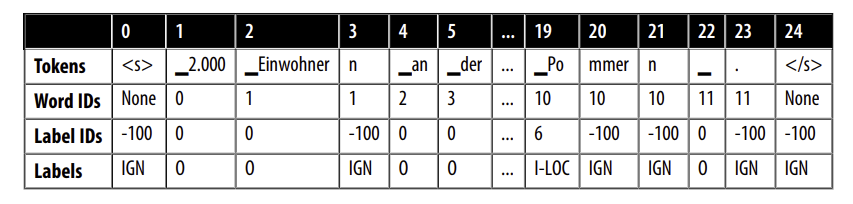
Lý do chúng ta chọn -100 làm ID để ẩn các đại diện subword là vì trong PyTorch, lớp mất mát cross-entropy torch.nn.CrossEntropyLoss có một thuộc tính gọi là ignore_index với giá trị là -100. Chỉ số này sẽ bị bỏ qua trong quá trình huấn luyện, do đó ta có thể sử dụng nó để bỏ qua các token liên kết với các subword liên tiếp.
Vậy là xong! Chúng ta có thể thấy rõ cách các nhãn ID được căn chỉnh với các token, vì vậy hãy mở rộng điều này ra toàn bộ tập dữ liệu bằng cách định nghĩa một hàm bao bọc tất cả logic:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def tokenize_and_align_labels(examples):
tokenized_inputs = xlmr_tokenizer(examples["tokens"], truncation=True,
is_split_into_words=True)
labels = []
for idx, label in enumerate(examples["ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=idx)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
if word_idx is None or word_idx == previous_word_idx:
label_ids.append(-100)
else:
label_ids.append(label[word_idx])
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
Bây giờ chúng ta có tất cả các thành phần chúng ta cần để mã hóa từng bộ dữ liệu, vì vậy hãy để viết một hàm mà chúng ta có thể dùng:
1
2
3
def encode_panx_dataset(corpus):
return corpus.map(tokenize_and_align_labels, batched=True,
remove_columns=['langs', 'ner_tags', 'tokens'])
Bằng cách áp dụng hàm này cho một đối tượng DataSetDict, chúng ta sẽ nhận được một đối tượng tập dữ liệu được mã hóa cho mỗi bộ dữ liệu. Hãy để sử dụng điều này để mã hóa German corpus:
1
panx_de_encoded = encode_panx_dataset(panx_ch["de"])
Bây giờ chúng ta đã có một mô hình và một bộ dữ liệu, chúng ta cần xác định performance metric.
Performance Measures
Đánh giá mô hình dựa trên nhiệm vụ NER tương tự như đánh giá mô hình phân loại văn bản và thông thường báo cáo kết quả cho precision, recall và $F_1$ score. Sự khác biệt duy nhất là tất cả các từ con của một từ cần được dự đoán chính xác thì mới được coi như là đúng. May mắn thay, có một thư viện tiện lợi tên là Seqeval được thiết kế cho các loại nhiệm vụ này. Ví dụ: đưa vào một số thẻ NER và model predictions, chúng ta có thể tính toán các số liệu thông qua hàm seqeval.
1
2
3
4
5
6
from seqeval.metrics import classification_report
y_true = [["O", "O", "O", "B-MISC", "I-MISC", "I-MISC", "O"],
["B-PER", "I-PER", "O"]]
y_pred = [["O", "O", "B-MISC", "I-MISC", "I-MISC", "I-MISC", "O"],
["B-PER", "I-PER", "O"]]
print(classification_report(y_true, y_pred))
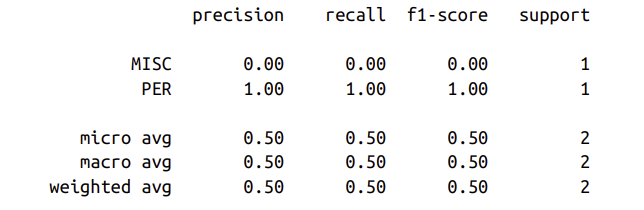
Như chúng ta có thể thấy, seqeval mong đợi các dự đoán và nhãn là danh sách các danh sách, với mỗi danh sách tương ứng với một ví dụ duy nhất trong bộ validation hoặc bộ test. Để tích hợp các số liệu này trong quá trình đào tạo, chúng ta cần một hàm có thể lấy đầu ra của mô hình và chuyển đổi chúng thành các danh sách mà seqeval mong đợi. Sau đây thực hiện thủ thuật bằng cách đảm bảo chúng ta bỏ qua ID nhãn được liên kết với các từ phụ tiếp theo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import numpy as np
def align_predictions(predictions, label_ids):
preds = np.argmax(predictions, axis=2)
batch_size, seq_len = preds.shape
labels_list, preds_list = [], []
for batch_idx in range(batch_size):
example_labels, example_preds = [], []
for seq_idx in range(seq_len):
# Ignore label IDs = -100
if label_ids[batch_idx, seq_idx] != -100:
example_labels.append(index2tag[label_ids[batch_idx][seq_idx]])
example_preds.append(index2tag[preds[batch_idx][seq_idx]])
labels_list.append(example_labels)
preds_list.append(example_preds)
return preds_list, labels_list
Giờ chúng ta hãy huấn luyện model nào!
Fine-Tuning XLM-RoBERTa
Bây giờ chúng ta có tất cả các thành phần để fine-tune mô hình! Chiến lược đầu tiên của chúng ta sẽ là fine-tune mô hình cơ sở trên bộ dữ liệu con của Tiếng Đức của Pan-X và sau đó đánh giá hiệu suất ngôn ngữ zero-shot cross-lingual trên tiếng Pháp, tiếng Ý và tiếng Anh. Như thường lệ, chúng ta sẽ sử dụng 🤗 Transformers Trainer để xử lý training loop, vì vậy trước tiên chúng ta cần định nghĩa các thuộc tính bằng cách sử dụng lớp TrainingArguments.
1
2
3
4
5
6
7
8
9
10
11
from transformers import TrainingArguments
num_epochs = 3
batch_size = 24
logging_steps = len(panx_de_encoded["train"]) // batch_size
model_name = f"{xlmr_model_name}-finetuned-panx-de"
training_args = TrainingArguments(
output_dir=model_name, log_level="error", num_train_epochs=num_epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size, evaluation_strategy="epoch",
save_steps=1e6, weight_decay=0.01, disable_tqdm=False,
logging_steps=logging_steps, push_to_hub=True)
Ở đây, chúng ta đánh giá các dự đoán của mô hình trên bộ validation ở cuối mỗi epoch, điều chỉnh weight decay và đặt save_steps thành một số lớn để vô hiệu hóa checkpointing và do đó tăng tốc độ training.
Đây cũng là thời điểm thích hợp để đảm bảo rằng chúng ta đã đăng nhập vào Hugging Face Hub (nếu đang làm việc trong terminal, bạn có thể thực hiện lệnh huggingface-cli login thay thế):
1
2
3
from huggingface_hub import notebook_login
notebook_login()
Chúng ta cũng cần thông báo cho Trainer cách tính toán các chỉ số đánh giá trên tập validation, vì vậy ở đây ta có thể sử dụng hàm align_predictions() đã định nghĩa trước đó để trích xuất dự đoán và nhãn theo định dạng mà seqeval yêu cầu để tính toán điểm $F_1$:
1
2
3
4
5
6
from seqeval.metrics import f1_score
def compute_metrics(eval_pred):
y_pred, y_true = align_predictions(eval_pred.predictions, eval_pred.label_ids)
return {"f1": f1_score(y_true, y_pred)}
Bước cuối cùng là định nghĩa một data collator để có thể đệm (pad) mỗi chuỗi đầu vào sao cho chúng có độ dài bằng chuỗi dài nhất trong một batch. 🤗 Transformers cung cấp một data collator chuyên dụng cho bài toán phân loại token, giúp đệm các nhãn cùng với đầu vào:
1
2
3
4
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(xlmr_tokenizer)
Việc đệm nhãn là cần thiết vì, không giống như bài toán phân loại văn bản, nhãn trong bài toán này cũng là các chuỗi. Một chi tiết quan trọng ở đây là các chuỗi nhãn được đệm bằng giá trị $-100$, và như ta đã thấy, giá trị này sẽ bị PyTorch bỏ qua trong các hàm mất mát.
Trong chương này, chúng ta sẽ huấn luyện nhiều mô hình, vì vậy để tránh khởi tạo một mô hình mới cho mỗi Trainer, ta sẽ tạo một phương thức model_init(). Phương thức này sẽ tải một mô hình chưa được huấn luyện và được gọi ở đầu mỗi lần chạy train():
1
2
3
4
5
def model_init():
return (XLMRobertaForTokenClassification
.from_pretrained(xlmr_model_name, config=xlmr_config)
.to(device))
Bây giờ, chúng ta có thể truyền tất cả thông tin này cùng với các tập dữ liệu đã mã hóa vào Trainer:
1
2
3
4
5
6
7
8
9
from transformers import Trainer
trainer = Trainer(
model_init=model_init, args=training_args,
data_collator=data_collator, compute_metrics=compute_metrics,
train_dataset=panx_de_encoded["train"],
eval_dataset=panx_de_encoded["validation"],
tokenizer=xlmr_tokenizer
)
Sau đó, ta chỉ cần chạy vòng lặp huấn luyện như sau và đẩy mô hình cuối cùng lên Hugging Face Hub:
1
2
trainer.train()
trainer.push_to_hub(commit_message="Training completed!")
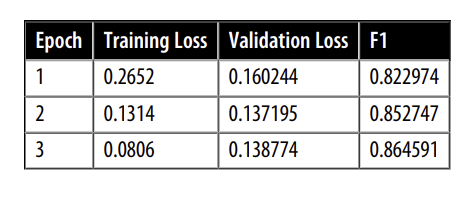
- $F_1$ scores này khá tốt cho một mô hình NER. Để xác nhận rằng mô hình của chúng tôi hoạt động như mong đợi, hãy để thử nghiệm nó trên tiếng Đức:
1
2
text_de = "Jeff Dean ist ein Informatiker bei Google in Kalifornien"
tag_text(text_de, tags, trainer.model, xlmr_tokenizer)

Nó hoạt động! Nhưng chúng ta không bao giờ nên quá tự tin về hiệu suất dựa trên một ví dụ duy nhất. Thay vào đó, chúng ta nên tiến hành một cuộc điều tra đúng đắn và kỹ lưỡng về các lỗi mô hình. Trong phần tiếp theo, chúng ta khám phá cách làm điều này cho nhiệm vụ NER.
Error Analysis
Trước khi đi sâu vào các khía cạnh đa ngôn ngữ của XLM-R, hãy dành một chút thời gian để phân tích lỗi của mô hình. Như đã thấy trong Chương 2, một phân tích lỗi kỹ lưỡng là một trong những khía cạnh quan trọng nhất khi huấn luyện và gỡ lỗi các mô hình transformer (và các mô hình học máy nói chung). Có một số trường hợp mô hình có vẻ hoạt động tốt nhưng thực tế lại có những sai sót nghiêm trọng. Các ví dụ về lỗi trong quá trình huấn luyện có thể bao gồm:
- Có thể chúng ta vô tình che đi quá nhiều token và đồng thời che đi một số nhãn, dẫn đến giảm lỗi một cách giả tạo.
- Hàm
compute_metrics()có thể có lỗi khiến nó đánh giá quá cao hiệu suất thực tế của mô hình. - Có thể chúng ta đã xem lớp 0 hoặc thực thể 0 trong bài toán nhận dạng thực thể có tên (NER) như một lớp bình thường, điều này sẽ làm sai lệch độ chính xác và điểm $F_1$, vì đó là lớp chiếm đa số với khoảng cách rất lớn.
Khi mô hình hoạt động kém hơn nhiều so với mong đợi, việc xem xét lỗi có thể cung cấp những hiểu biết hữu ích và phát hiện ra những lỗi mà chỉ nhìn vào mã nguồn thì khó có thể nhận ra. Ngay cả khi mô hình hoạt động tốt và không có lỗi trong mã, phân tích lỗi vẫn là một công cụ quan trọng để hiểu rõ điểm mạnh và điểm yếu của mô hình. Đây là những khía cạnh mà chúng ta luôn cần ghi nhớ khi triển khai mô hình trong môi trường sản xuất.
Trong phân tích của mình, chúng ta sẽ sử dụng một trong những công cụ mạnh nhất có sẵn, đó là xem xét các mẫu trong tập validation có lỗi cao nhất. Chúng ta có thể tái sử dụng phần lớn các hàm đã xây dựng để phân tích mô hình phân loại chuỗi trong Chương 2, nhưng lần này chúng ta sẽ tính toán lỗi trên từng token trong chuỗi mẫu.
Hãy định nghĩa một phương thức có thể áp dụng cho tập validation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from torch.nn.functional import cross_entropy
def forward_pass_with_label(batch):
# Convert dict of lists to list of dicts suitable for data collator
features = [dict(zip(batch, t)) for t in zip(*batch.values())]
# Pad inputs and labels and put all tensors on device
batch = data_collator(features)
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = batch["labels"].to(device)
with torch.no_grad():
# Pass data through model
output = trainer.model(input_ids, attention_mask)
# Logit.size: [batch_size, sequence_length, classes]
# Predict class with largest logit value on classes axis
predicted_label = torch.argmax(output.logits, axis=-1).cpu().numpy()
# Calculate loss per token after flattening batch dimension with view
loss = cross_entropy(output.logits.view(-1, 7),
labels.view(-1), reduction="none")
# Unflatten batch dimension and convert to numpy array
loss = loss.view(len(input_ids), -1).cpu().numpy()
return {"loss":loss, "predicted_label": predicted_label}
Bây giờ chúng ta có thể áp dụng hàm này cho toàn bộ tập valiation bằng cách sử dụng map() và tải tất cả dữ liệu vào một khung dữ liệu để phân tích thêm:
1
2
3
valid_set = panx_de_encoded["validation"]
valid_set = valid_set.map(forward_pass_with_label, batched=True, batch_size=32)
df = valid_set.to_pandas()
Các token và các nhãn vẫn được mã hóa bằng ID của chúng, vì vậy hãy map các token và nhãn trở lại chuỗi để giúp đọc kết quả dễ dàng hơn. Đối với các token đệm có nhãn là $100$, chúng ta chỉ định một nhãn đặc biệt - IGN, vì vậy chúng ta có thể lọc chúng sau. Chúng tôi cũng loại bỏ tất cả các phần đệm trong loss và predicted_label bằng cách cắt ngắn chúng theo chiều dài của inputs:
1
2
3
4
5
6
7
8
9
10
11
12
index2tag[-100] = "IGN"
df["input_tokens"] = df["input_ids"].apply(
lambda x: xlmr_tokenizer.convert_ids_to_tokens(x))
df["predicted_label"] = df["predicted_label"].apply(
lambda x: [index2tag[i] for i in x])
df["labels"] = df["labels"].apply(
lambda x: [index2tag[i] for i in x])
df['loss'] = df.apply(
lambda x: x['loss'][:len(x['input_ids'])], axis=1)
df['predicted_label'] = df.apply(
lambda x: x['predicted_label'][:len(x['input_ids'])], axis=1)
df.head(1)
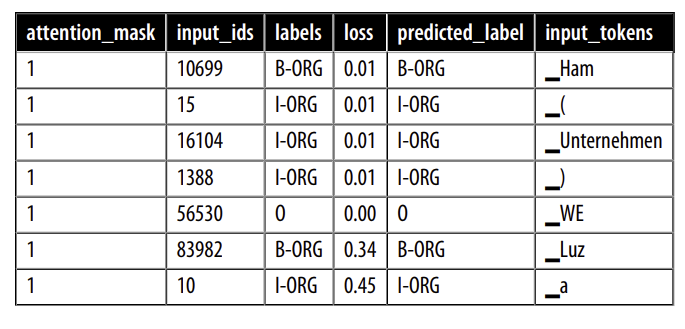
Mỗi cột chứa một danh sách các token, nhãn, nhãn dự đoán, v.v. cho mỗi mẫu. Hãy nhìn vào các token riêng lẻ bằng cách giải nén các danh sách này. Chức năng pandas.Series.explode() cho phép chúng ta thực hiện chính xác điều đó trong một dòng bằng cách tạo ra một hàng cho mỗi phần tử trong danh sách hàng gốc. Vì tất cả các danh sách trong một hàng có cùng độ dài, chúng ta có thể làm điều này song song cho tất cả các cột. Chúng ta cũng bỏ token đệm mà chúng ta đặt tên là IGN, vì loss của chúng bằng không. Cuối cùng, chúng ta chuyển loss sang số thực:
1
2
3
4
df_tokens = df.apply(pd.Series.explode)
df_tokens = df_tokens.query("labels != 'IGN'")
df_tokens["loss"] = df_tokens["loss"].astype(float).round(2)
df_tokens.head(7)
Với dữ liệu trong hình dạng này, giờ đây chúng ta có thể nhóm nó theo input token và tổng hợp các losses cho mỗi token với số lượng, giá trị trung bình và tổng. Cuối cùng, chúng ta sắp xếp dữ liệu tổng hợp theo tổng loss và xem các token nào đã tích lũy nhiều tổn thất nhất trong bộ validation:
1
2
3
4
5
6
7
8
9
10
(
df_tokens.groupby("input_tokens")[["loss"]]
.agg(["count", "mean", "sum"])
.droplevel(level=0, axis=1) # Get rid of multi-level columns
.sort_values(by="sum", ascending=False)
.reset_index()
.round(2)
.head(10)
.T
)
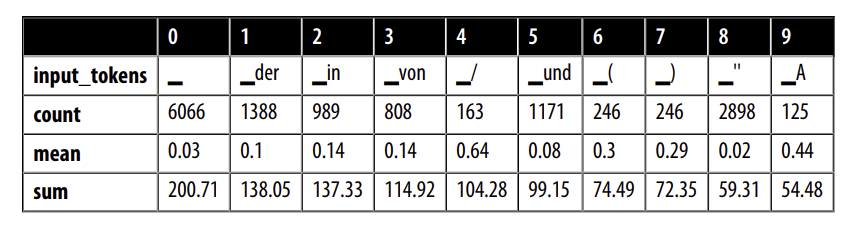
Chúng ta có thể quan sát một số quy luật trong danh sách này:
Ký tự khoảng trắng có tổng loss cao nhất, điều này không gây ngạc nhiên vì nó cũng là ký tự phổ biến nhất trong danh sách. Tuy nhiên, loss trung bình của nó lại thấp hơn nhiều so với các ký tự khác trong danh sách. Điều này có nghĩa là mô hình không gặp khó khăn trong việc phân loại nó.
Các từ như “in”, “von”, “der” và “und” xuất hiện tương đối thường xuyên. Chúng thường đi cùng với các thực thể được đặt tên và đôi khi là một phần của chúng, điều này giải thích tại sao mô hình có thể dễ nhầm lẫn chúng.
Dấu ngoặc đơn, dấu gạch chéo và các chữ cái viết hoa ở đầu từ hiếm gặp hơn nhưng có loss trung bình tương đối cao. Chúng tôi sẽ điều tra thêm về chúng.
Chúng ta cũng có thể nhóm các ID nhãn và xem xét loss của từng lớp:
1
2
3
4
5
6
7
8
9
(
df_tokens.groupby("labels")[["loss"]]
.agg(["count", "mean", "sum"])
.droplevel(level=0, axis=1)
.sort_values(by="mean", ascending=False)
.reset_index()
.round(2)
.T
)
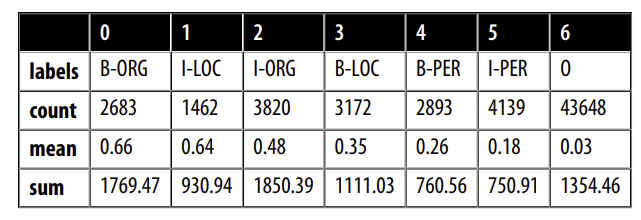
Chúng ta thấy rằng B-ORG có loss trung bình cao nhất, điều này có nghĩa là việc xác định phần đầu của một tổ chức gây khó khăn cho mô hình của chúng ta.
Chúng ta có thể phân tích sâu hơn bằng cách vẽ ma trận nhầm lẫn của việc phân loại token, trong đó ta thấy rằng phần đầu của một tổ chức thường bị nhầm lẫn với token I-ORG ngay sau đó.
1
2
3
4
5
6
7
8
9
10
11
12
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
def plot_confusion_matrix(y_preds, y_true, labels):
cm = confusion_matrix(y_true, y_preds, normalize="true")
fig, ax = plt.subplots(figsize=(6, 6))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(cmap="Blues", values_format=".2f", ax=ax, colorbar=False)
plt.title("Normalized confusion matrix")
plt.show()
plot_confusion_matrix(df_tokens["labels"], df_tokens["predicted_label"], tags.names)
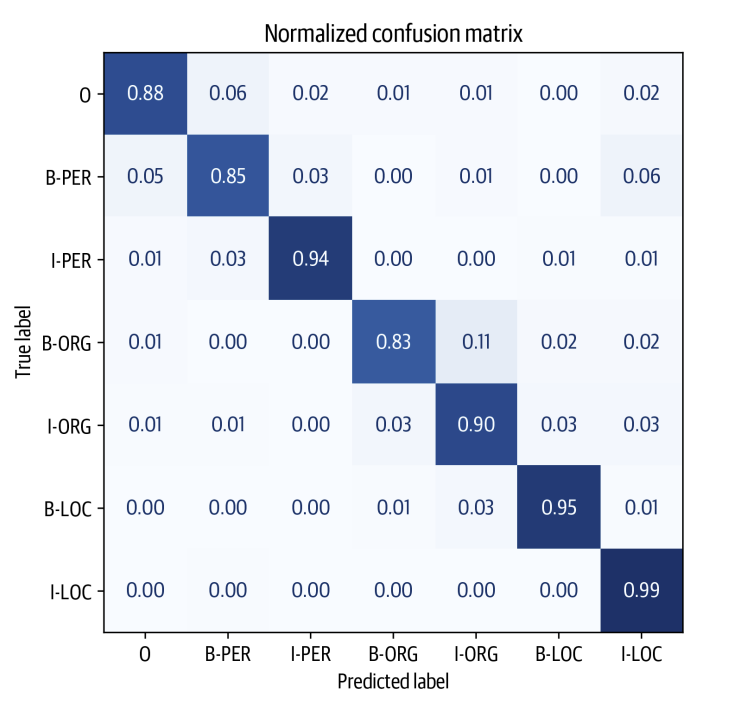
Từ biểu đồ, chúng ta có thể thấy rằng mô hình có xu hướng nhầm lẫn giữa B-ORG và I-ORG nhiều nhất. Ngoài ra, mô hình khá tốt trong việc phân loại các thực thể còn lại, điều này được thể hiện qua dạng gần như đường chéo của ma trận nhầm lẫn.
Bây giờ, chúng ta đã kiểm tra các lỗi ở cấp độ token, hãy tiếp tục và xem xét các chuỗi với loss cao. Đối với tính toán này, chúng ta sẽ xem lại DataFrame chưa được giải quyết và tính tổng loss bằng cách tổng hợp loss trên mỗi token. Để làm điều này, trước tiên, hãy để viết một hàm giúp chúng ta hiển thị các chuỗi token với các nhãn và các loss:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def get_samples(df):
for _, row in df.iterrows():
labels, preds, tokens, losses = [], [], [], []
for i, mask in enumerate(row["attention_mask"]):
if i not in {0, len(row["attention_mask"])}:
labels.append(row["labels"][i])
preds.append(row["predicted_label"][i])
tokens.append(row["input_tokens"][i])
losses.append(f"{row['loss'][i]:.2f}")
df_tmp = pd.DataFrame({"tokens": tokens, "labels": labels,
"preds": preds, "losses": losses}).T
yield df_tmp
df["total_loss"] = df["loss"].apply(sum)
df_tmp = df.sort_values(by="total_loss", ascending=False).head(3)
for sample in get_samples(df_tmp):
display(sample)
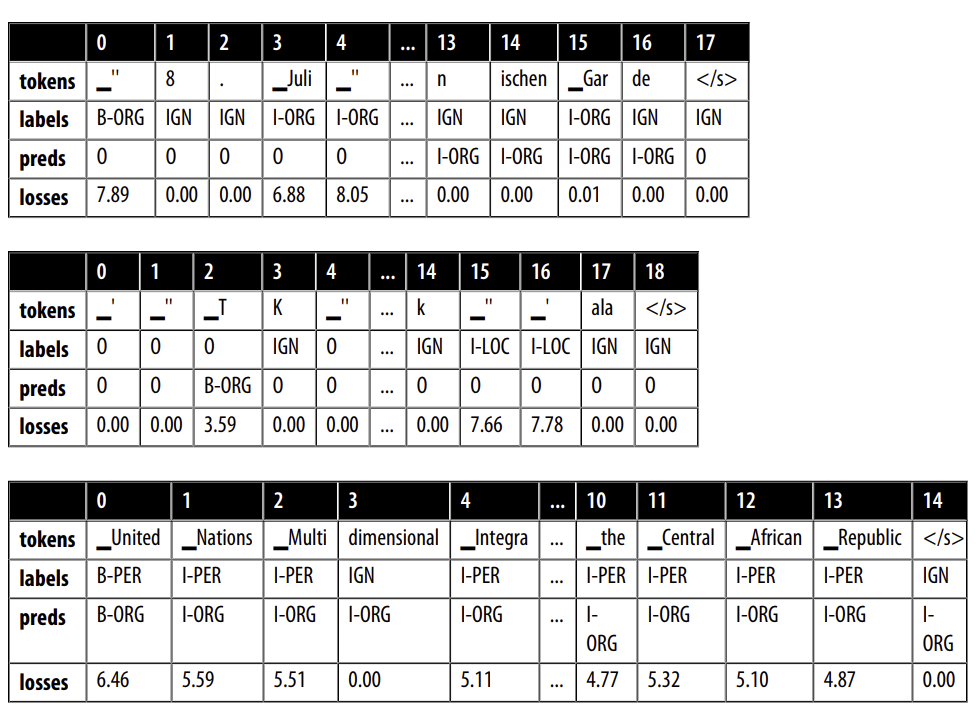
Rõ ràng là có điều gì đó không ổn với các nhãn của những mẫu này; ví dụ, United Nations và Central African Republic đều được gán nhãn là người! Đồng thời, “8. Juli” trong ví dụ đầu tiên được gán nhãn là một tổ chức. Hóa ra các chú thích cho tập dữ liệu PAN-X được tạo ra thông qua một quy trình tự động. Những chú thích như vậy thường được gọi là “dilver standard” (trái ngược với “gold standrad” của các chú thích do con người tạo ra), và không có gì ngạc nhiên khi có những trường hợp phương pháp tự động thất bại trong việc tạo ra nhãn hợp lý. Thực tế, các chế độ lỗi như vậy không chỉ giới hạn ở các phương pháp tự động; ngay cả khi con người chú thích cẩn thận dữ liệu, lỗi vẫn có thể xảy ra khi sự tập trung của người chú thích giảm dần hoặc họ đơn giản là hiểu sai câu.
Một điều khác mà chúng ta nhận thấy trước đó là dấu ngoặc đơn và dấu gạch chéo có tổn thất tương đối cao. Hãy xem một vài ví dụ về các chuỗi với dấu ngoặc đơn mở:
1
2
3
df_tmp = df.loc[df["input_tokens"].apply(lambda x: u"\u2581(" in x)].head(2)
for sample in get_samples(df_tmp):
display(sample)
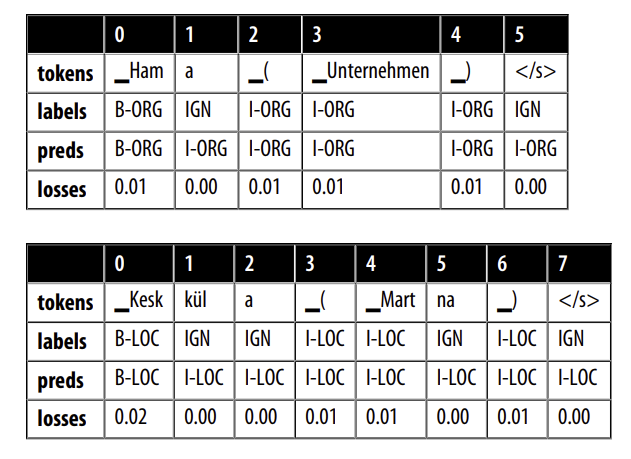
Nói chung, chúng ta sẽ không bao gồm dấu ngoặc đơn và nội dung của nó như một phần của thực thể được đặt tên, nhưng dường như đây là cách mà quá trình trích xuất tự động đã chú thích các tài liệu. Trong các ví dụ khác, dấu ngoặc đơn chứa thông tin địa lý. Mặc dù đây thực sự là một địa điểm, chúng ta có thể muốn tách nó ra khỏi vị trí ban đầu trong các chú thích. Tập dữ liệu này bao gồm các bài viết Wikipedia bằng nhiều ngôn ngữ khác nhau, và các tiêu đề bài viết thường chứa một số loại giải thích trong dấu ngoặc đơn. Ví dụ, trong ví dụ đầu tiên, văn bản trong dấu ngoặc đơn chỉ ra rằng Hama là một “Unternehmen”, hoặc công ty trong tiếng Anh. Đây là những chi tiết quan trọng cần biết khi chúng ta triển khai mô hình, vì chúng có thể ảnh hưởng đến hiệu suất của toàn bộ quy trình mà mô hình là một phần của nó.
Với một phân tích tương đối đơn giản, chúng ta đã xác định được một số điểm yếu trong cả mô hình và tập dữ liệu. Trong một trường hợp sử dụng thực tế, chúng ta sẽ lặp lại bước này, làm sạch và cập nhật tập dữ liệu, train lại mô hình, phân tích lỗi mới đến khi chúng ta hài lòng với kết quả của mô hình.
Ở trên, chúng ta đã phân tích lỗi trên một ngôn ngữ duy nhất, nhưng chúng ta cũng quan tâm đến hiệu suất trên nhiều ngôn ngữ khác nhau. Trong phần tiếp theo, chúng ta sẽ thực hiện một số thí nghiệm để xem khả năng cross-lingual transfer của XLM-R hoạt động tốt đến đâu.
6. Cross-Lingual Transfer
Bây giờ, sau khi đã fine-tune XLM-R trên tiếng Đức, chúng ta có thể đánh giá khả năng chuyển giao sang các ngôn ngữ khác bằng phương thức predict() của Trainer. Vì chúng ta dự định đánh giá trên nhiều ngôn ngữ, hãy tạo một hàm đơn giản giúp thực hiện điều này:
1
2
def get_f1_score(trainer, dataset):
return trainer.predict(dataset).metrics["test_f1"]
Chúng ta có thể sử dụng hàm này để kiểm tra hiệu suất trên tập kiểm tra và lưu kết quả trong một dict:
1
2
3
4
f1_scores = defaultdict(dict)
f1_scores["de"]["de"] = get_f1_score(trainer, panx_de_encoded["test"])
print(f"F1-score của mô hình [de] trên tập dữ liệu [de]: {f1_scores['de']['de']:.3f}")
# F1-score của mô hình [de] trên tập dữ liệu [de]: 0.868
Đây là kết quả khá tốt đối với bài toán NER. Các chỉ số của chúng tôi nằm trong khoảng $85\%$, và có thể thấy rằng mô hình gặp khó khăn nhất với các thực thể ORG, có thể do các thực thể này ít xuất hiện trong dữ liệu huấn luyện và nhiều tên tổ chức khá hiếm trong từ vựng của XLM-R. Vậy còn các ngôn ngữ khác thì sao? Để khởi động, hãy thử xem mô hình fine-tune trên tiếng Đức hoạt động thế nào trên tiếng Pháp:
1
2
text_fr = "Jeff Dean est informaticien chez Google en Californie"
tag_text(text_fr, tags, trainer.model, xlmr_tokenizer)

Không tệ! Mặc dù tên riêng và tổ chức giống nhau trong cả hai ngôn ngữ, mô hình đã gán nhãn chính xác bản dịch tiếng Pháp của “Kalifornien”. Tiếp theo, hãy định lượng hiệu suất của mô hình tiếng Đức trên toàn bộ tập kiểm tra tiếng Pháp bằng cách viết một hàm đơn giản để mã hóa tập dữ liệu và tạo báo cáo phân loại:
1
2
3
4
5
6
7
def evaluate_lang_performance(lang, trainer):
panx_ds = encode_panx_dataset(panx_ch[lang])
return get_f1_score(trainer, panx_ds["test"])
f1_scores["de"]["fr"] = evaluate_lang_performance("fr", trainer)
print(f"F1-score of [de] model on [fr] dataset: {f1_scores['de']['fr']:.3f}")
# F1-score of [de] model on [fr] dataset: 0.714
Mặc dù chúng ta thấy có sự giảm khoảng $15$ điểm trong chỉ số micro-averaged, hãy nhớ rằng mô hình của chúng ta chưa từng thấy bất kỳ một mẫu dữ liệu tiếng Pháp nào có nhãn! Nói chung, mức độ giảm hiệu năng có liên quan đến khoảng cách ngôn ngữ giữa các ngôn ngữ với nhau. Mặc dù tiếng Đức và tiếng Pháp đều thuộc nhóm ngôn ngữ Ấn-Âu, về mặt kỹ thuật chúng thuộc về hai nhóm ngôn ngữ khác nhau: Germanic và Romance.
Tiếp theo, hãy đánh giá hiệu năng trên tiếng Ý. Vì tiếng Ý cũng là một ngôn ngữ thuộc nhóm Romance, chúng ta kỳ vọng rằng kết quả sẽ tương tự với kết quả trên tiếng Pháp:
1
2
3
f1_scores["de"]["it"] = evaluate_lang_performance("it", trainer)
print(f"F1-score của [de] model trên [it] dataset: {f1_scores['de']['it']:.3f}")
# F1-score của [de] model trên [en] dataset: 0.589
Thật ngạc nhiên, mô hình của chúng ta hoạt động tệ hơn trên tiếng Anh, mặc dù trực giác của chúng ta cho rằng tiếng Đức sẽ giống tiếng Anh hơn tiếng Pháp. Vì đã fine-tune trên tiếng Đức và thực hiện zero-shot transfer cho tiếng Pháp và tiếng Anh, hãy cùng tìm hiểu khi nào thì việc fine-tune trực tiếp trên ngôn ngữ mục tiêu là cần thiết.
When Does Zero-Shot Transfer Make Sense?
Cho đến nay, chúng ta đã thấy rằng việc fine-tuning XLM-R trên tập dữ liệu tiếng Đức đạt F1-score khoảng $85\%$, và không cần thêm bất kỳ đào tạo bổ sung nào, mô hình vẫn có thể đạt hiệu năng khiêm tốn trên các ngôn ngữ khác trong tập dữ liệu của chúng ta. Câu hỏi đặt ra là: Kết quả này có thực sự tốt không và chúng so với mô hình XLM-R được fine-tune trên một tập dữ liệu đơn ngữ như thế nào?
Trong phần này, chúng ta sẽ khám phá câu hỏi này bằng cách fine-tune XLM-R trên các tập dữ liệu tiếng Pháp có kích thước tăng dần. Bằng cách theo dõi hiệu năng theo cách này, chúng ta có thể xác định được thời điểm nào việc zero-shot cross-lingual transfer là tốt hơn, điều này có thể hữu ích khi ra quyết định liệu có cần thu thập thêm dữ liệu có nhãn hay không.
Để đơn giản, chúng ta sẽ giữ nguyên các hyperparameter từ lần fine-tuning trên tập dữ liệu tiếng Đức, ngoại trừ việc điều chỉnh giá trị logging_steps của TrainingArguments để phù hợp với kích thước tập dữ liệu thay đổi. Chúng ta có thể đóng gói tất cả lại thành một hàm đơn giản nhận đối tượng DatasetDict tương ứng với một kho văn bản đơn ngữ, downsamples bằng num_samples và fine-tunes XLM-R để trả lại epochs tốt nhất:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def train_on_subset(dataset, num_samples):
train_ds = dataset["train"].shuffle(seed=42).select(range(num_samples))
valid_ds = dataset["validation"]
test_ds = dataset["test"]
training_args.logging_steps = len(train_ds) // batch_size
trainer = Trainer(model_init=model_init, args=training_args,
data_collator=data_collator, compute_metrics=compute_metrics,
train_dataset=train_ds, eval_dataset=valid_ds, tokenizer=xlmr_tokenizer)
trainer.train()
if training_args.push_to_hub:
trainer.push_to_hub(commit_message="Training completed!")
f1_score = get_f1_score(trainer, test_ds)
return pd.DataFrame.from_dict(
{"num_samples": [len(train_ds)], "f1_score": [f1_score]})
Như chúng ta đã fine-tune trên kho văn bản của Tiếng Đức, chúng ta cũng cần mã hóa văn bản của Pháp thành input IDs, attention_mask và label IDs:
1
panx_fr_encoded = encode_panx_dataset(panx_ch["fr"])
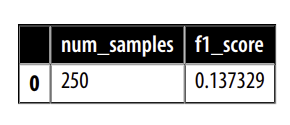
Tiếp theo, hãy để kiểm tra xem hàm của chúng ta có hoạt động không bằng cách chạy nó trên một bộ đào tạo nhỏ gồm 250 ví dụ:
1
2
3
training_args.push_to_hub = False
metrics_df = train_on_subset(panx_fr_encoded, 250)
metrics_df
Bây giờ, hãy để tăng kích thước bộ đào tạo của chúng tq lên 500, 1.000, 2.000 và 4.000 ví dụ để có ý tưởng về cách thức hiệu suất tăng lên:
1
2
3
for num_samples in [500, 1000, 2000, 4000]:
metrics_df = metrics_df.append(
train_on_subset(panx_fr_encoded, num_samples), ignore_index=True)
Chúng ta có thể so sánh giữa việc fine-tune trên tiếng Pháp với zero-shot cross-lingual từ Đức bằng cách vẽ các giá trị $F_1$ scores trên bộ test như là một hàm tăng kích thước tập train:
1
2
3
4
5
6
7
8
fig, ax = plt.subplots()
ax.axhline(f1_scores["de"]["fr"], ls="--", color="r")
metrics_df.set_index("num_samples").plot(ax=ax)
plt.legend(["Zero-shot from de", "Fine-tuned on fr"], loc="lower right")
plt.ylim((0, 1))
plt.xlabel("Number of Training Samples")
plt.ylabel("F1 Score")
plt.show()
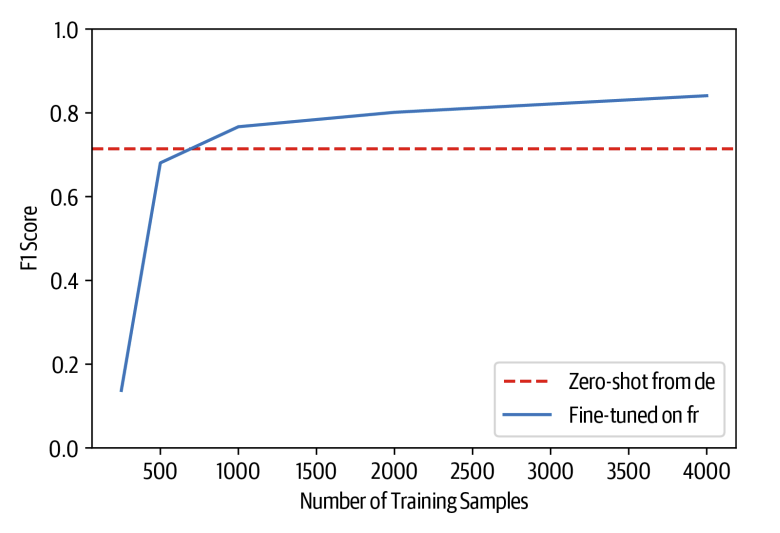
Từ biểu đồ, chúng ta có thể thấy rằng zero-shot transfer vẫn duy trì tính cạnh tranh cho đến khoảng 75% số lượng mẫu huấn luyện, sau đó fine-tuning trên tiếng Pháp đạt mức hiệu suất tương đương với những gì ta có được khi fine-tuning trên tiếng Đức. Tuy nhiên, kết quả này không hề tệ! Theo kinh nghiệm của chúng tôi, việc yêu cầu các chuyên gia trong lĩnh vực gán nhãn thậm chí chỉ vài trăm tài liệu có thể rất tốn kém, đặc biệt là đối với NER, nơi quy trình gán nhãn đòi hỏi mức độ chi tiết cao và tiêu tốn nhiều thời gian.
Có một kỹ thuật cuối cùng mà chúng ta có thể thử để đánh giá khả năng học đa ngôn ngữ: fine-tuning trên nhiều ngôn ngữ cùng lúc! Hãy cùng xem cách thực hiện.
7. Fine-Tuning on Multiple Languages at Once
Cho đến nay, chúng ta đã thấy rằng zero-shot cross-lingual transfer từ tiếng Đức sang tiếng Pháp hoặc tiếng Ý làm giảm hiệu suất khoảng 15 điểm. Một cách để giảm thiểu vấn đề này là fine-tuning trên nhiều ngôn ngữ cùng lúc. Để xem ta có thể đạt được mức cải thiện nào, trước tiên, hãy sử dụng hàm concatenate_datasets() từ 🤗 Datasets để nối tập dữ liệu (corpora) tiếng Đức và tiếng Pháp lại với nhau:
1
2
3
4
5
6
7
8
9
10
11
from datasets import concatenate_datasets
def concatenate_splits(corpora):
multi_corpus = DatasetDict()
for split in corpora[0].keys():
multi_corpus[split] = concatenate_datasets(
[corpus[split] for corpus in corpora]).shuffle(seed=42)
return multi_corpus
panx_de_fr_encoded = concatenate_splits([panx_de_encoded, panx_fr_encoded])
Trong quá trình huấn luyện, chúng ta sẽ sử dụng lại các siêu tham số (hyperparameters) từ các phần trước, do đó ta chỉ cần cập nhật số bước ghi log (logging steps), mô hình và tập dữ liệu trong trainer:
1
2
3
4
5
6
7
8
9
10
11
12
training_args.logging_steps = len(panx_de_fr_encoded["train"]) // batch_size
training_args.push_to_hub = True
training_args.output_dir = "xlm-roberta-base-finetuned-panx-de-fr"
trainer = Trainer(model_init=model_init, args=training_args,
data_collator=data_collator, compute_metrics=compute_metrics,
tokenizer=xlmr_tokenizer, train_dataset=panx_de_fr_encoded["train"],
eval_dataset=panx_de_fr_encoded["validation"])
trainer.train()
trainer.push_to_hub(commit_message="Training completed!")
Hãy cùng xem mô hình hoạt động ra sao trên tập kiểm tra (test set) của từng ngôn ngữ:
1
2
3
4
5
6
7
8
for lang in langs:
f1 = evaluate_lang_performance(lang, trainer)
print(f"F1-score của mô hình [de-fr] trên tập dữ liệu [{lang}]: {f1:.3f}")
# F1-score of [de-fr] model on [de] dataset: 0.866
# F1-score of [de-fr] model on [fr] dataset: 0.868
# F1-score of [de-fr] model on [it] dataset: 0.815
# F1-score of [de-fr] model on [en] dataset: 0.677
Mô hình hoạt động tốt hơn trên tập tiếng Pháp so với trước đây, đạt hiệu suất ngang bằng với tập kiểm tra tiếng Đức. Đáng chú ý, hiệu suất của nó trên các tập tiếng Ý và tiếng Anh cũng tăng lên khoảng 10 điểm! Như vậy, ngay cả khi chỉ thêm dữ liệu huấn luyện từ một ngôn ngữ khác, ta cũng có thể cải thiện hiệu suất của mô hình trên các ngôn ngữ chưa từng thấy.
Giờ hãy hoàn thành phân tích của chúng ta bằng cách so sánh hiệu suất fine-tuning trên từng ngôn ngữ riêng lẻ với phương pháp học đa ngôn ngữ trên toàn bộ tập dữ liệu. Vì mô hình đã được fine-tuned trên tập tiếng Đức, ta có thể tiếp tục fine-tuning trên các ngôn ngữ còn lại bằng hàm train_on_subset(), với num_samples bằng số lượng mẫu trong tập huấn luyện:
1
2
3
4
5
6
7
8
9
10
11
12
13
corpora = [panx_de_encoded]
# Exclude German from iteration
for lang in langs[1:]:
training_args.output_dir = f"xlm-roberta-base-finetuned-panx-{lang}"
# Fine-tune on monolingual corpus
ds_encoded = encode_panx_dataset(panx_ch[lang])
metrics = train_on_subset(ds_encoded, ds_encoded["train"].num_rows)
# Collect F1-scores in common dict
f1_scores[lang][lang] = metrics["f1_score"][0]
# Add monolingual corpus to list of corpora to concatenate
corpora.append(ds_encoded)
Bây giờ chúng ta đã fine-tune trên tập dữ liệu của từng ngôn ngữ, bước tiếp theo là nối tất cả các phần lại để tạo ra một tập dữ liệu đa ngôn ngữ bao gồm cả bốn ngôn ngữ. Tương tự như trong phân tích trước về tiếng Đức và tiếng Pháp, ta có thể sử dụng hàm concatenate_splits() để thực hiện bước này trên danh sách các tập dữ liệu đã tạo ở bước trước:
1
corpora_encoded = concatenate_splits(corpora)
Sau khi có tập dữ liệu đa ngôn ngữ, ta tiếp tục các bước quen thuộc với trainer:
1
2
3
4
5
6
7
8
9
10
11
training_args.logging_steps = len(corpora_encoded["train"]) // batch_size
training_args.output_dir = "xlm-roberta-base-finetuned-panx-all"
trainer = Trainer(model_init=model_init, args=training_args,
data_collator=data_collator, compute_metrics=compute_metrics,
tokenizer=xlmr_tokenizer, train_dataset=corpora_encoded["train"],
eval_dataset=corpora_encoded["validation"])
trainer.train()
trainer.push_to_hub(commit_message="Training completed!")
Bước cuối cùng là tạo dự đoán từ trainer trên tập kiểm tra của từng ngôn ngữ. Điều này giúp ta hiểu rõ hơn việc học đa ngôn ngữ có thực sự hiệu quả hay không. Ta sẽ thu thập các $F_1$-score vào dictionary f1_scores, sau đó tạo một DataFrame để tóm tắt kết quả chính từ các thí nghiệm đa ngôn ngữ:
1
2
3
4
5
6
7
8
9
10
11
12
for idx, lang in enumerate(langs):
f1_scores["all"][lang] = get_f1_score(trainer, corpora[idx]["test"])
scores_data = {"de": f1_scores["de"],
"each": {lang: f1_scores[lang][lang] for lang in langs},
"all": f1_scores["all"]}
f1_scores_df = pd.DataFrame(scores_data).T.round(4)
f1_scores_df.rename_axis(index="Fine-tune on", columns="Evaluated on", inplace=True)
f1_scores_df
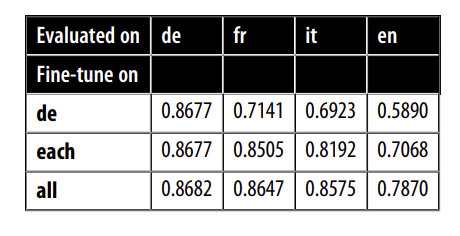
Từ các kết quả này, ta có thể rút ra một số kết luận chung:
- Học đa ngôn ngữ có thể mang lại những cải thiện đáng kể về hiệu suất, đặc biệt là đối với các ngôn ngữ có ít tài nguyên hoặc trong trường hợp chuyển giao kiến thức giữa các ngôn ngữ tương đồng. Trong các thí nghiệm của chúng ta, có thể thấy rằng tiếng Đức, tiếng Pháp và tiếng Ý đạt hiệu suất tương tự trong danh mục
all, cho thấy rằng những ngôn ngữ này tương đồng với nhau hơn so với tiếng Anh. - Như một chiến lược tổng quát, việc tập trung vào cross-lingual transfer trong cùng một họ ngôn ngữ là một ý tưởng tốt, đặc biệt khi xử lý các hệ thống chữ viết khác nhau như tiếng Nhật.
8. Interacting with Model Widgets
Trong chương này, chúng ta đã cung cấp khá nhiều mô hình fine-tuned lên Hub. Mặc dù bạn có thể sử dụng hàm pipeline() để tương tác với chúng trên máy cục bộ của mình, nhưng Hub cung cấp widgets rất tuyệt vời cho kiểu workflow này. Một ví dụ được hiển thị trong Hình 4-5 về checkpoint transformersbook/xlm-roberta-base-finetuned-panx-all, mà như bạn thấy, đã làm rất tốt trong việc nhận diện tất cả các thực thể của một văn bản tiếng Đức.

8. Kết luận
Trong chương này, chúng ta đã trình bày cách giải quyết một bài toán NLP trên một tập dữ liệu đa ngôn ngữ bằng một transformer duy nhất được pretrain trên 100 ngôn ngữ: XLM-R. Mặc dù chúng ta đã cho thấy rằng việc cross-lingual transfer từ tiếng Đức sang tiếng Pháp có tính cạnh tranh cao ngay cả khi chỉ có một số lượng nhỏ ví dụ được gắn nhãn có sẵn để fine-tuning, nhưng hiệu suất tốt này thường không xảy ra nếu ngôn ngữ đích khác biệt đáng kể so với ngôn ngữ mà mô hình nền đã fine-tuned hoặc không nằm trong số 100 ngôn ngữ được sử dụng trong quá trình pretraining. Những đề xuất gần đây như MAD-X được thiết kế chính xác cho các trường hợp này. Các kịch bản với nguồn lực hạn chế, và vì MAD-X được xây dựng dựa trên nền tảng của 🤗 Transformers, bạn có thể dễ dàng điều chỉnh mã trong chương này để làm việc với nó!⁶
Cho đến nay, chúng ta đã xem xét hai tác vụ: sequence classification và token classification. Cả hai đều thuộc lĩnh vực natural language understanding, nơi văn bản được tổng hợp thành các dự đoán. Trong chương tiếp theo, chúng ta sẽ lần đầu tiên khám phá về text generation, nơi mà không chỉ đầu vào mà cả đầu ra của mô hình đều là văn bản.