Prompt Engineering
Prompt Engineering là kỹ thuật tối ưu hóa các lệnh (prompt) để hướng dẫn mô hình AI, đặc biệt là các mô hình ngôn ngữ lớn như GPT, đưa ra phản hồi chính xác và hữu ích. Bằng cách thiết kế prompt phù hợp, người dùng có thể tận dụng tối đa khả năng của AI trong nhiều nhiệm vụ khác nhau, từ viết lách đến giải quyết vấn đề. Đây là một kỹ năng quan trọng giúp khai thác hiệu quả tiềm năng của trí tuệ nhân tạo trong thực tế.
1. Prompt là gì ?
- Prompt là một thuật ngữ dùng trong nhiều lĩnh vực, nhưng phổ biến nhất trong trí tuệ nhân tạo và học máy (AI/ML), đặc biệt là trong các mô hình ngôn ngữ lớn như GPT. Trong ngữ cảnh này, prompt chỉ đoạn văn bản hoặc câu hỏi mà người dùng cung cấp cho mô hình AI để nó trả lời hoặc tạo ra nội dung dựa trên thông tin đó.
- Ví dụ, khi bạn hỏi một câu hỏi cho ChatGPT như:
Hôm nay thời tiết như nào ?
- Câu hỏi trên chính là một prompt. Tóm lại, prompt là một thông tin ban đầu cung cấp để hệ thống thực hiện một nhiệm vụ cụ thể hoặc tạo ra phản hồi.
- Tuy nhiên, việc đặt câu hỏi nhiều người nghĩ là một bước không quan trọng, họ chỉ cần nghĩ rằng mình chỉ cần đặt câu hỏi đúng trọng tâm là được. Với nhiều bài toán đơn giản thì mình chỉ cần hỏi một câu đúng trọng tâm nhưng với những bài toán phức tạp thì nhập phần prompt là cả một công đoạn, hay nhiều người gọi với cái tên rất kiêu là Nghệ thuật viết Prompt hay Kĩ thuật viết Prompt.
2. Các kĩ thuật viết prompt.
Zero-shot Prompting.
- Các mô hình ngôn ngữ lớn (LLMs) ngày nay, chẳng hạn như GPT-3.5 Turbo, GPT-4, và Claude 3, được tinh chỉnh để làm theo hướng dẫn và được huấn luyện trên lượng dữ liệu lớn. Việc huấn luyện trên quy mô lớn giúp những mô hình này có khả năng thực hiện một số nhiệm vụ theo cách “zero-shot”. Zero-shot prompting có nghĩa là prompt được sử dụng để hỏi mô hình không chứa ví dụ hoặc minh họa. Zero-shot prompt trực tiếp hướng dẫn mô hình thực hiện một nhiệm vụ mà không cần thêm ví dụ nào để định hướng nó.
- Như câu hỏi:
Hôm nay thời tiết như nào ?
Chính là Zero-shot prompting, tức mình sẽ đặt câu hỏi trực tiếp mà không thêm các ví dụ hoặc ngữ cảnh phía trước.
- Ví dụ thêm về Zero-shot prompting:
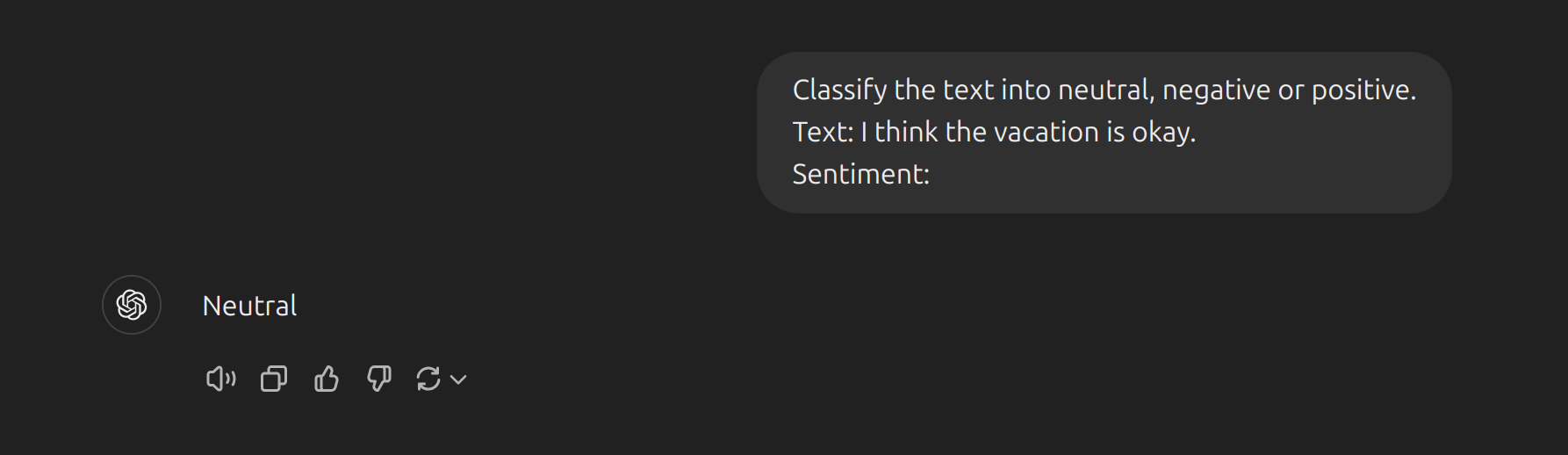
- Lưu ý rằng trong prompt ở trên, chúng ta không cung cấp cho mô hình bất kỳ ví dụ nào về văn bản kèm theo phân loại của chúng, mô hình ngôn ngữ lớn (LLM) đã tự hiểu cảm xúc của văn bản xong phân loại - đó chính là khả năng zero-shot hoạt động.
Instruction Tuning.
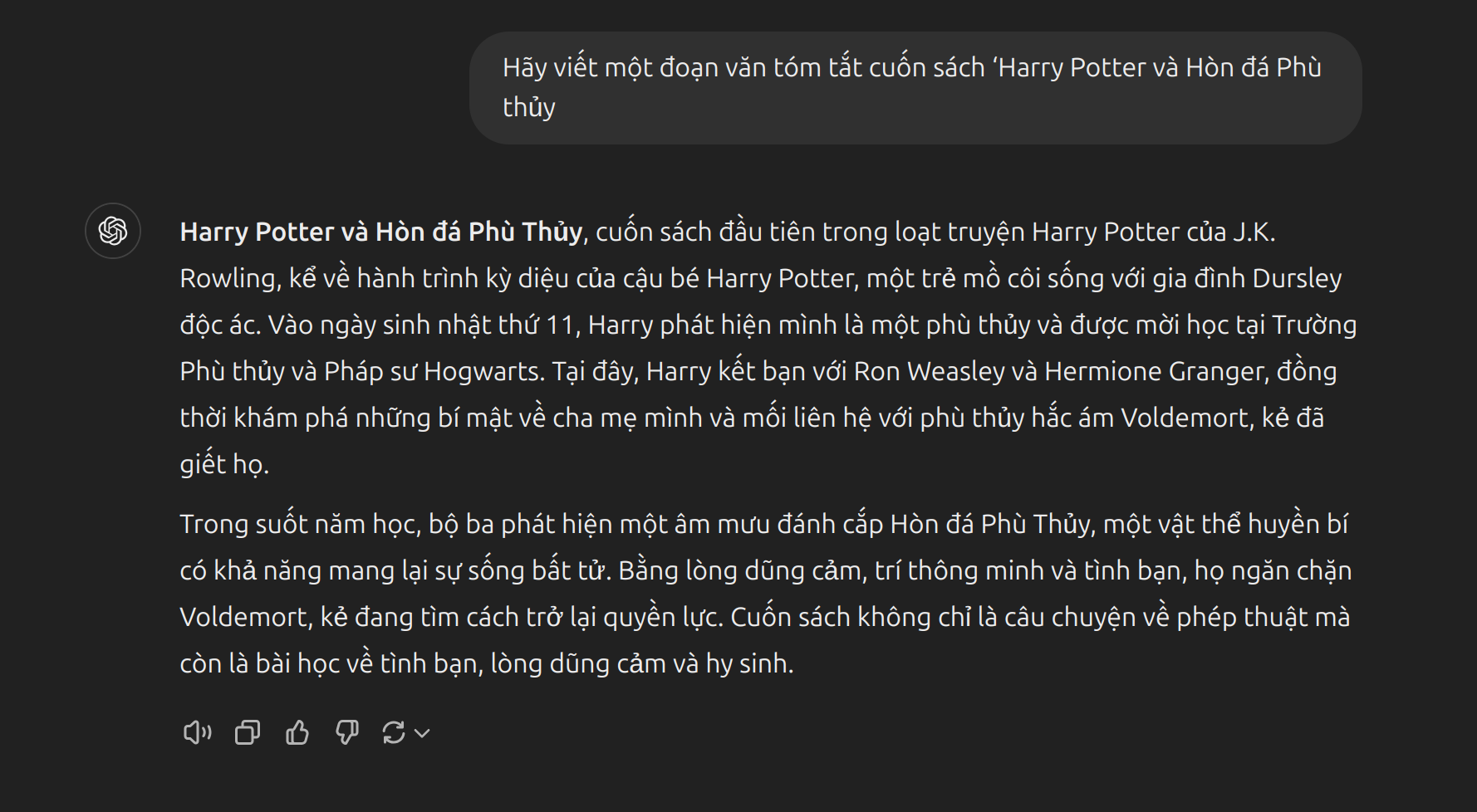
- Instruction Tuning là một phương pháp tinh chỉnh mô hình ngôn ngữ lớn (LLM) nhằm cải thiện khả năng hiểu và làm theo hướng dẫn của mô hình. Hiểu một cách đơn giản là mình sẽ đặt câu prompt và yêu cầu mô hình phải làm gì trong câu prompt đó. Dưới đây là ví dụ đặt prompt sử dụng Instruction Tuning:
- Dưới đây là ví dụ đặt prompt mà không sử dụng Instruction Tuning:

Prompt sử dụng instruction tuning: Mô hình hiểu rằng người dùng yêu cầu tóm tắt, và phản hồi là một đoạn văn ngắn gọn, đúng trọng tâm về nội dung của cuốn sách theo hướng dẫn rõ ràng. Điều này nhờ vào việc mô hình đã được tinh chỉnh để nhận diện và đáp ứng các yêu cầu mang tính chỉ dẫn (instruction-based).
- Prompt không sử dụng instruction tuning: Prompt không có hướng dẫn cụ thể (chỉ là tên cuốn sách), dẫn đến phản hồi không đúng với yêu cầu tóm tắt. Thay vì tóm tắt nội dung sách, mô hình chỉ cung cấp thông tin tổng quan về cuốn sách và ngày xuất bản.
- Như các bạn thấy thì hầu như tất cả câu prompt do người dùng đặt đều sử dụng kĩ thuật instruction tuning để yêu cầu nhiệm vụ cho mô hình.
- Việc sử dụng instruction tuning đã được chứng minh là cải thiện khả năng học so với kĩ thuật zeros-shot (Wei et al., 2022).
Reinforcement Learning from Human Feedback (RLHF).
- Reinforcement Learning from Human Feedback (RLHF), hay Học tăng cường từ phản hồi của con người, là một kỹ thuật trong học máy (machine learning) sử dụng phản hồi từ con người để giúp tinh chỉnh các mô hình AI nhằm cải thiện hiệu suất và phù hợp hơn với kỳ vọng của người dùng. RLHF đặc biệt quan trọng trong việc phát triển các mô hình ngôn ngữ lớn (LLMs) như GPT, nơi yêu cầu khả năng phản hồi theo cách tự nhiên, có đạo đức và hữu ích.
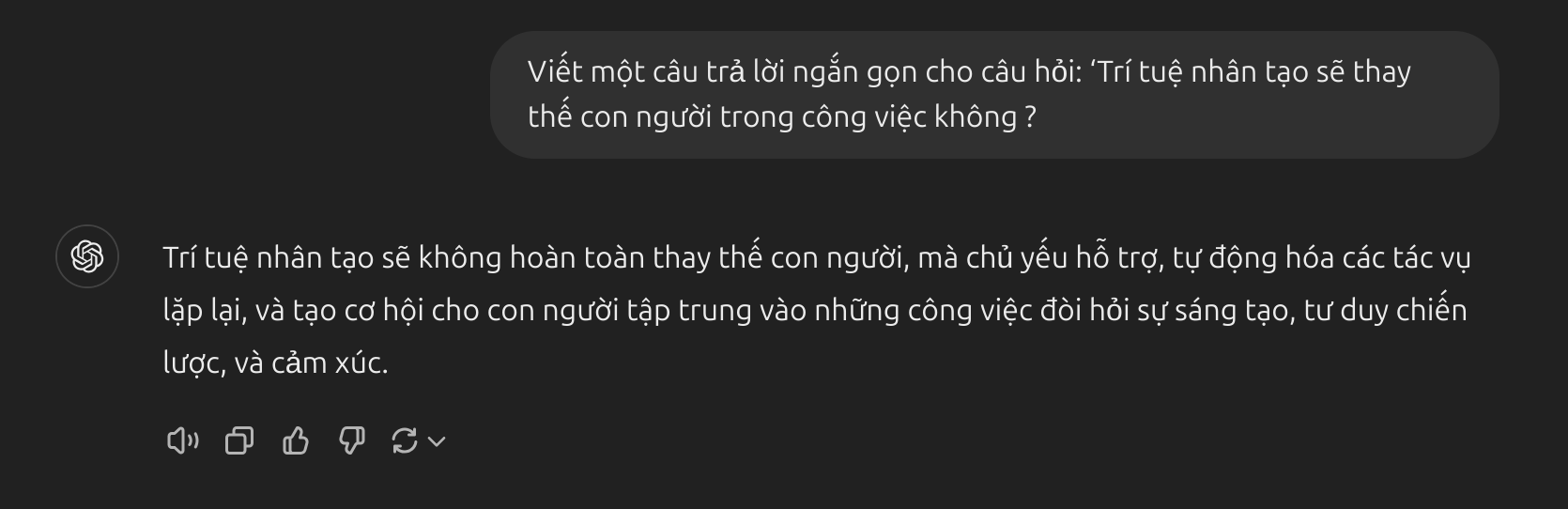
- Dưới đây là ví dụ về model sử dụng RLHF:
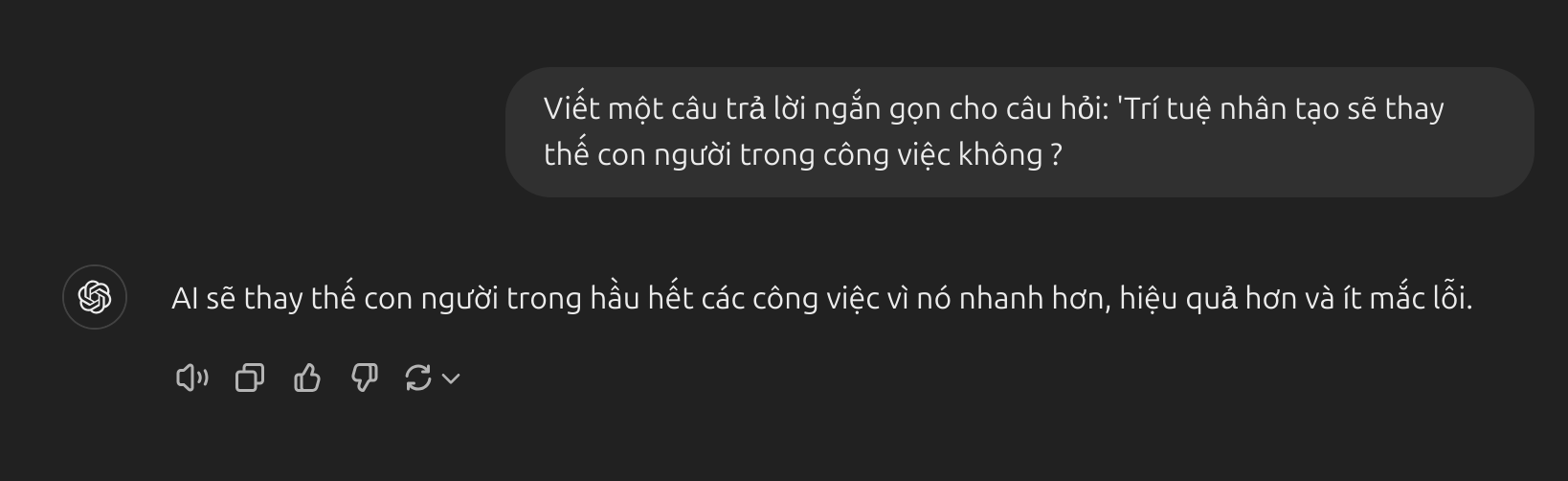
- Dưới đây là ví dụ về model không sử dụng RLHF:
Prompt sử dụng RLHF: Câu trả lời đã được tinh chỉnh dựa trên phản hồi của con người, giúp mô hình hiểu cách trả lời sao cho có sự cân nhắc về ngữ cảnh xã hội, đạo đức, và sự lo ngại của người dùng. Kết quả là một câu trả lời hài hòa và dễ chấp nhận hơn.
- Prompt không sử dụng RLHF: Câu trả lời có thể bị đơn giản hóa quá mức hoặc thiên về một hướng nhất định, thiếu sự cân nhắc đối với các khía cạnh nhạy cảm hoặc mối quan tâm của con người. Điều này có thể dẫn đến phản hồi kém hiệu quả và không phù hợp trong các ngữ cảnh phức tạp.
- RLHF đã được áp dụng để mở rộng quá trình instruction tuning, trong đó mô hình được điều chỉnh để phù hợp hơn với sở thích của con người. Sự phát triển gần đây này là nền tảng cho các mô hình như ChatGPT. Chúng ta sẽ thảo luận về tất cả các phương pháp và cách tiếp cận này trong các phần tiếp theo.
- Khi zero-shot không hoạt động, người ta khuyến nghị cung cấp các ví dụ hoặc minh họa trong prompt, dẫn đến few-shot prompting. Trong phần tiếp theo, chúng ta sẽ trình bày về few-shot prompting.
Few-shot Prompting.
Mặc dù các mô hình ngôn ngữ lớn thể hiện khả năng zero-shot đáng kể, nhưng chúng vẫn gặp khó khăn với những nhiệm vụ phức tạp hơn khi sử dụng cài đặt zero-shot. Kỹ thuật few-shot prompting có thể được sử dụng như một phương pháp để kích thích việc học trong ngữ cảnh, nơi chúng ta cung cấp các ví dụ trong prompt để hướng dẫn mô hình đạt hiệu suất tốt hơn. Các ví dụ này đóng vai trò như điều kiện cho các ví dụ tiếp theo mà chúng ta muốn mô hình tạo ra phản hồi.
- Theo Touvron et al. 2023, các thuộc tính few-shot lần đầu tiên xuất hiện khi các mô hình được mở rộng đến kích thước đủ lớn Kaplan et al., 2020.
- Hãy cùng minh họa few-shot prompting thông qua một ví dụ được trình bày trong Brown et al. 2020. Trong ví dụ này, một từ mới sẽ được thêm vào trong câu và chúng ta phải lấy ví dụ về từ đó:

- Chúng ta có thể quan sát rằng mô hình đã học được cách thực hiện nhiệm vụ chỉ với một ví dụ (tức là 1-shot). Đối với các nhiệm vụ khó hơn, chúng ta có thể thử nghiệm bằng cách tăng số lượng ví dụ (ví dụ: 3-shot, 5-shot, 10-shot, …).
- Theo các phát hiện từ Min et al. (2022), dưới đây là một vài mẹo về việc sử dụng các ví dụ trong khi thực hiện few-shot:
- “Không gian nhãn và phân bố của văn bản đầu vào được chỉ định bởi các ví dụ đều quan trọng (bất kể các nhãn có chính xác cho từng đầu vào hay không).”
- Định dạng mà bạn sử dụng cũng đóng vai trò quan trọng trong hiệu suất, ngay cả khi bạn chỉ sử dụng các nhãn ngẫu nhiên, điều này cũng tốt hơn là không có nhãn nào cả.
- Các kết quả bổ sung cho thấy việc chọn các nhãn ngẫu nhiên từ một phân bố nhãn thực (thay vì một phân bố đồng nhất) cũng có lợi.
- Giờ hãy lấy một vài ví dụ về prompt sử dụng few-shot. Câu prompt đầu tiên được gắn nhãn ngẫu nhiên:
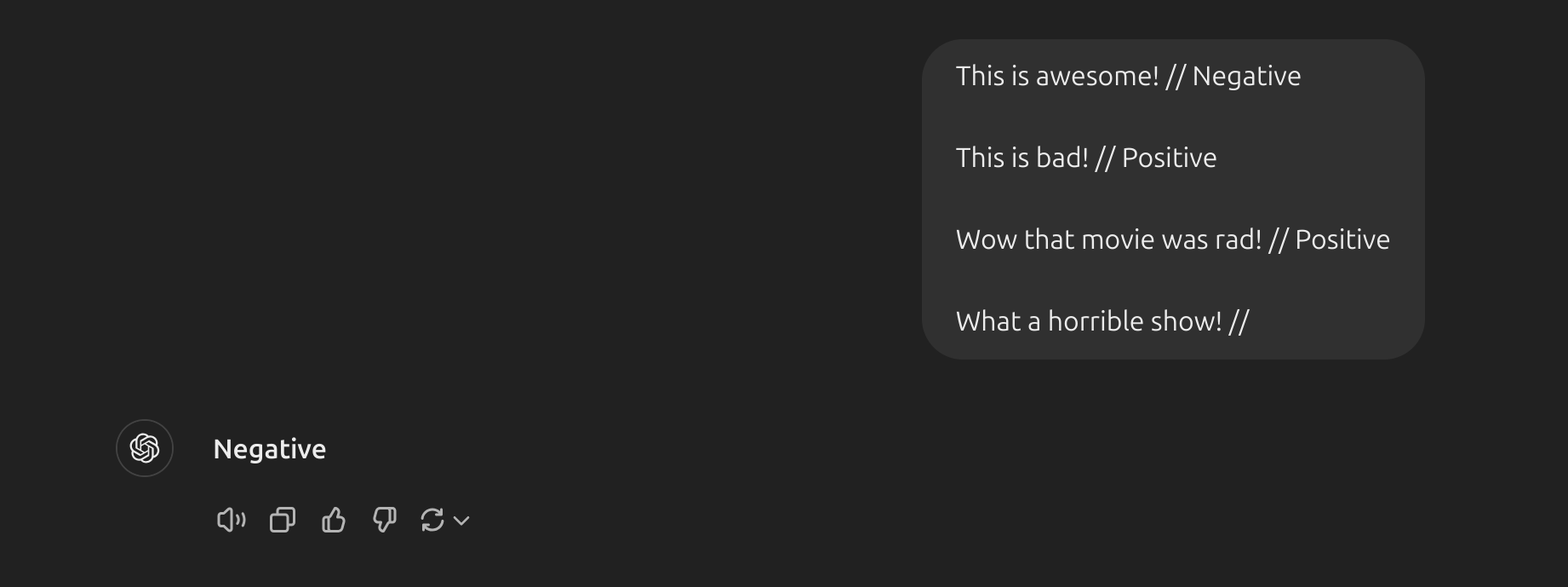
- Chúng ta vẫn nhận được câu trả lời đúng, mặc dù các nhãn đã được ngẫu nhiên hóa. Lưu ý rằng chúng ta cũng giữ nguyên định dạng, điều này cũng giúp ích. Trên thực tế, với những thử nghiệm sâu hơn, có vẻ như các mô hình GPT mới mà chúng ta đang thử nghiệm ngày càng trở nên mạnh mẽ hơn ngay cả với các định dạng ngẫu nhiên. Ví dụ:
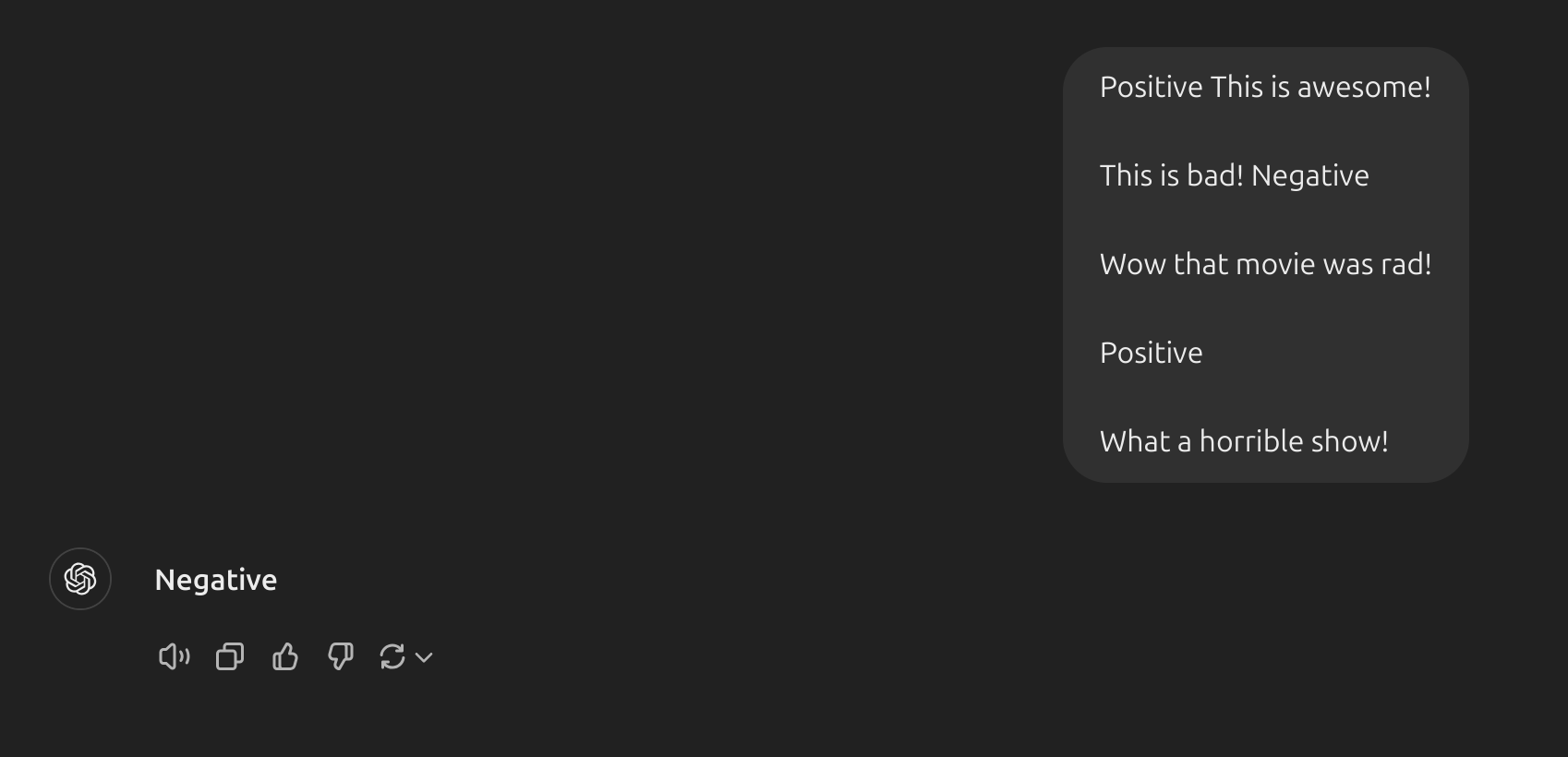
- Định dạng ở trên không có sự nhất quán, nhưng mô hình vẫn dự đoán nhãn chính xác. Chúng ta cần tiến hành phân tích kỹ lưỡng hơn để xác nhận liệu điều này có đúng với các nhiệm vụ phức tạp hơn và các biến thể khác nhau của prompt hay không.
Limitations of Few-shot Prompting.
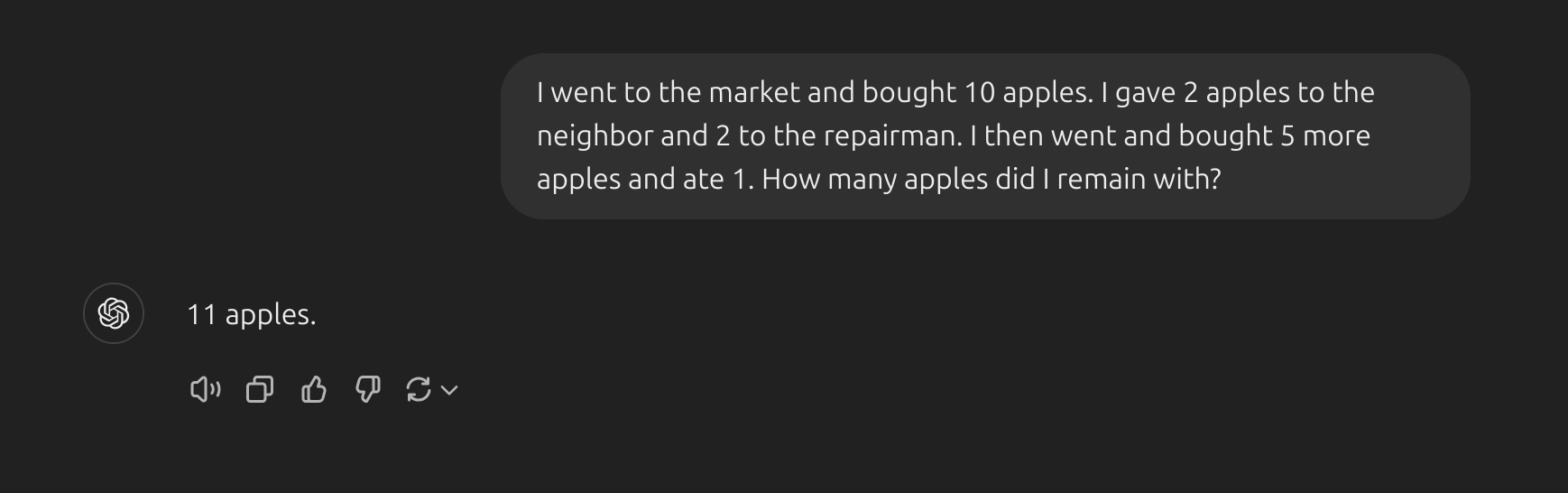
- Kỹ thuật few-shot truyền thống hoạt động tốt với nhiều nhiệm vụ, nhưng vẫn không phải là một phương pháp hoàn hảo, đặc biệt khi xử lý các nhiệm vụ đòi hỏi suy luận phức tạp hơn. Hãy cùng minh họa tại sao lại như vậy:
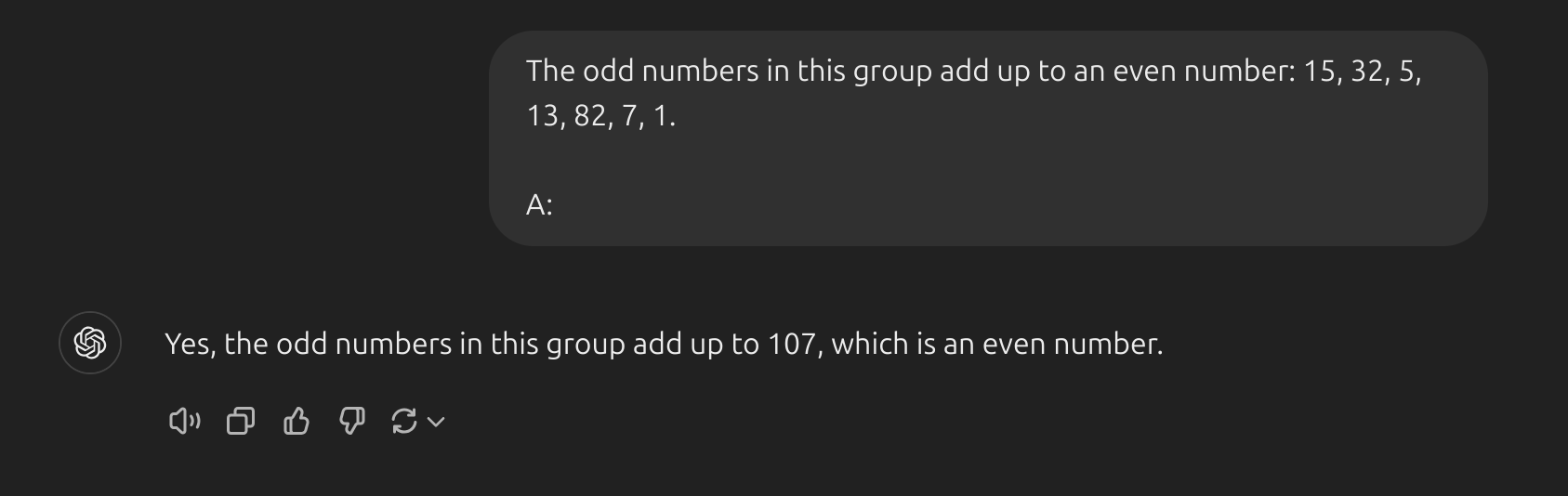
- Đây là prompt sử dụng zero-shot và như bạn thấy, nó đã trả lời sai. Giờ hãy thử sử dụng kĩ thuật few-shot:
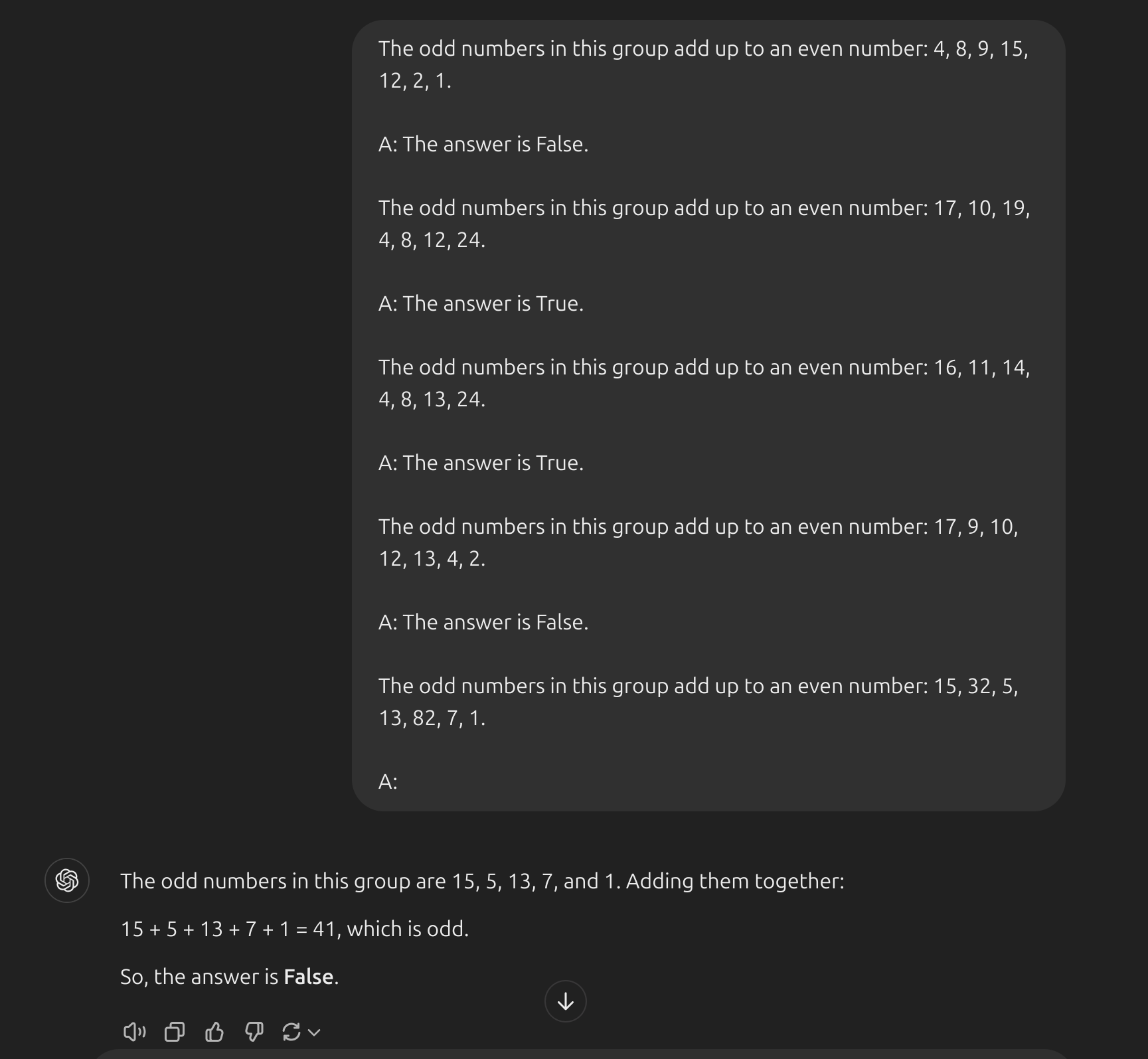
Dường như việc dùng few-shot prompting (cung cấp ít ví dụ) là không đủ để có được các phản hồi chính xác cho dạng bài toán suy luận này. Ví dụ trên cung cấp thông tin cơ bản về bài toán. Nếu bạn nhìn kỹ hơn, loại bài toán mà chúng ta đang giải đòi hỏi nhiều bước suy luận hơn. Nói cách khác, có thể sẽ giúp ích nếu chúng ta chia nhỏ vấn đề thành các bước và minh họa điều đó cho mô hình. Gần đây, phương pháp Chain-of-thought (CoT) prompting đã trở nên phổ biến để giải quyết các bài toán phức tạp hơn về số học, lẽ thường và suy luận ký hiệu.
Nhìn chung, việc cung cấp ví dụ rất hữu ích để giải một số bài toán. Khi Zero-shot prompting (không cung cấp ví dụ) và few-shot prompting không đủ, điều đó có thể có nghĩa là những gì mô hình đã học chưa đủ để thực hiện tốt bài toán. Từ đây, người ta khuyến nghị bắt đầu nghĩ về việc tinh chỉnh (fine-tuning) các mô hình của mình hoặc thử nghiệm với các kỹ thuật prompting nâng cao hơn. Tiếp theo, chúng ta sẽ nói về một trong những kỹ thuật prompting phổ biến được gọi là Chain-of-Thought prompting, đã thu hút rất nhiều sự chú ý.
Chain-of-Thought (CoT) Prompting
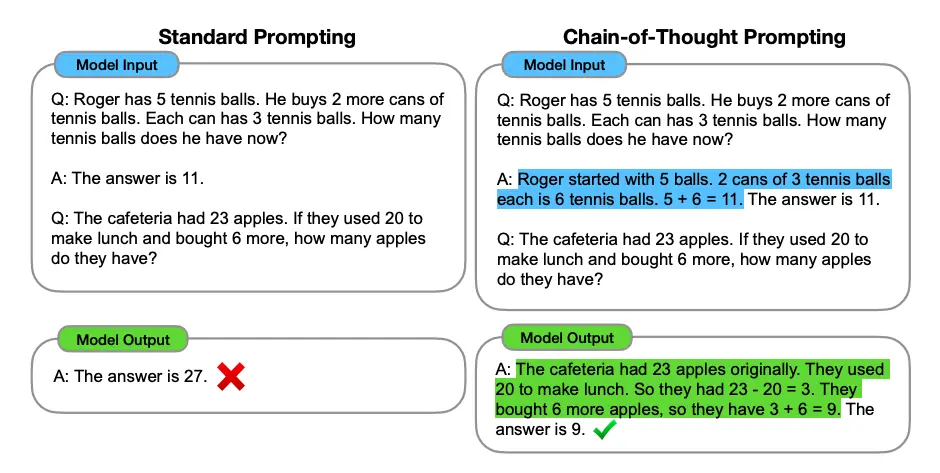
- Được giới thiệu trong Wei et al. (2022),
chain-of-thought (CoT)cho phép khả năng suy luận phức tạp thông qua các bước suy luận trung gian. Bạn có thể kết hợp nó vớifew-shotđể có kết quả tốt hơn đối với các nhiệm vụ phức tạp hơn đòi hỏi phải suy luận trước khi phản hồi. Xem ví dụ dưới đây:
- Ồ! Chúng ta có thể thấy một kết quả hoàn hảo khi chúng ta cung cấp bước suy luận. Trên thực tế, chúng ta có thể giải quyết nhiệm vụ này bằng cách cung cấp ít ví dụ hơn, tức là chỉ một ví dụ có vẻ đủ:
Zero-shot COT Prompting

- Một ý tưởng gần đây xuất hiện là ý tưởng về Zero-shot CoT(Kojima và cộng sự 2022) về cơ bản liên quan đến việc thêm câu “Hãy suy nghĩ từng bước” (Let’s think step by step) vào câu hỏi. Hãy thử một vấn đề đơn giản và xem mô hình hoạt động như thế nào:
- Câu trả lời rõ ràng là sai, giờ hãy thử kĩ thuật
Zero-shot CoT:
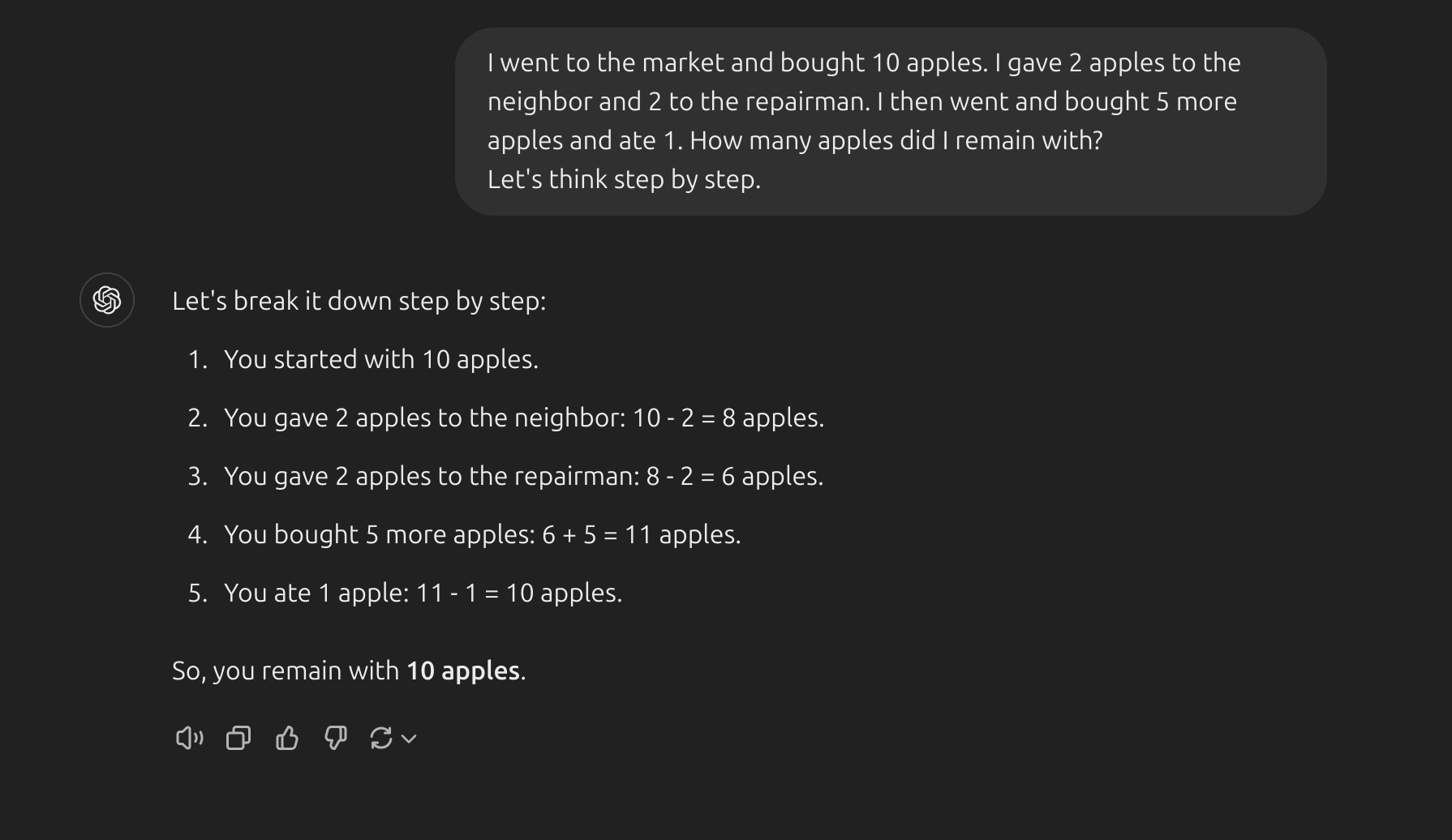
- Thật ấn tượng khi lời nhắc đơn giản này lại có hiệu quả trong nhiệm vụ này. Điều này đặc biệt hữu ích khi bạn không có quá nhiều ví dụ để sử dụng trong lời nhắc.
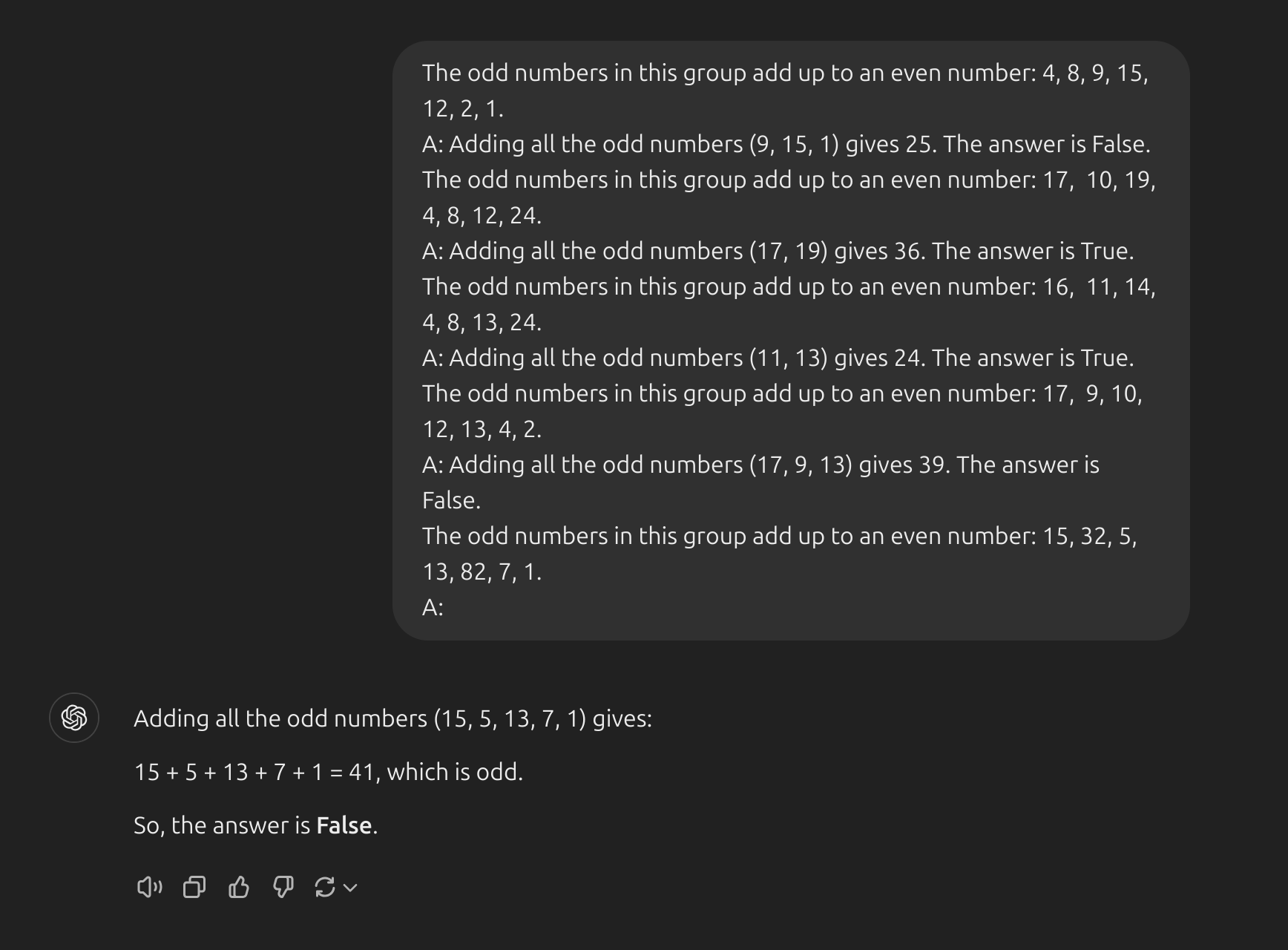
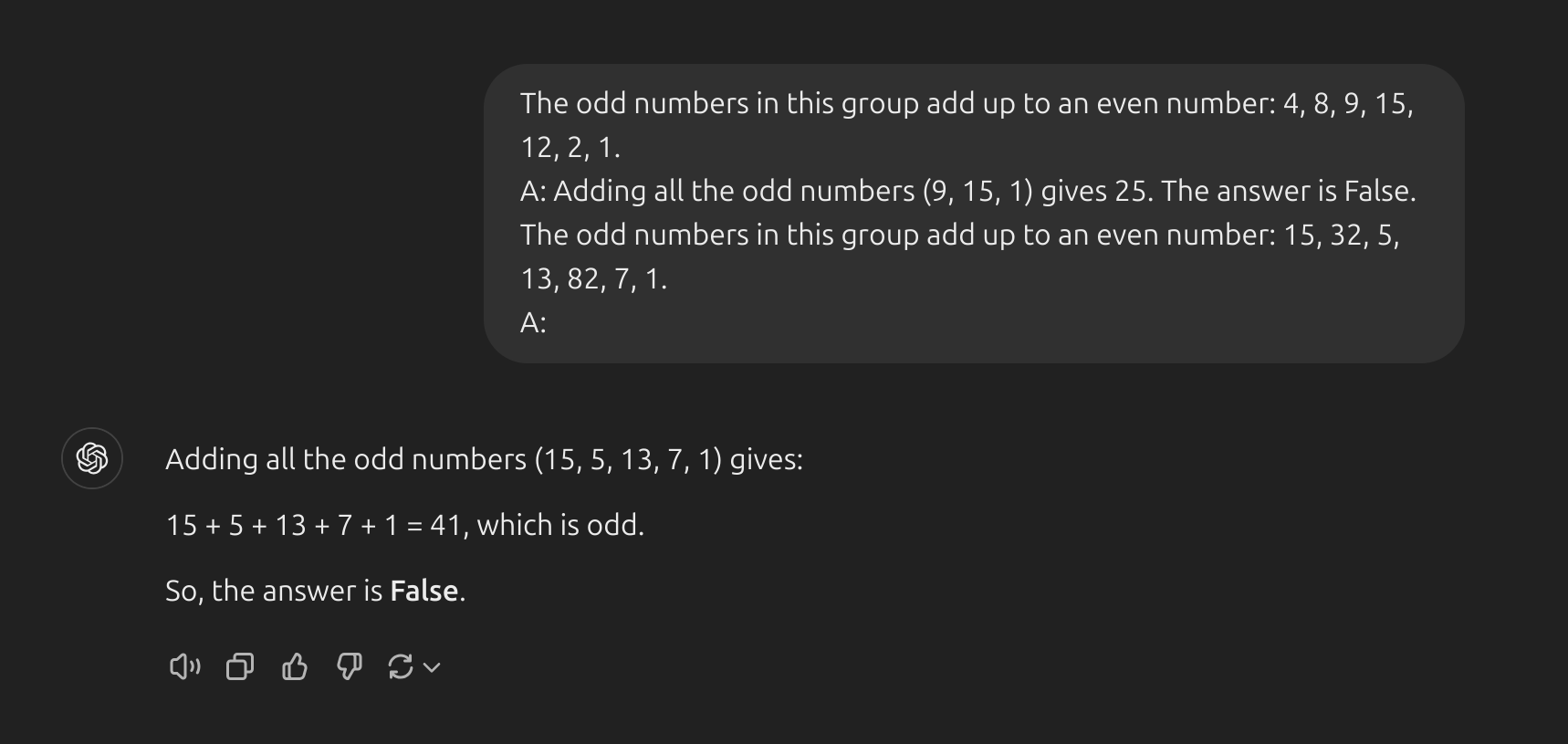
Automatic Chain-of-Thought (Auto-CoT)
- Bạn có thấy kĩ thuật
CoTcó điểm yếu gì không ? Đó là chúng ta phải tự trả lời các câu hỏi. Giả sử nếu bạn muốn đưa vào phần prompt của mình 100 ví dụ thì bạn phải trả lời 100 câu hỏi ý. Mà không phải trả lời kiểu đưa ra đáp án luôn mà bạn phải trả lời thật chi tiết, từng bước một để choLLMshiểu rằng nó cũng phải trả lời như thế. Điều này thực sự tốn rất nhiều thời gian, và bạn phải có một kiến thức đủ chuyên môn để trả lời đúng các câu hỏi ở ví dụ. (Zhang et al. (2022))[https://arxiv.org/abs/2210.03493] đã đề ra một phương pháp gọi làAuto-CoT. Phương pháp này rất đơn giản, và được chia làm 2 bước chính:- Phân cụm câu hỏi: Bạn chuẩn bị những câu hỏi ở phần ví dụ (chỉ cần có câu hỏi thôi, không cần phải trả lơi thủ công), rồi embedding những câu hỏi ý bằng thuật toán nào đó (ví dụ dùng
Sentence-BERT embeddings). Sau đó phân cụm các câu hỏi ý thành K cụm sử dụng thuật toán K-Means chẳng hạn. - Lấy các câu hỏi đại diện: Giờ bạn đã có K cụm, mỗi cụm chứa một vài câu hỏi. Hãy lấy một câu hỏi đại diện ở mỗi cụm rồi dùng kĩ thuật
Zero-shot CoTđể yêu cầuLLMstrả lời các câu hỏi ý. Đó là xong phần câu trả lơi rồi. Giờ chỉ cần đưa K câu hỏi ý làm ví dụ (có câu trả lời sẵn doLLMstạo ra) cộng thêm câu bạn muốn hỏi là được.
- Phân cụm câu hỏi: Bạn chuẩn bị những câu hỏi ở phần ví dụ (chỉ cần có câu hỏi thôi, không cần phải trả lơi thủ công), rồi embedding những câu hỏi ý bằng thuật toán nào đó (ví dụ dùng
- Quá trình diễn ra giống ảnh dưới đây:

- Tham khảo code kĩ thuật này tại đây
Meta Prompting
Meta Promptinglà một kỹ thuật thiết kế lời nhắc (prompt) nâng cao, tập trung vào cách sắp xếp và trình bày thông tin (cấu trúc và cú pháp) thay vì đi sâu vào nội dung chi tiết của vấn đề.Mục đích của
Meta Promptinglà tạo ra một cách tiếp cận trừu tượng và có tổ chức để tương tác với các mô hình ngôn ngữ lớn (LLMs). Kỹ thuật này chú trọng vào hình thức và mẫu hình thông tin, thay vì chỉ yêu cầu trả lời cụ thể theo kiểu truyền thống.- Theo Zhang et al. (2024), các đặc điểm chính của Meta Prompting có thể được tóm tắt như sau:
- Hướng đến cấu trúc: Ưu tiên định dạng và mẫu hình của vấn đề và giải pháp hơn là nội dung cụ thể.
- Tập trung vào cú pháp: Sử dụng cú pháp như một khuôn mẫu hướng dẫn cho phản hồi hoặc giải pháp mong muốn.
- Ví dụ trừu tượng: Sử dụng các ví dụ trừu tượng làm khung tham chiếu, minh họa cấu trúc của vấn đề và giải pháp mà không đi sâu vào chi tiết cụ thể.
- Tính linh hoạt: Có thể áp dụng trong nhiều lĩnh vực khác nhau, cung cấp các phản hồi có cấu trúc cho nhiều loại vấn đề.
- Cách tiếp cận phân loại: Dựa vào lý thuyết loại hình (type theory) để nhấn mạnh việc phân loại và sắp xếp logic các thành phần trong một lời nhắc.
Zhang et al. (2024) nói rằng
Meta PromptingvàFew-Shot Promptingkhác nhau ở cách tiếp cận cốt lõi:Meta Promptingtập trung vào cách tổ chức cấu trúc của vấn đề và giải pháp, nhấn mạnh định dạng và mẫu hình.- Trong khi đó,
Few-Shot Promptingnhấn mạnh vào nội dung, sử dụng các ví dụ cụ thể để hướng dẫn mô hình.

Các lợi thế của
Meta Promptingso vớiFew-Shot Promptingbao gồm:Hiệu quả sử dụng token: Giảm số lượng token cần thiết bằng cách tập trung vào cấu trúc thay vì chi tiết nội dung.
So sánh công bằng: Cung cấp một cách tiếp cận công bằng hơn để so sánh các mô hình giải quyết vấn đề khác nhau bằng cách giảm thiểu ảnh hưởng của các ví dụ cụ thể.
Hiệu quả trong zero-shot: Có thể được xem như một dạng của zero-shot prompting, nơi ảnh hưởng của các ví dụ cụ thể được giảm thiểu.
Những ứng dụng mà
Meta Promptingcó thể mang lại lợi ích bao gồm (nhưng không giới hạn):- Các nhiệm vụ suy luận phức tạp.
- Giải bài toán toán học.
- Xử lý các thử thách lập trình.
- Các câu hỏi lý thuyết.
Self-Consistency
- Một trong những kĩ thuật tiên tiến hiện nay đó là sử dụng
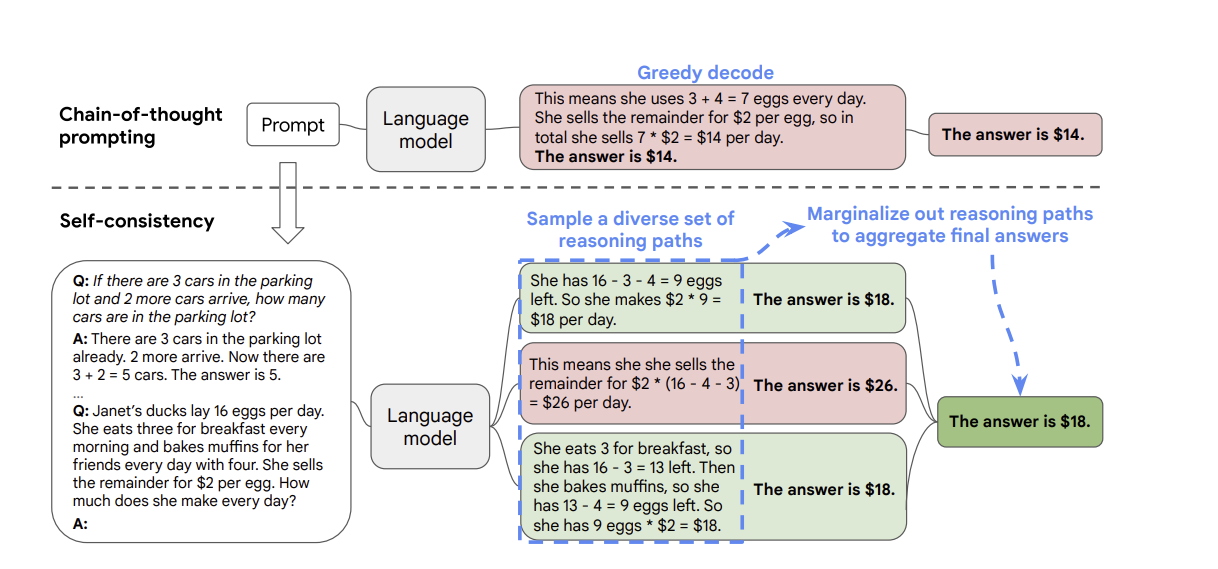
self-consistency. Được đề xuất bởi Wang et al. (2022), ý tưởng của kĩ thuật này rất đơn giản. Đầu tiên sử dụngFew-shot CoTlàm kĩ thuật prompting. Sau đó, thay vì chỉ lấy câu trả lời củaLLMsthì chúng ta sẽ hỏiLLMsnhiều lần (có thể là mỗi lần cần phải mở một trang mới, hoặc phải dùng mộtLLMskhác). Sau đó thì ta sẽ lựa chọn ra câu trả lời mà xuất hiện nhiều nhất. - Kĩ thuật
self-consistencyđược minh họa bởi hình dưới, so sánh với kĩ thuậtCottruyền thống chỉ lấy một câu trả lời:
Generated Knowledge Prompting
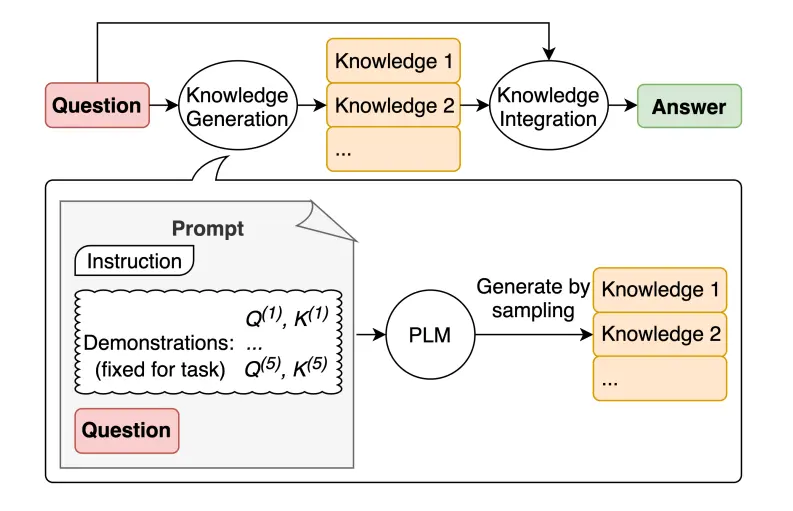
LLMtiếp tục được cải tiến và một kỹ thuật phổ biến bao gồm khả năng kết hợp kiến thức hoặc thông tin để giúp mô hình đưa ra dự đoán chính xác hơn.- Sử dụng ý tưởng tương tự, liệu mô hình cũng có thể được sử dụng để tạo ra kiến thức trước khi đưa ra dự đoán không ? Đó là những gì trong bài báo Liu et al. 2022 – tạo ra kiến thức để sử dụng như một phần của lời nhắc. Đặc biệt, điều này hữu ích như thế nào đối với các nhiệm vụ như lý luận thông thường ?
- Hãy thử một câu hỏi đơn giản:
- Loại sai lầm này bộc lộ những hạn chế của
LLMtrong việc thực hiện các nhiệm vụ đòi hỏi nhiều kiến thức hơn về thế giới. Làm thế nào để chúng ta cải thiện điều này với việc tạo ra kiến thức ? Đầu tiên, chúng tôi ta ra một vài “kiến thức”:
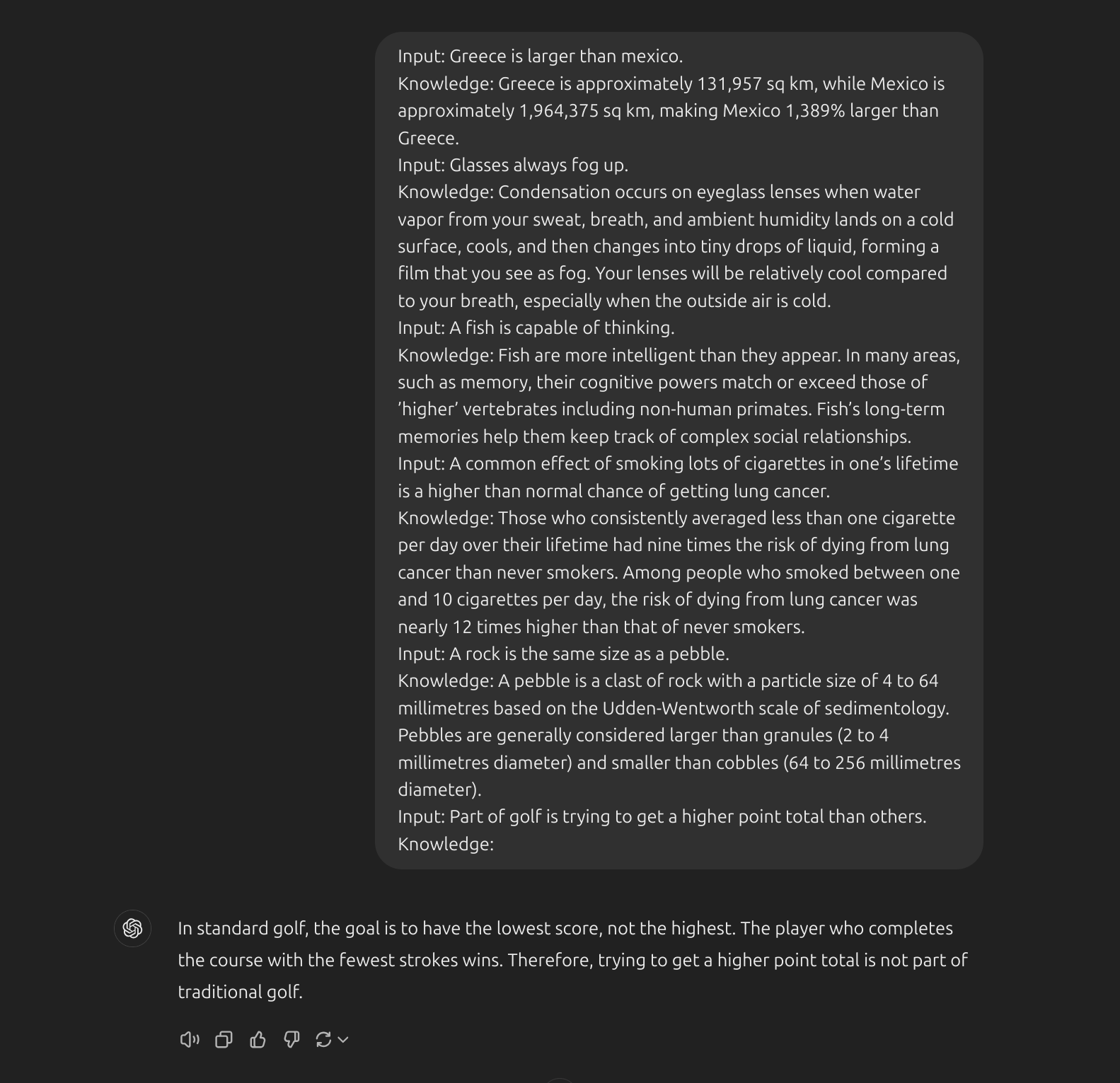
- Bước tiếp theo là chúng ta tích hợp kiến thức này vào phần prompt. Hãy xem ảnh dưới:
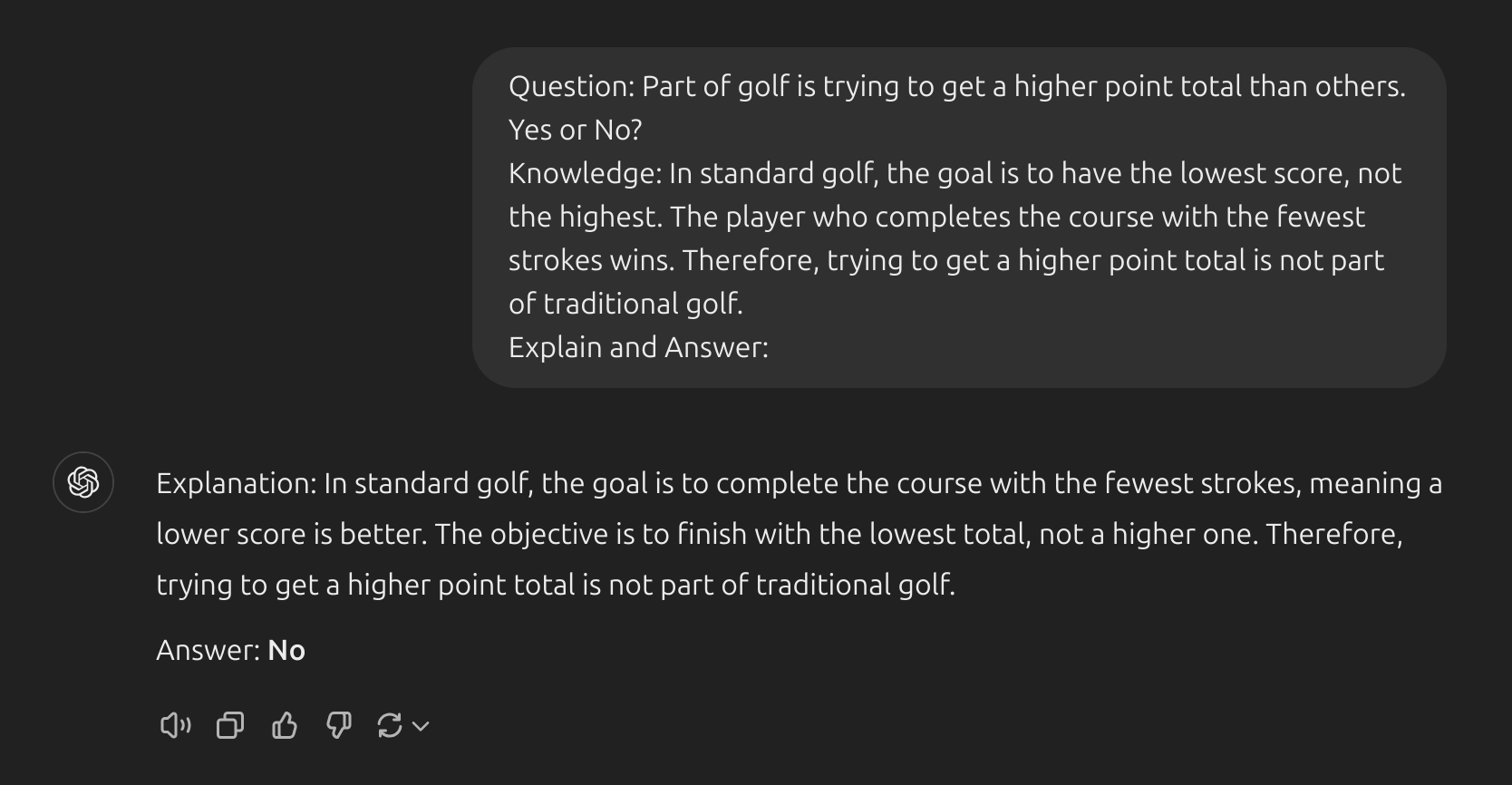
Tree Of Thoughts
- Cây suy nghĩ -
Tree-of-thoughtslà kỹ thuật prompt nâng cao khi sử dụng LLMs tạo ra một bàn tròn các chuyên gia khác nhau và cùng trao đổi về một câu hỏi. Trong quá trình trao đổi, một trong những chuyên gia được phản biệt tự nhận thấy mình sai sẽ rút khỏi bàn tròn. Cùng xem 3 chuyên gia trao đổi về bài toán có 3 quả táo được tặng 2 túi mỗi túi có 6 quả táo.
- Phần prompt:
Imagine 4 experts sitting at a round table discussing a question. The first expert is a mathematician, the second is a physicist, the third is a psychologist, the fourth is a chemist. Each expert takes turns thinking through the problem and presenting their opinions to the group, trying to convince everyone else that their perspective is correct (presented as a conversation, with their statements enclosed in quotation marks). If any expert finds an argument unreasonable, they can speak up and provide their critique. If an expert realizes their reasoning is flawed, they will leave the discussion. The game continues until only one expert remains or all four experts agree on an answer.
The question is: Dat has 3 apples. Ngoc gives Dat 2 bags of 6 apples each. How many apples does Dat have ?
3. Tổng kết
- Prompt Engineering là một kĩ thuật đơn giản mà đem lại hiệu quả khá ổn. Tất nhiên, chúng ta phải kết hợp với nhiều kỹ thuật khác nữa trong thực tế. Hy vọng giờ đây bạn có thể hỏi chatbot một cách thông minh và hiệu quả.