Retrieval Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) là một kỹ thuật tiên tiến trong lĩnh vực trí tuệ nhân tạo, kết hợp giữa khả năng truy xuất thông tin và mô hình sinh ngôn ngữ. Thay vì chỉ dựa vào dữ liệu đã được học từ trước, RAG có khả năng tìm kiếm và truy xuất thông tin từ các nguồn bên ngoài, sau đó sử dụng dữ liệu này để tạo ra câu trả lời hoặc văn bản một cách chính xác và phong phú hơn. Phương pháp này giúp cải thiện hiệu suất của các hệ thống AI trong việc xử lý các câu hỏi phức tạp và cung cấp các phản hồi cập nhật, dựa trên dữ liệu mới nhất.
1. Giới thiệu.
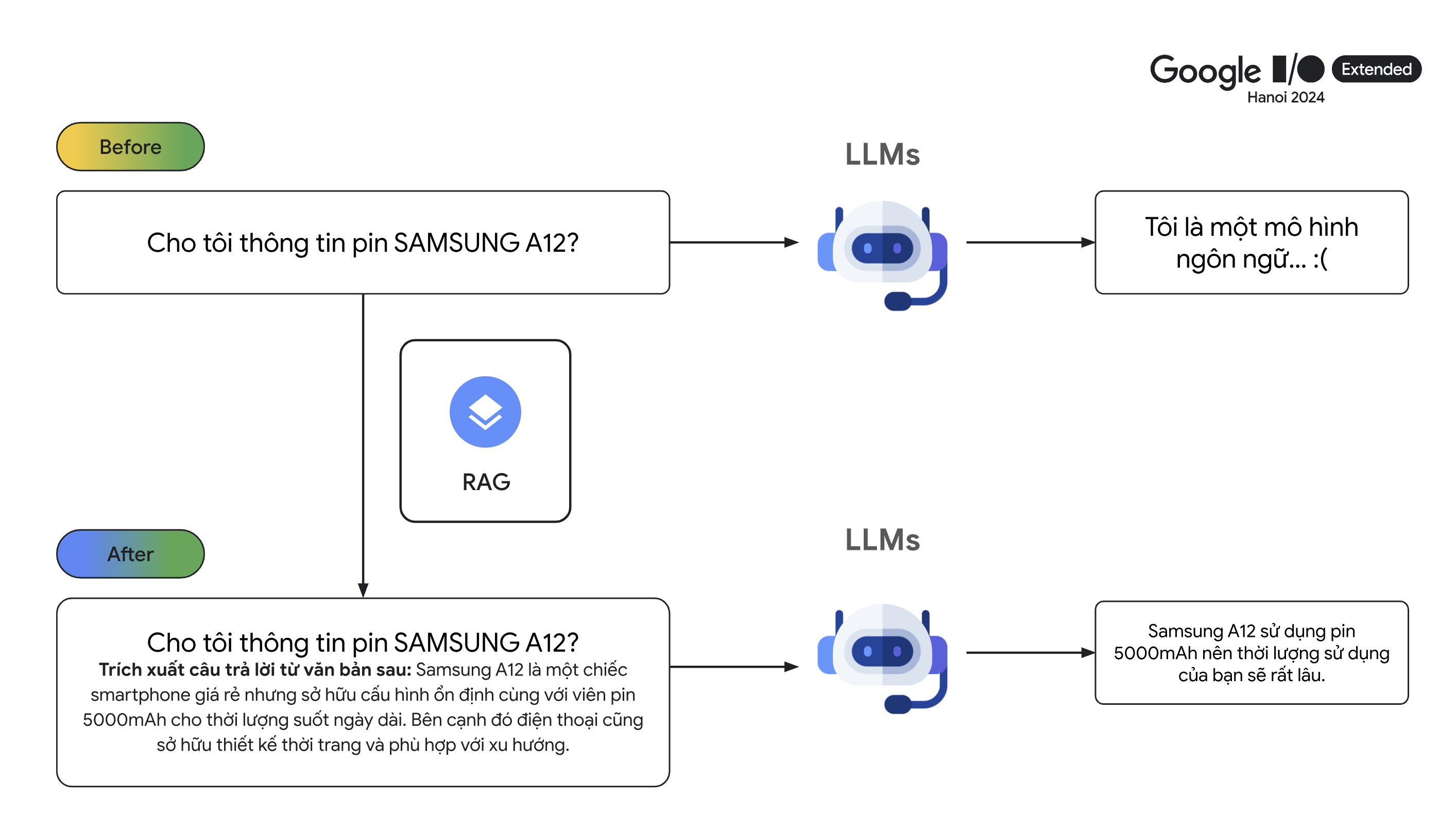
- Ảnh dưới đây là một luồng hoạt động cơ bản khi chúng ta sử dụng các mô hình ngôn ngữ lớn như ChatGPT, Gemini:

- Ta thấy ảnh trên người dùng đã hỏi câu sau:
Cho tôi thông tin SAMSUNG A12
- Nếu như người dùng sử dụng những mô hình chatGPT phiên bản cũ như 3.5 trở xuống thì mô hình sẽ không biết được thông tin cụ thể như thông tin SAMSUNG A12 nên mô hình sẽ đưa ra những câu trả lời đại loại như:
Xin lỗi, tôi không biết.
Tôi chỉ là mô hình ngôn ngữ. Tôi không có thông tin về câu hỏi của bạn.
- Một các giải quyết vấn đề này là chúng ta sẽ thêm các thông tin quan trọng luôn trong câu hỏi của mình. Ví dự như, chúng ta sẽ hỏi câu sau đây:
SAMSUNG A12 có giá 10 triệu đồng, thiết kế tinh xảo đẹp mắt …
Hãy cho tôi thông tin SAMSUNG A12.
- Khi mô hình ngôn ngữ lớn đã biết ngữ cảnh mà chúng ta cung cấp nên có thể trả lời rằng:
Thông tin của SAMSUNG A12: có giá 10 triệu đồng, được thiết kế tinh xảo đẹp mắt …
- Các bạn sẽ đặt câu hỏi là nếu như người dùng đã biết trước câu thông tin để đưa ngữ cảnh vào câu hỏi thì chằng phải người dùng đã biết câu trả lời rồi sao ? Nếu bạn đặt câu hỏi như thế thì bạn đã hiểu sai về RAG. Người dùng chỉ nhập câu hỏi đơn giản thôi, thứ chúng ta cần làm là đưa thêm các thông tin liên quan đến câu hỏi đó vào prompt để nâng cao chất lượng câu trả lời của mô hình. Cụ thể hơn, hãy tưởng tượng bạn là chủ shop bán điện thoại, bạn đã có hết tất cả thông tin của từng chiếc điện thoại trong database và bạn muốn xây dựng một con chatbot có thể trả lời các câu hỏi của khách hàng. Khi khách hàng đặt câu hỏi thì hệ thống RAG sẽ tìm trong database các đoạn văn bản liên quan đến câu hỏi của khách hàng nhất để đưa vào trong prompt nhằm cung cấp thêm ngữ cảnh của câu hỏi.
2. Flow cơ bản của RAG.
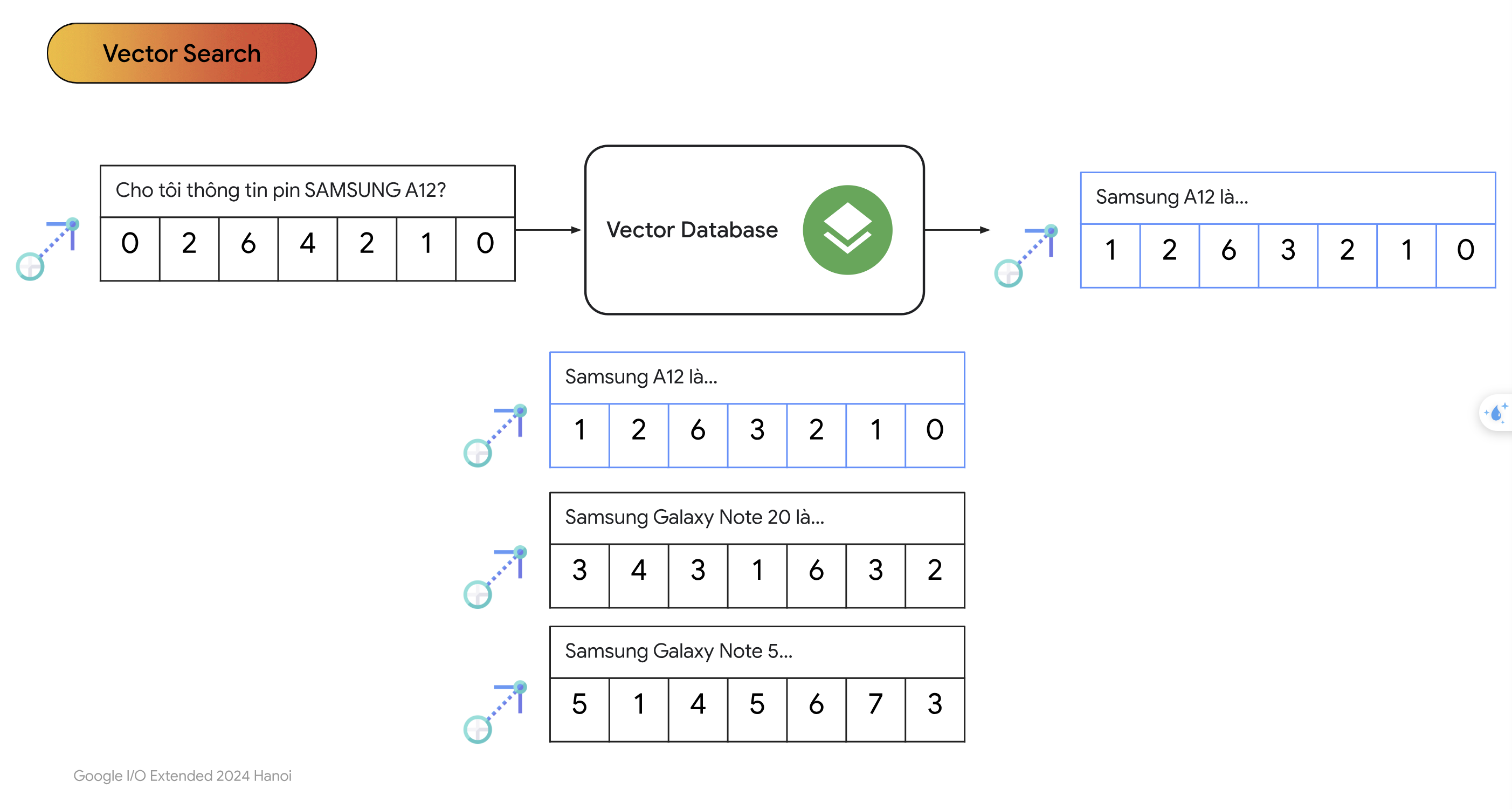
- Ý tưởng chính là chuyển đổi câu hỏi của người dùng và các văn bản trong database thành dạng vector rồi tính độ tương đồng của vector câu hỏi với từng vector trong database rồi chọn ra $K$ vector có điểm cao nhất. Cụ thể từng bước một, đầu tiên ta sẽ chuyển đổi các văn bản trong database thành vector thông qua các mô hình như Bert, Transfomer,… gọi chung là các mô hình Embeddings.
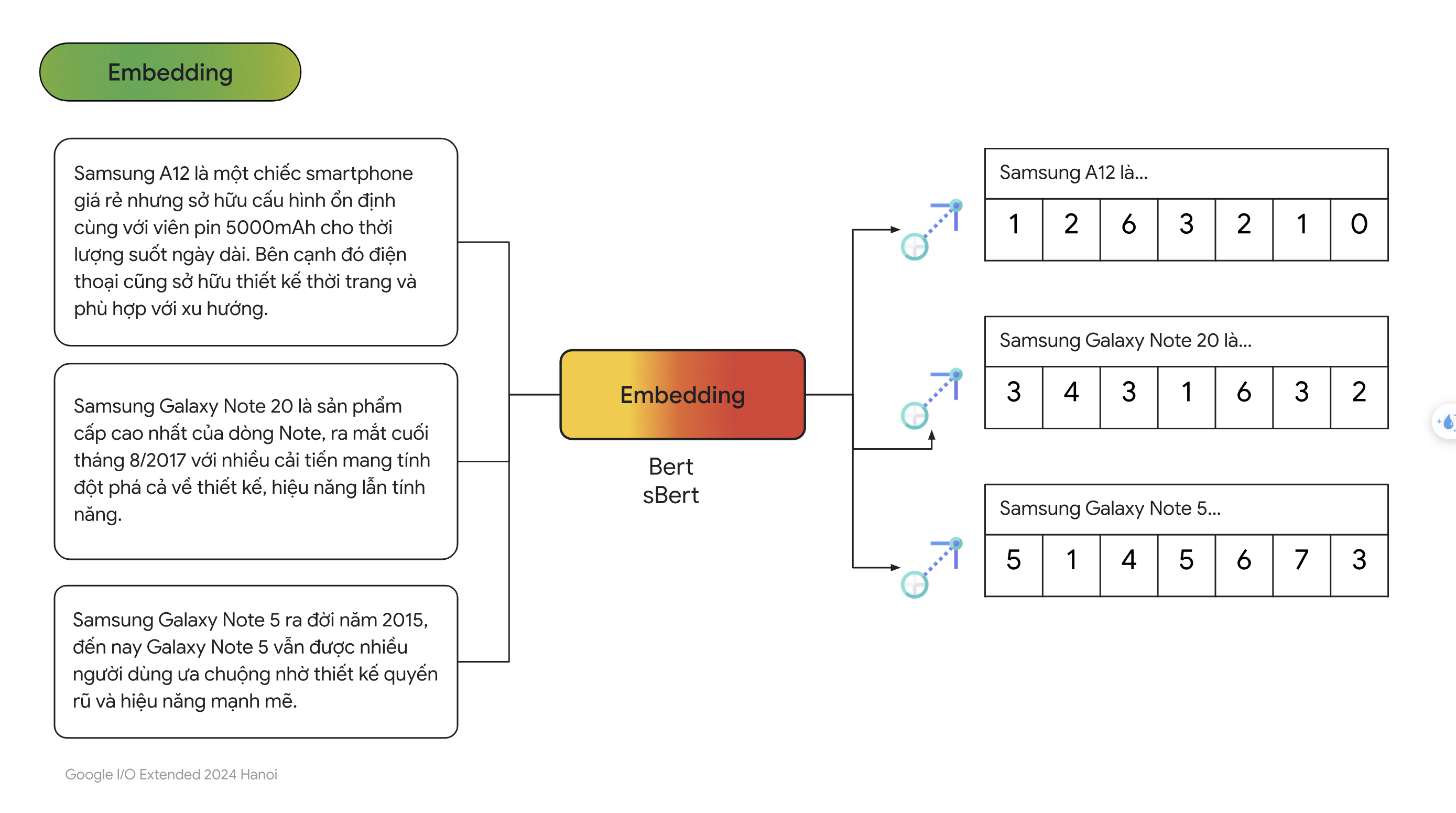
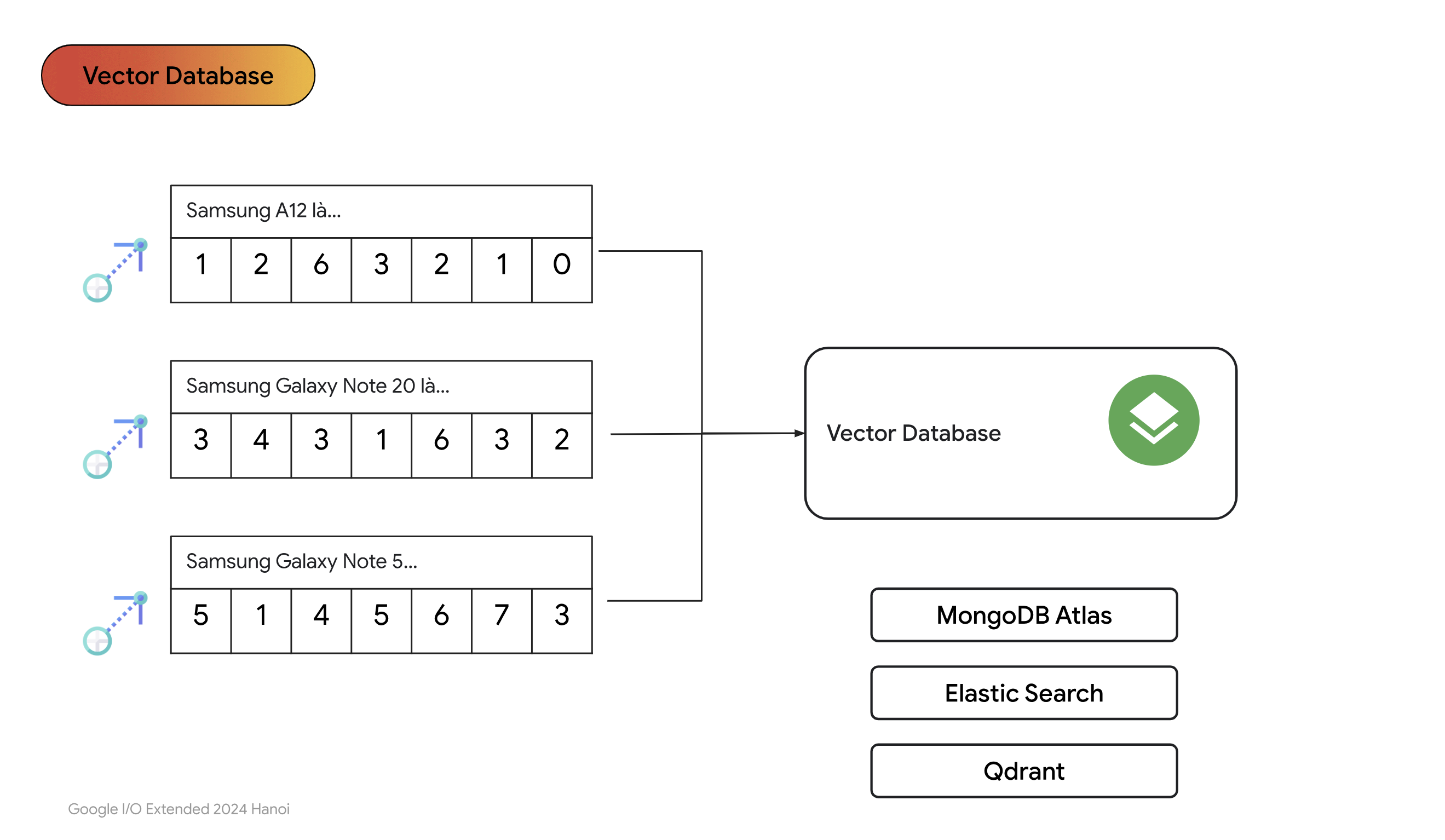
- Tiếp theo chúng ta sẽ lưu các vector này vào database. Vì database này chỉ chứa vector nên người ta thường gọi là vectordatabase.
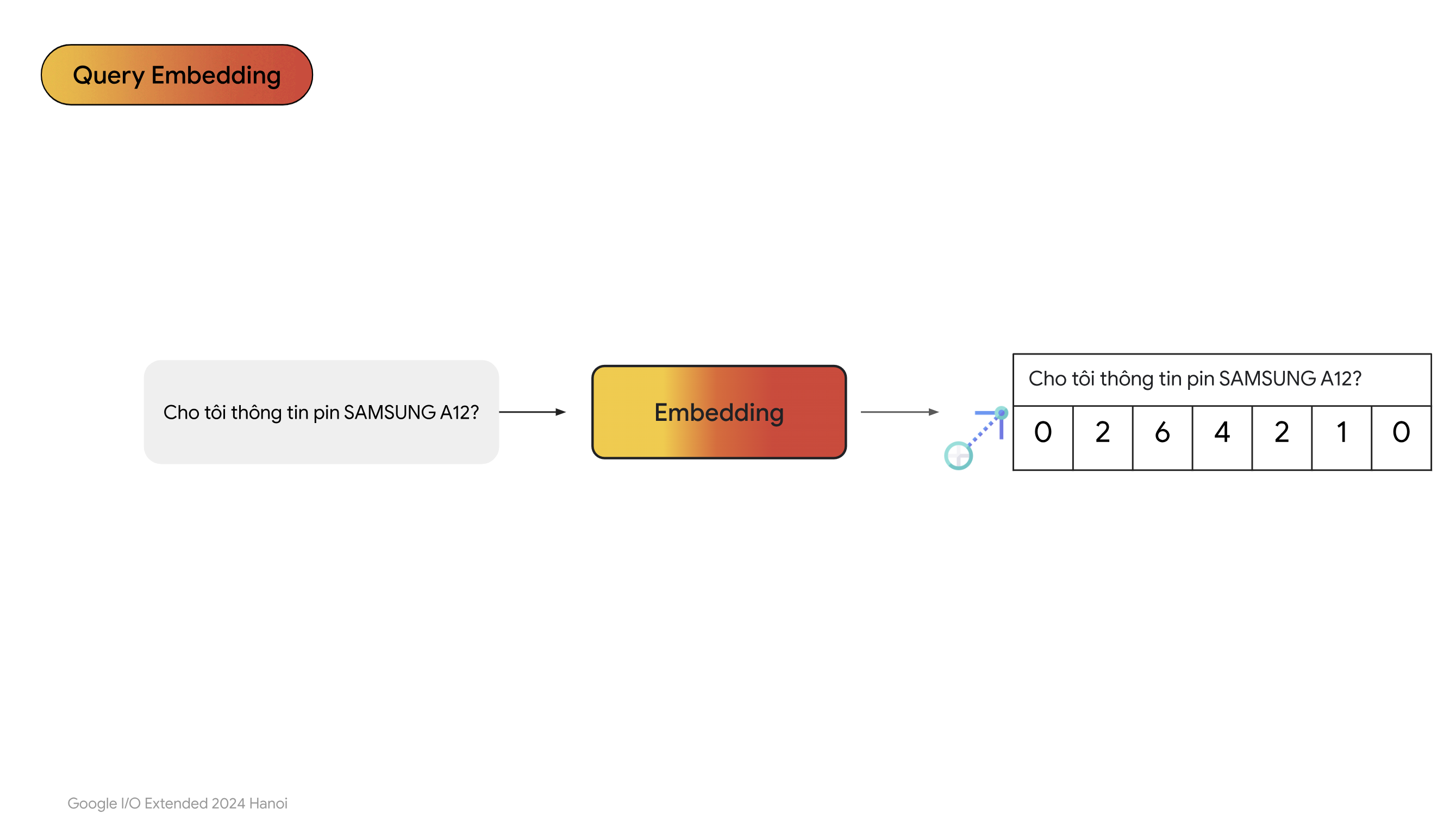
- Chúng ta chuyển câu hỏi sang dạng vector cũng sử dụng chung mô hình đã chuyển văn bản trong database thành vector.
- Tiếp theo chúng ta thực hiện bước vector search để tìm ra $K$ vector có độ tương đồng nhất với vector câu hỏi.
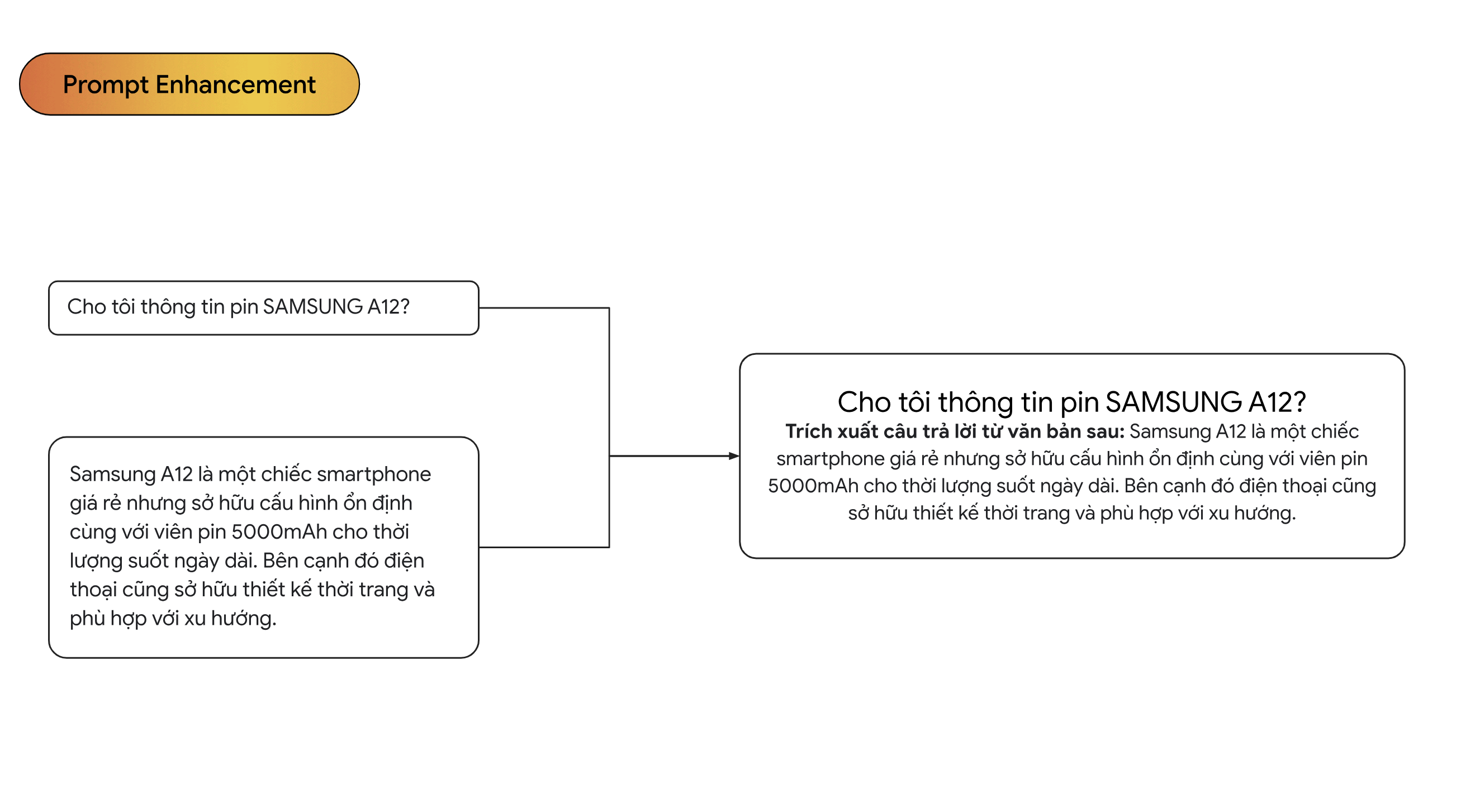
- Đây là phần prompt của chúng ta sau khi đã được cải thiện bởi RAG
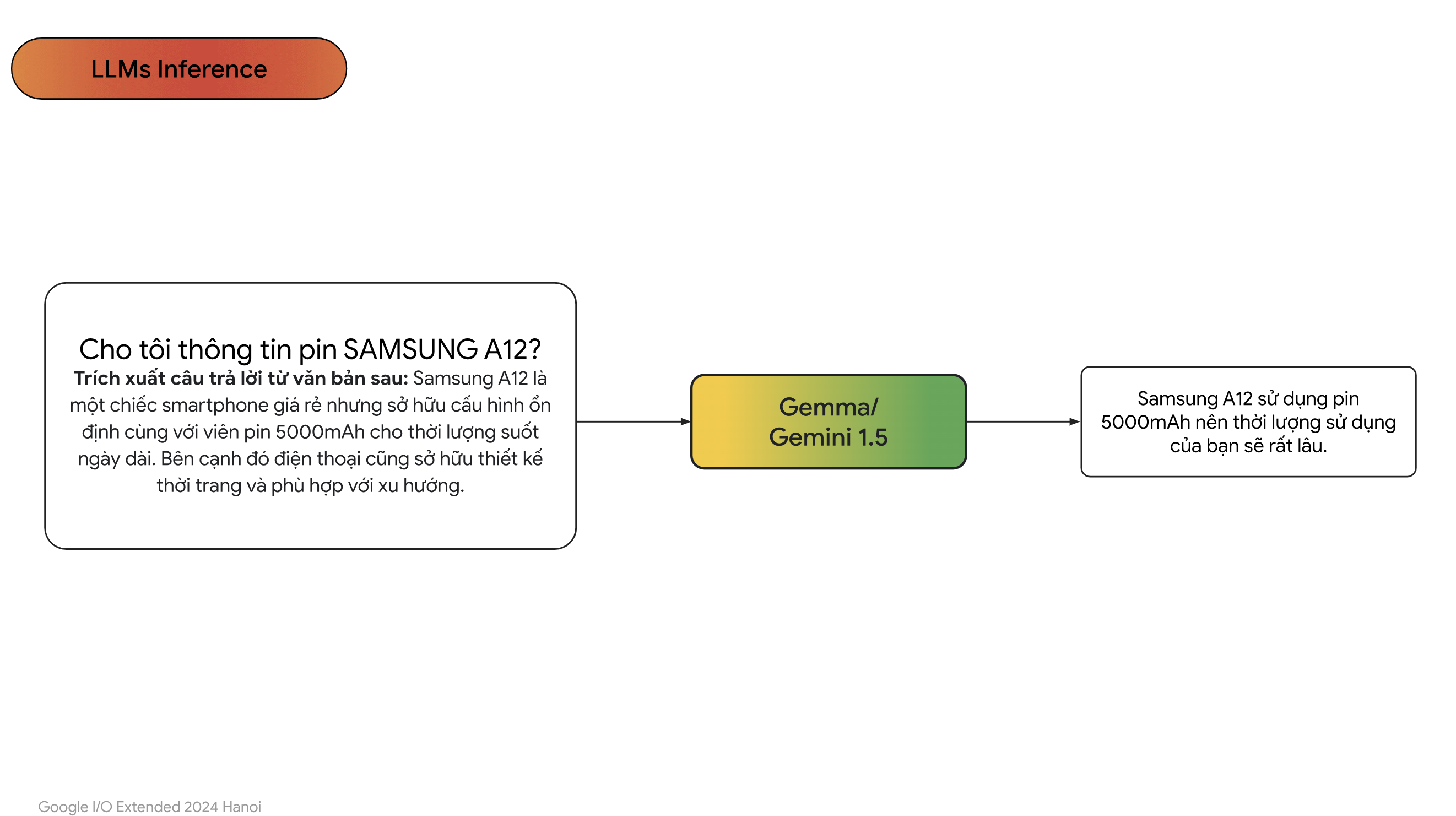
- Sau đó chúng ta sẽ đưa qua các mô hình ngôn ngữ lớn của OpenAI, Google,…
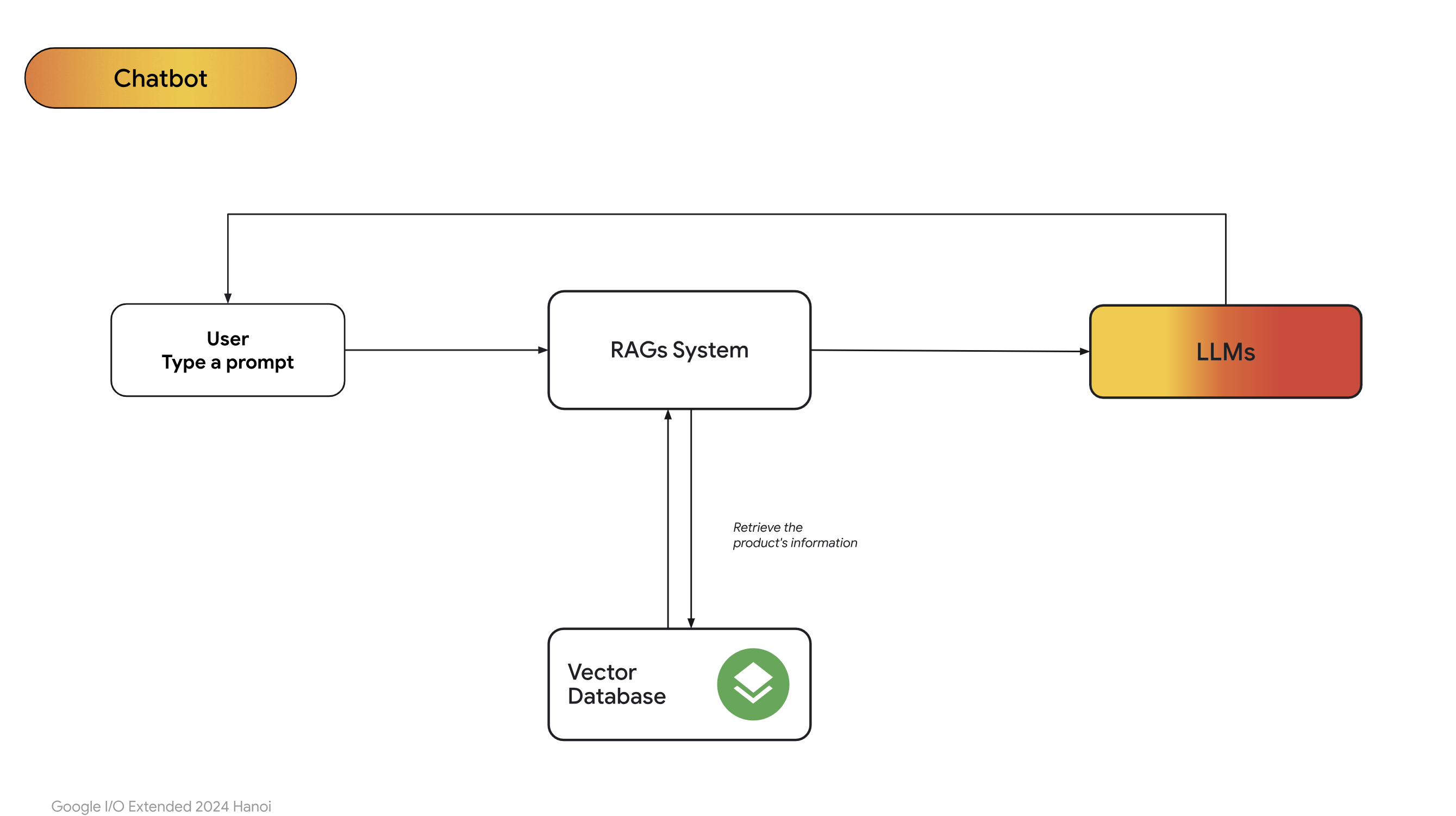
- Dưới đây là một quy trình pipeline cơ bản dùng RAG. Đầu tiên người dùng sẽ nhập câu hỏi, sau đó thì hệ thống RAG sẽ tìm kiếm các văn bản liên quan đến câu hỏi thông qua vector database. Sau khi tìm ra được các đoạn văn bản liên quan thì RAG sẽ cho vào prompt của người dùng và gửi tới LLMs. LLMs sẽ trả lời câu hỏi dựa vào ngữ cảnh đã được thêm vào. Quá trình này lặp đi lặp lại như hình dưới:
3. RAGs Problem.
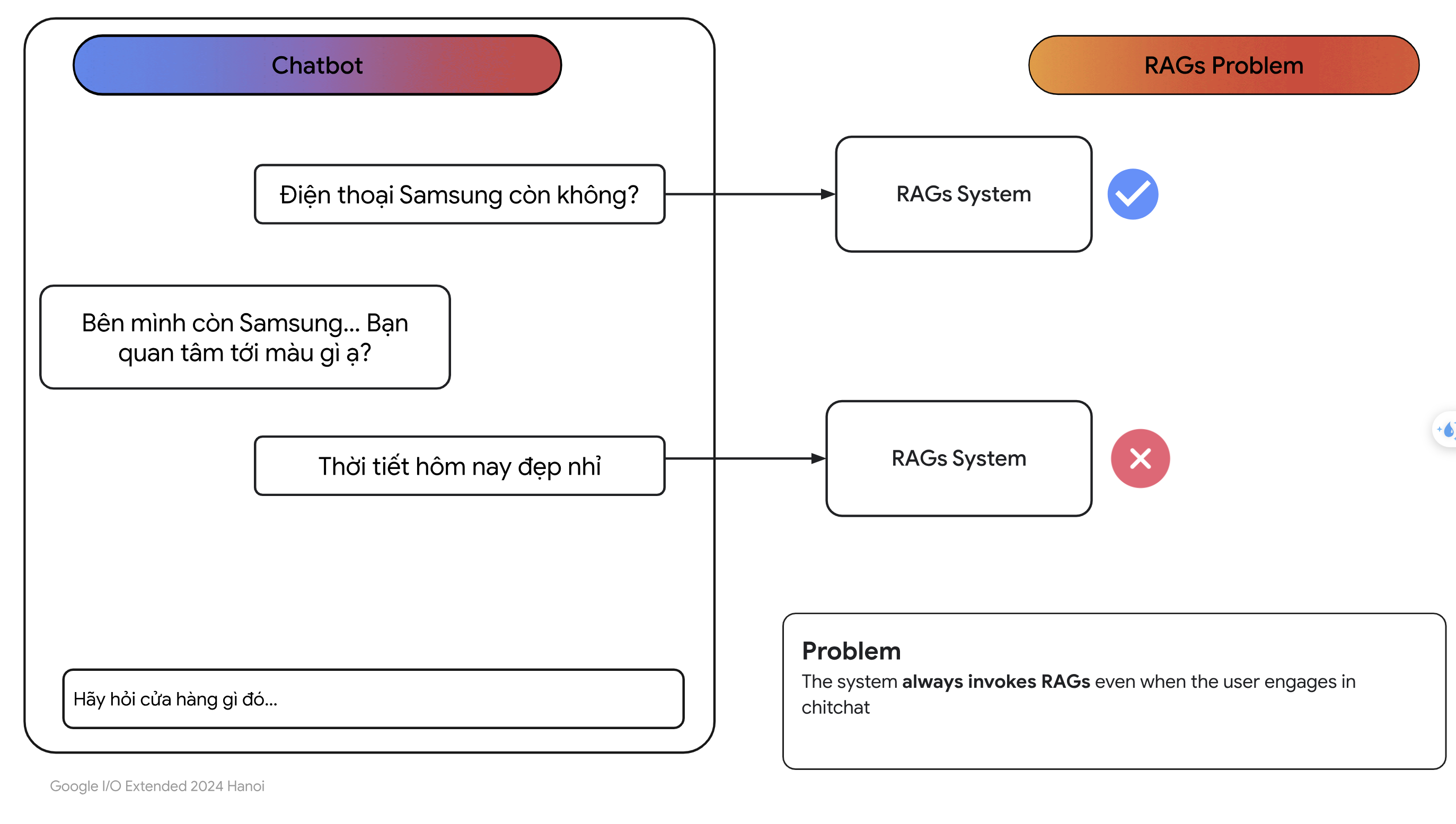
- Giả sử người dùng hỏi câu sau:
Thời tiets hôm nay đẹp nhỉ
- Rõ ràng đây là câu hỏi không liên quan đến các đoạn văn bản trong vector database. Một hệ thống RAG đơn giản vẫn sẽ tìm các đoạn văn bản liên quan đến câu hỏi của người dùng mặc cho phần score rất thấp.
- Để khắc phục được điều này, một cách bạn có thể nghĩ đến là đặt một ngưỡng cho score. Ví dụ như bạn sử dụng độ tương đồng cosine để tính điểm cho các vector embeddings. Bạn có thể đặt ngưỡng $0.8$, tức chỉ lấy các vector mà có số điểm lớn hơn $0.8$. Tuy nhiên các này khá là thiên về trực giác và không phải lúc nào chúng ta đặt ngưỡng cũng chuẩn. Có thể câu hỏi của người dùng không liên quan đến các sản phẩm của cửa hàng nhưng trong câu hỏi có nhiều từ giống với các câu hỏi về sản phẩm thì RAG vẫn có thể tính các câu hỏi ý với số điêm cao.
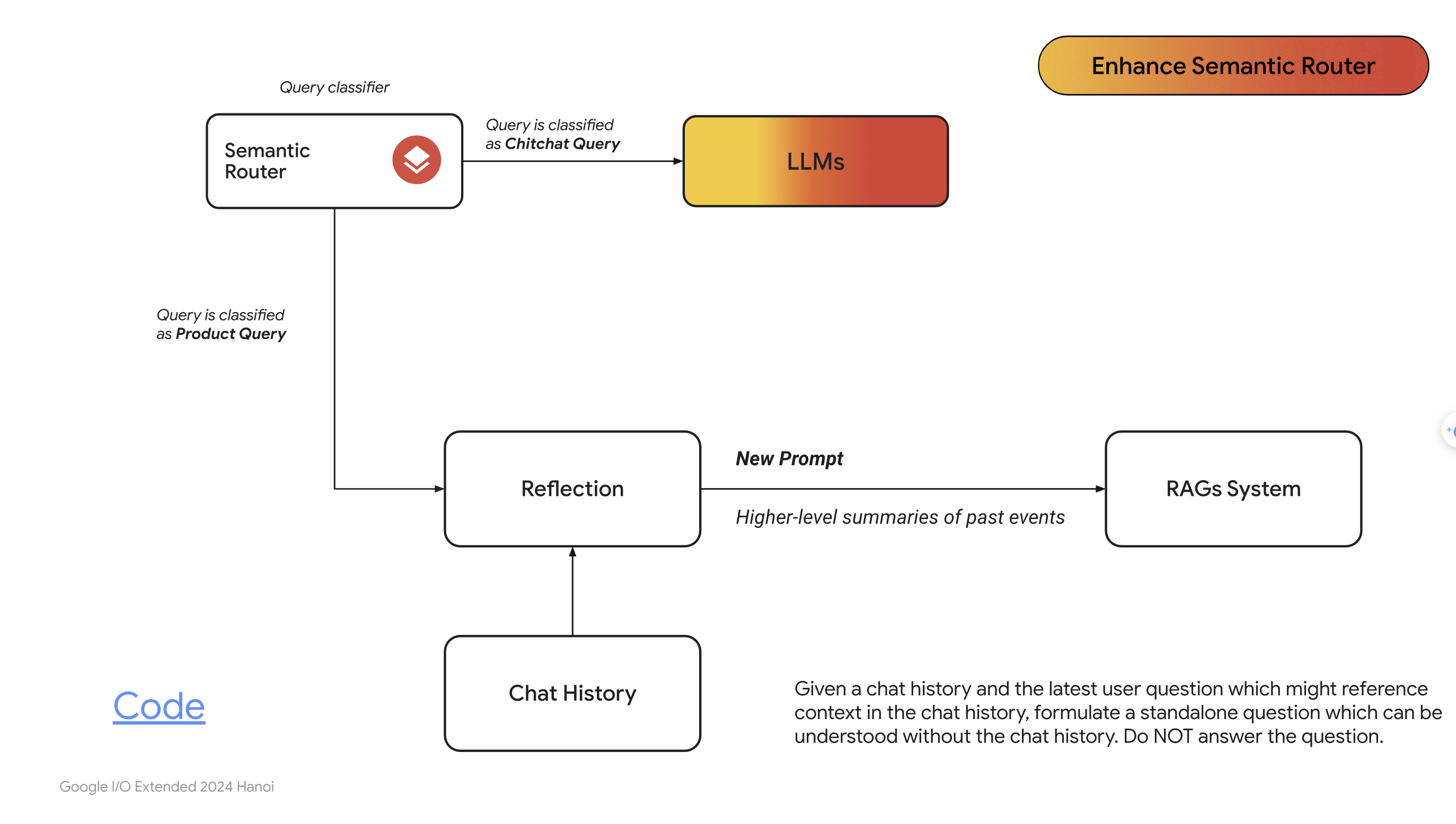
- Từ giờ, chúng ta sẽ gọi chung những câu hỏi không liên qauan đến sản phẩm của cửa hàng là chitchat, tức những câu hỏi phiếm. Một giải pháp khác thay thế cho giải pháp dùng ngưỡng, đó là sử dụng một bộ phân loại câu hỏi, người ta hay gọi nó là Semantic Router:
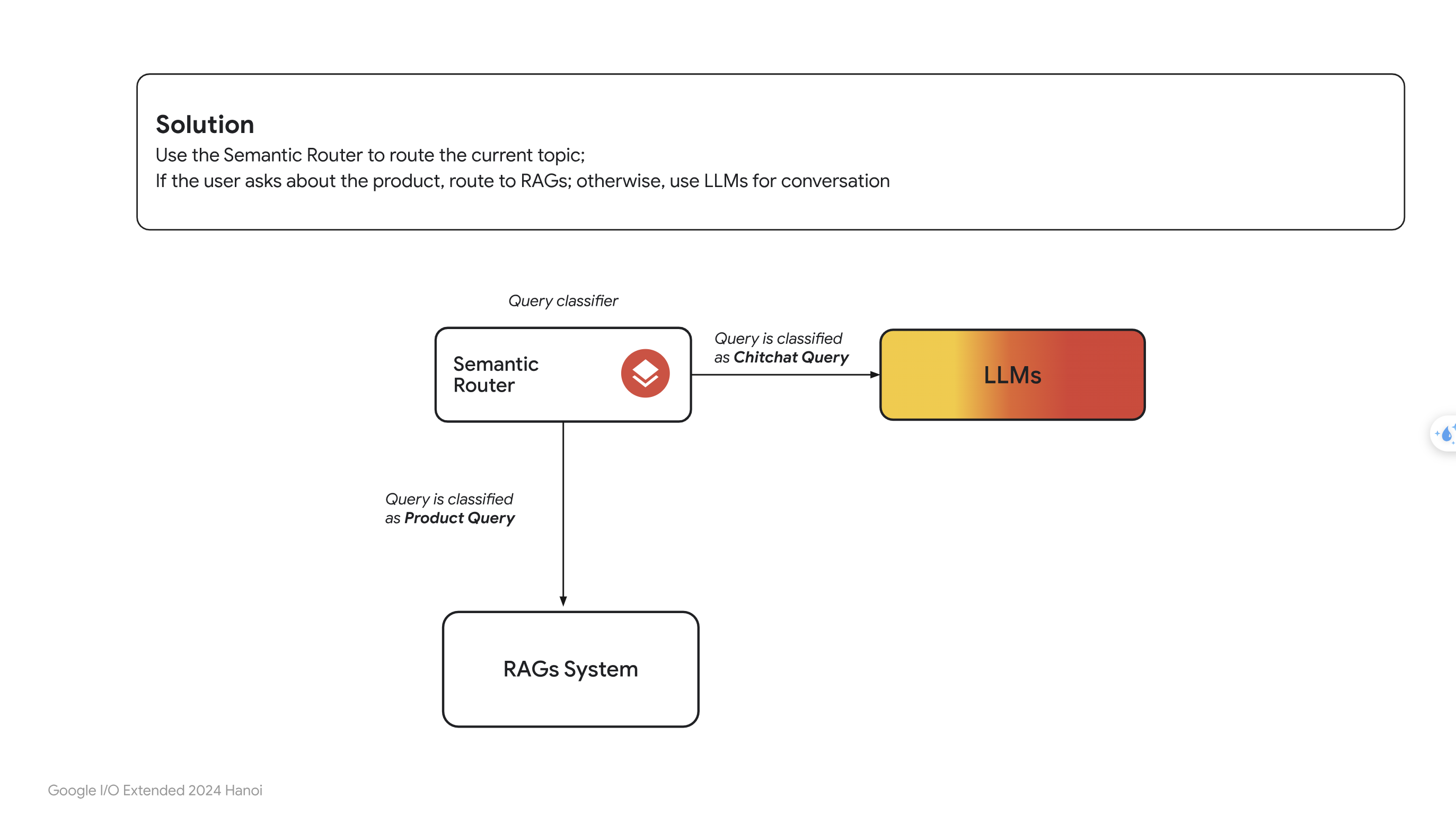
- Nhìn vào ảnh trên, hãy nghĩ đơn giản Semantic Router là một mô hình phân loại câu hỏi của người dùng. Nếu câu hỏi thuộc dạng chitchat thì sẽ được đưa trực tiếp qua LLMs luôn mà không cần qua RAG. Còn nếu như câu hỏi thuộc dạng hỏi về sản phẩm thì sẽ đưa vào RAG.
- Vậy làm cách nào để xây dựng được mô hình Semantic Router ? Bạn có thể thử nghĩ nhiều cách, có thể xây dựng một mô hình học máy để phân loại text, hoặc cao tay hơn thì có thể tự xây dựng một mô hình dùng Bert, Transfomer để embedding rồi phân loại. Sau đây, tôi sẽ chỉ cho các bạn một cách xây dựng mô hình Semantic Router đơn giản nhất.
- Đầu tiên là bước Samples Generation, trong bước này, chúng ta sẽ nhờ LLMs sinh ra một dataset gồm các câu hỏi thuộc dạng chitchat và các câu hỏi thuộc dạng sản phẩm và có nhãn sẵn. Ảnh dưới là một ví dụ minh họa:
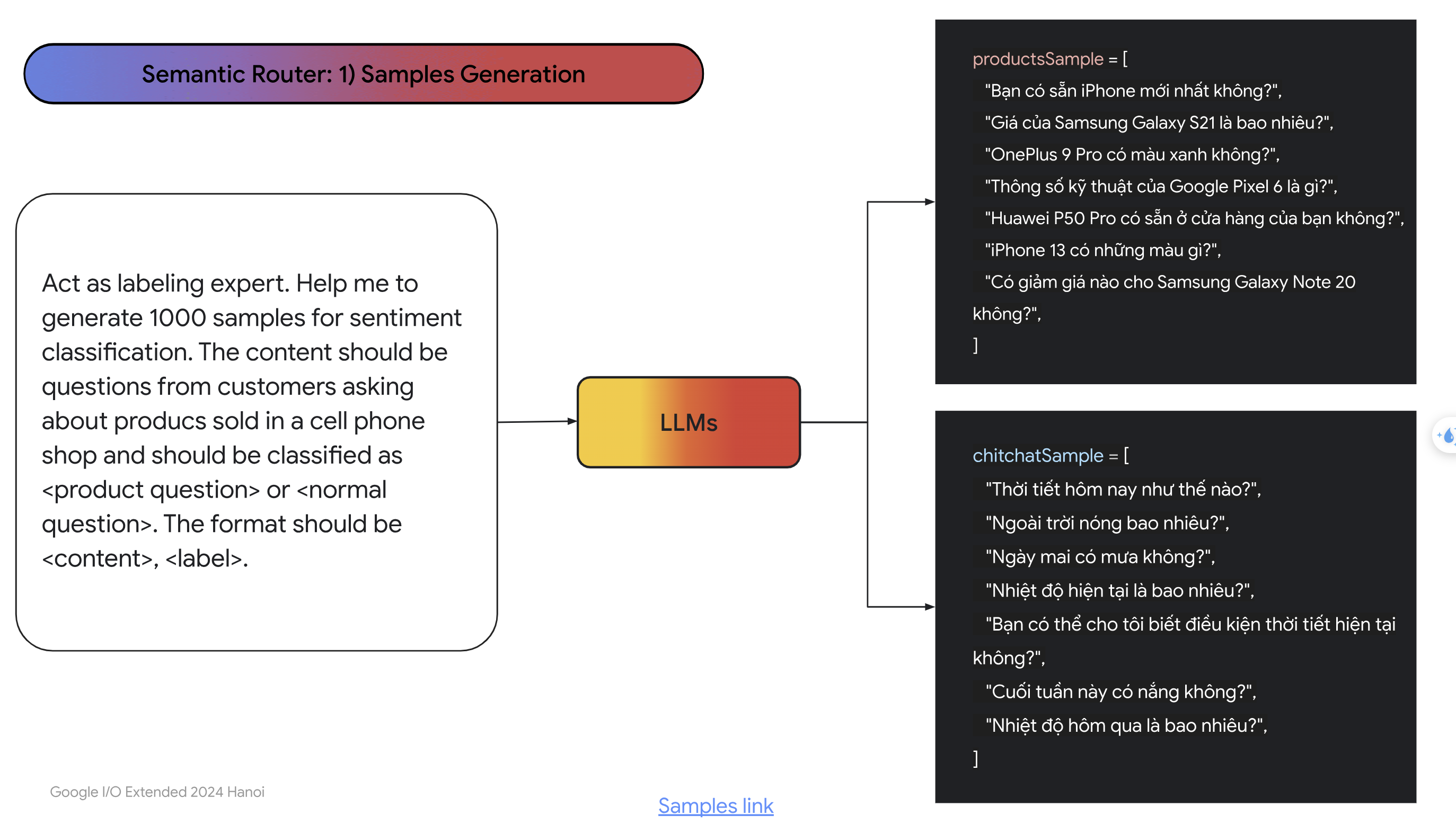
- Sau đó, chúng ta sẽ emebdding các câu trong data này sang dạng vector, nên sử dụng cùng với mô hình mà embedding câu hỏi của người dùng:
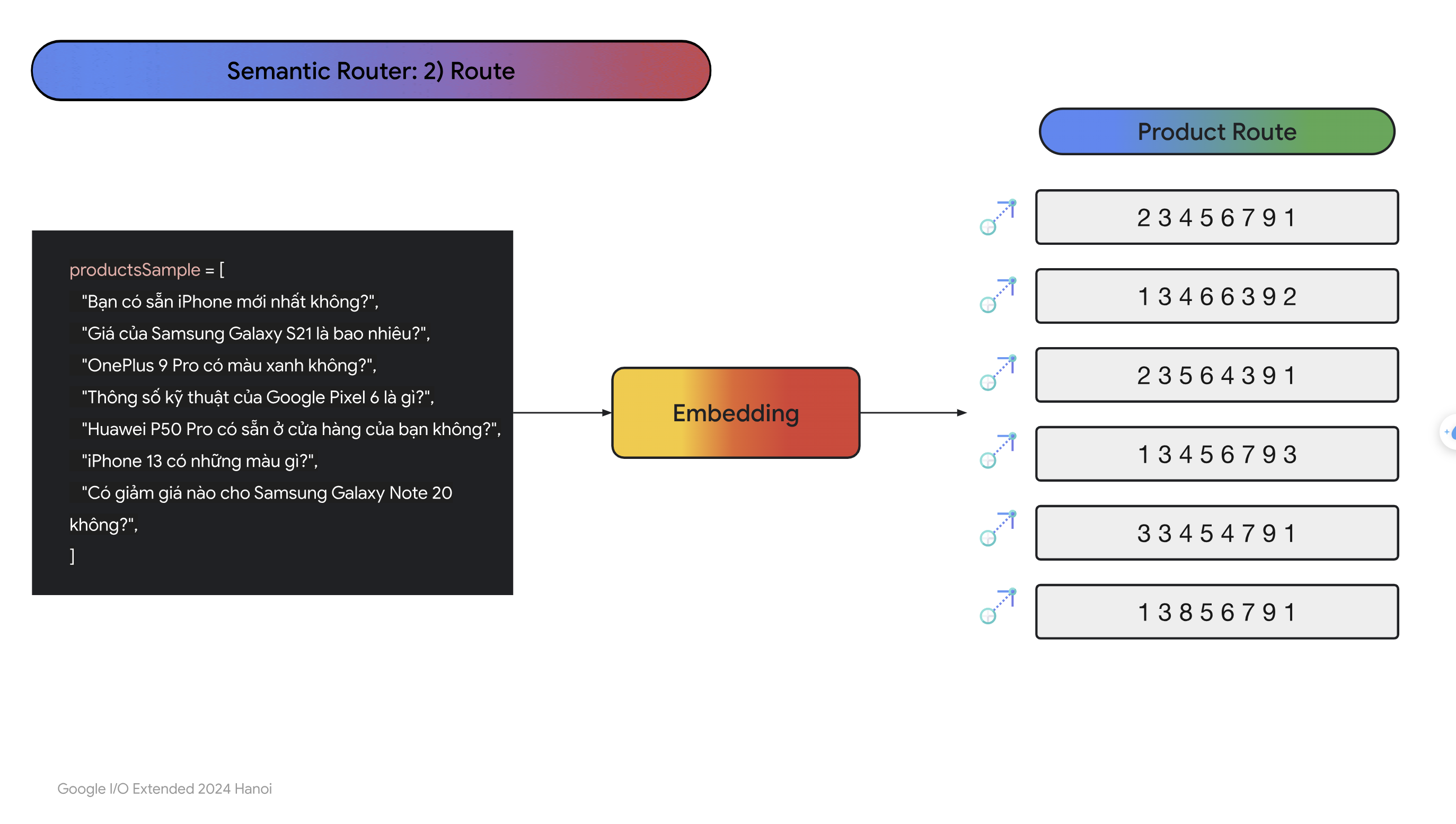
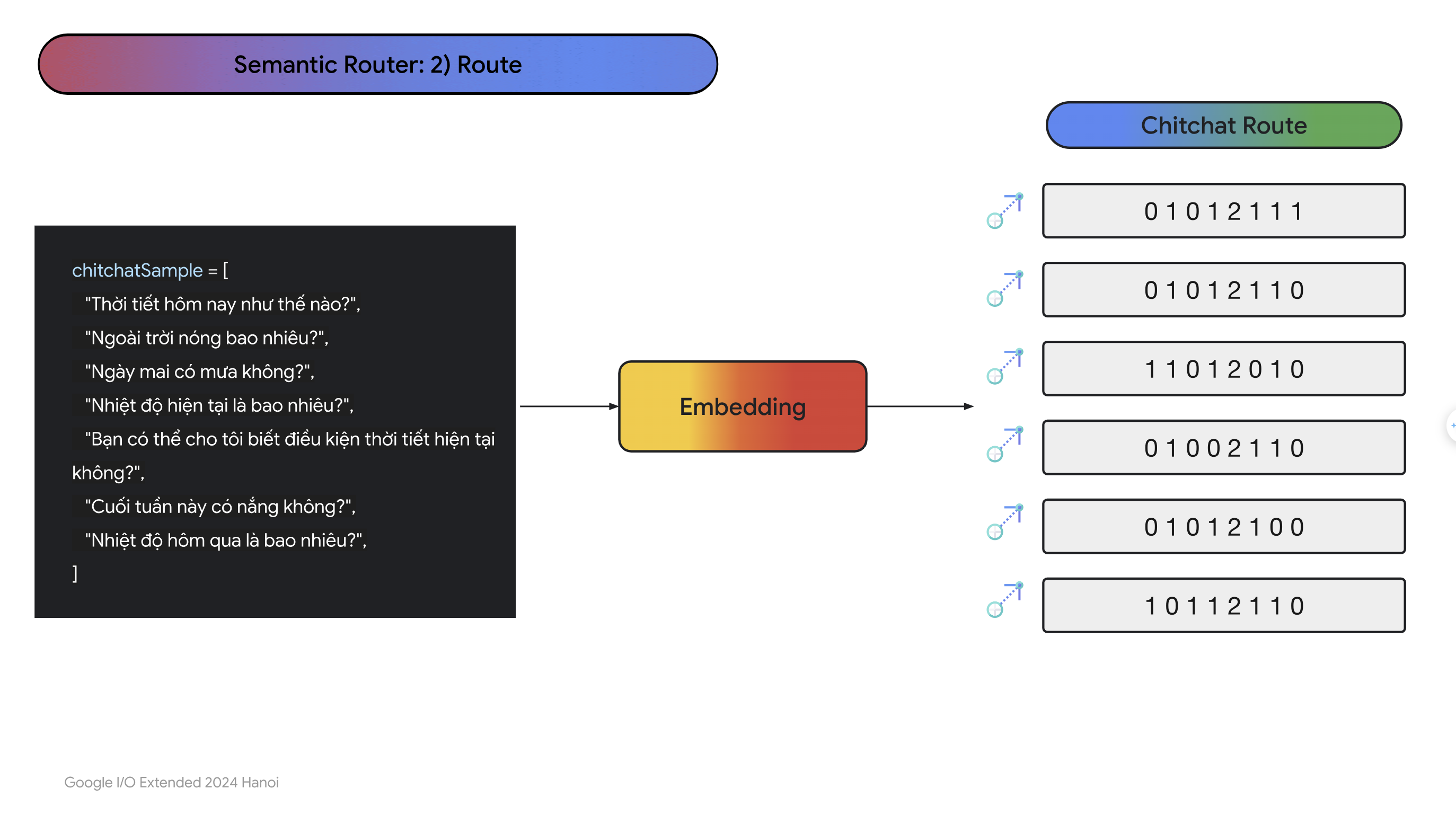
- Sau khi chuyển các câu do LLMs sinh ra qua vector rồi thì ví dụ như người dùng nhập câu hỏi:
Thời tiết thế nào ?
- Ta sẽ emebdding câu hỏi này sang dạng vector và tính score với các vector thuộc dạng chitchat rồi tính trung bình, làm tương tự như với các vector thuộc dạng sản phẩm rồi tính trung bình. Bên nào cao hơn thì nhiều khả năng câu hỏi sẽ liên quen đến bên ý hơn:
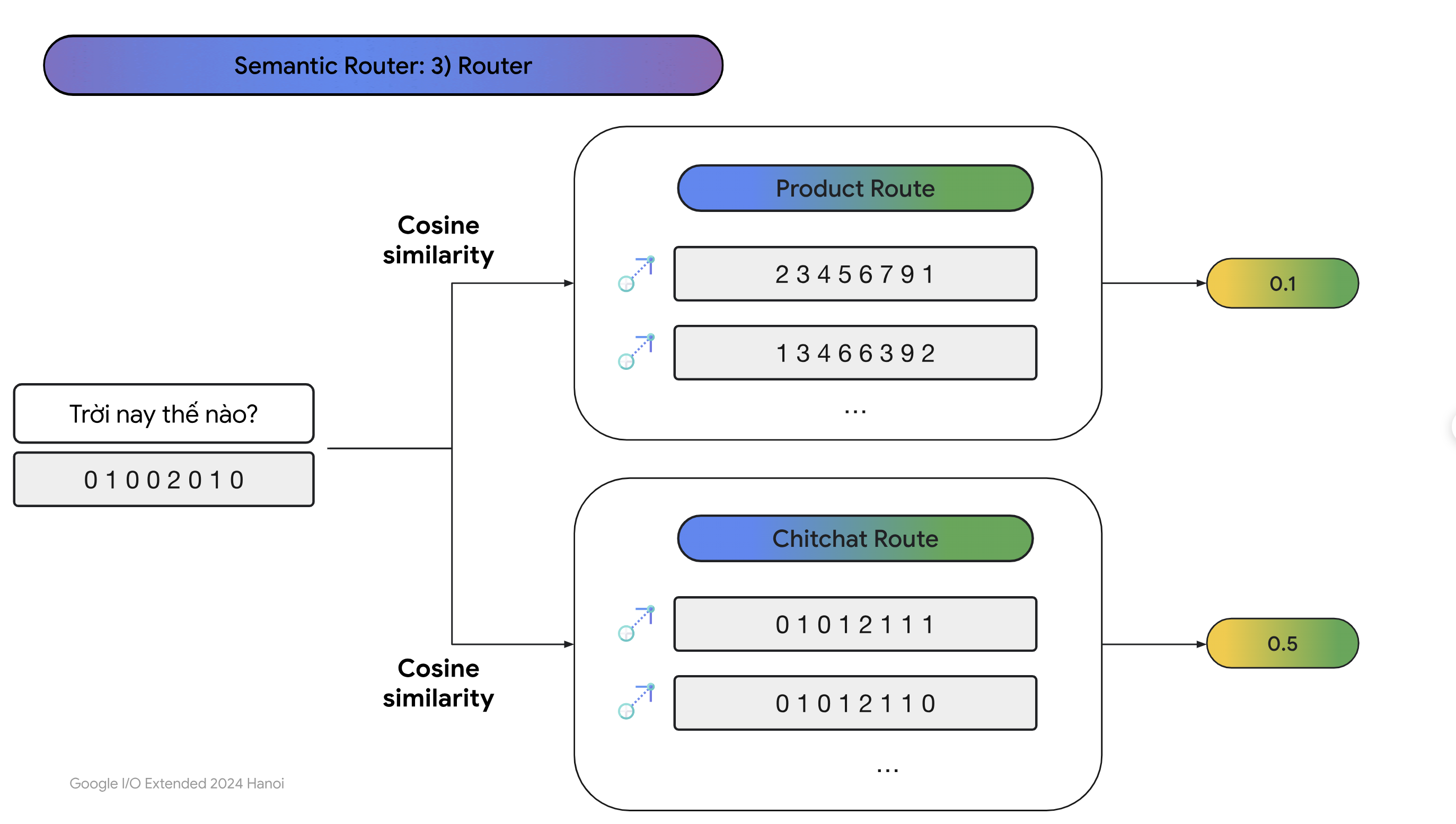
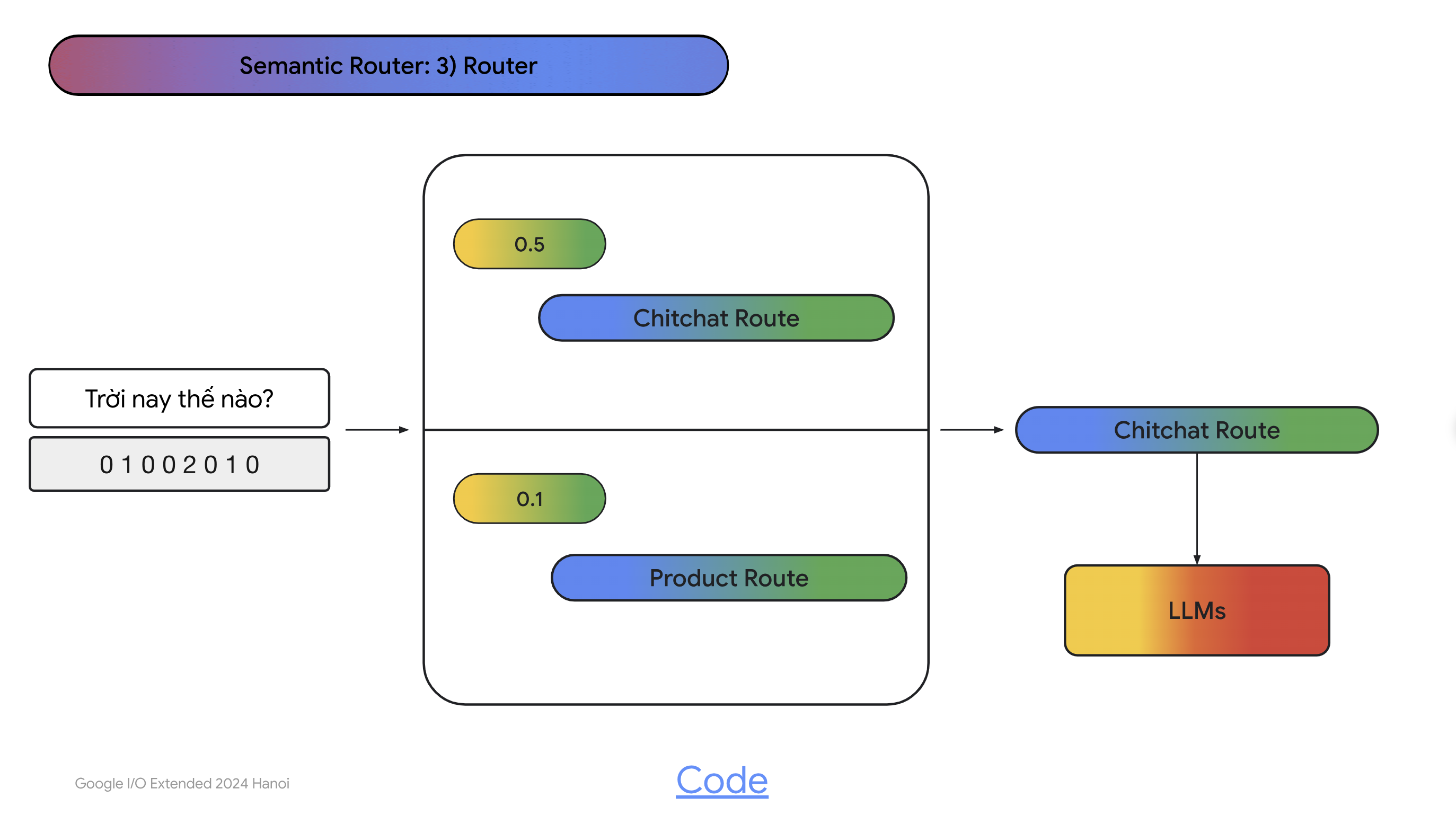
- Đây là code ví dụ về Semantic Router, bạn có thể tự code phần này vì ý tưởng khá đơn giản:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import numpy as np
class SemanticRouter():
def __init__(self, embedding, routes):
self.routes = routes
self.embedding = embedding
self.routesEmbedding = {}
for route in self.routes:
self.routesEmbedding[
route.name
] = self.embedding.encode(route.samples)
def get_routes(self):
return self.routes
def guide(self, query):
queryEmbedding = self.embedding.encode([query])
queryEmbedding = queryEmbedding / np.linalg.norm(queryEmbedding)
scores = []
# Calculate the cosine similarity of the query embedding with the sample embeddings of the router.
for route in self.routes:
routesEmbedding = self.routesEmbedding[route.name] / np.linalg.norm(self.routesEmbedding[route.name])
score = np.mean(np.dot(routesEmbedding, queryEmbedding.T).flatten())
scores.append((score, route.name))
scores.sort(reverse=True)
return scores[0]
- Dưới đây là pipeline của hệ thống RAG khi đã thêm Semantic Router:
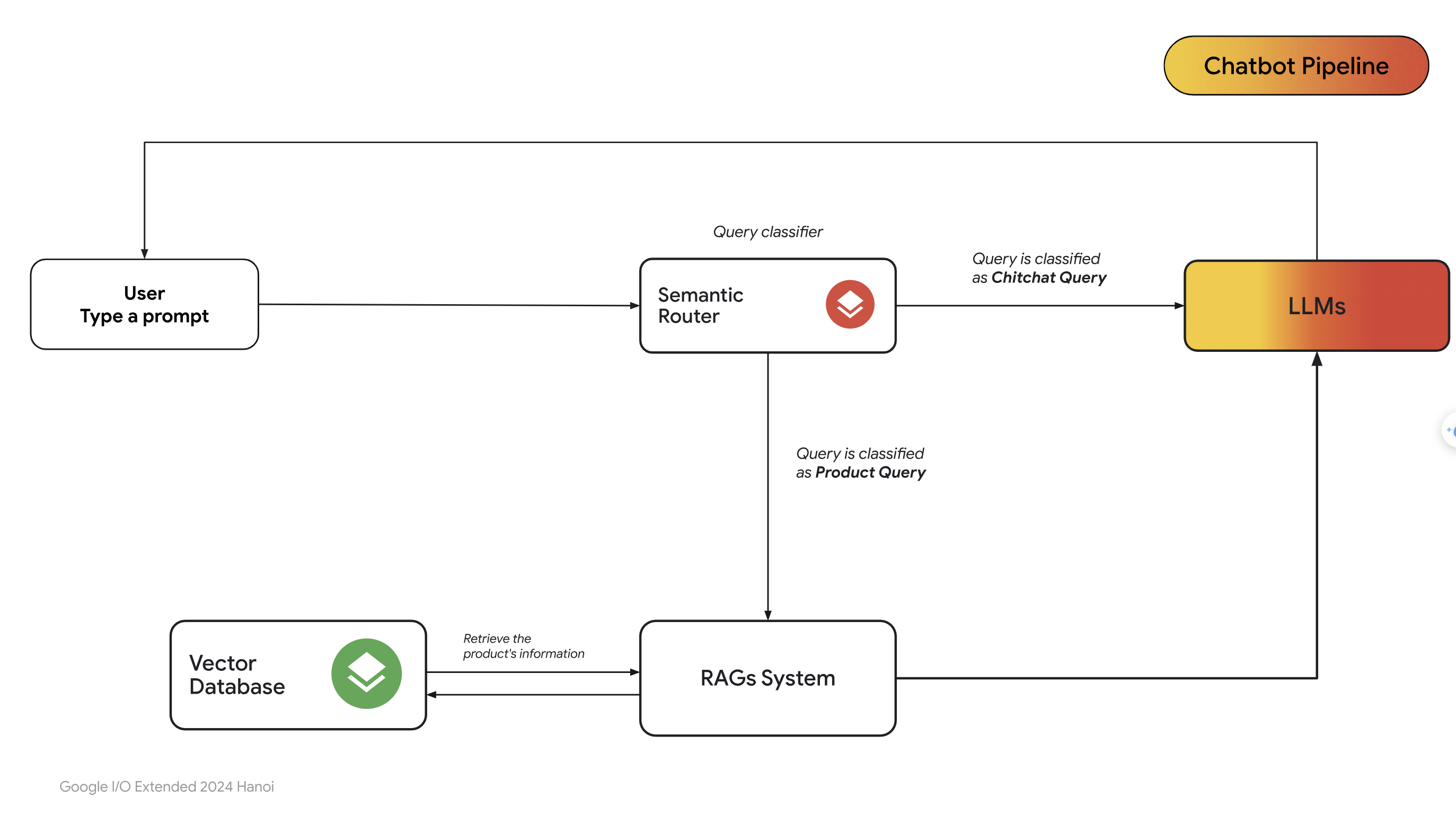
- Nhưng liệu thực sự đã hết vấn đề về RAG chưa ? Giả sử người dùng nhập các câu hỏi như hình dưới đây:
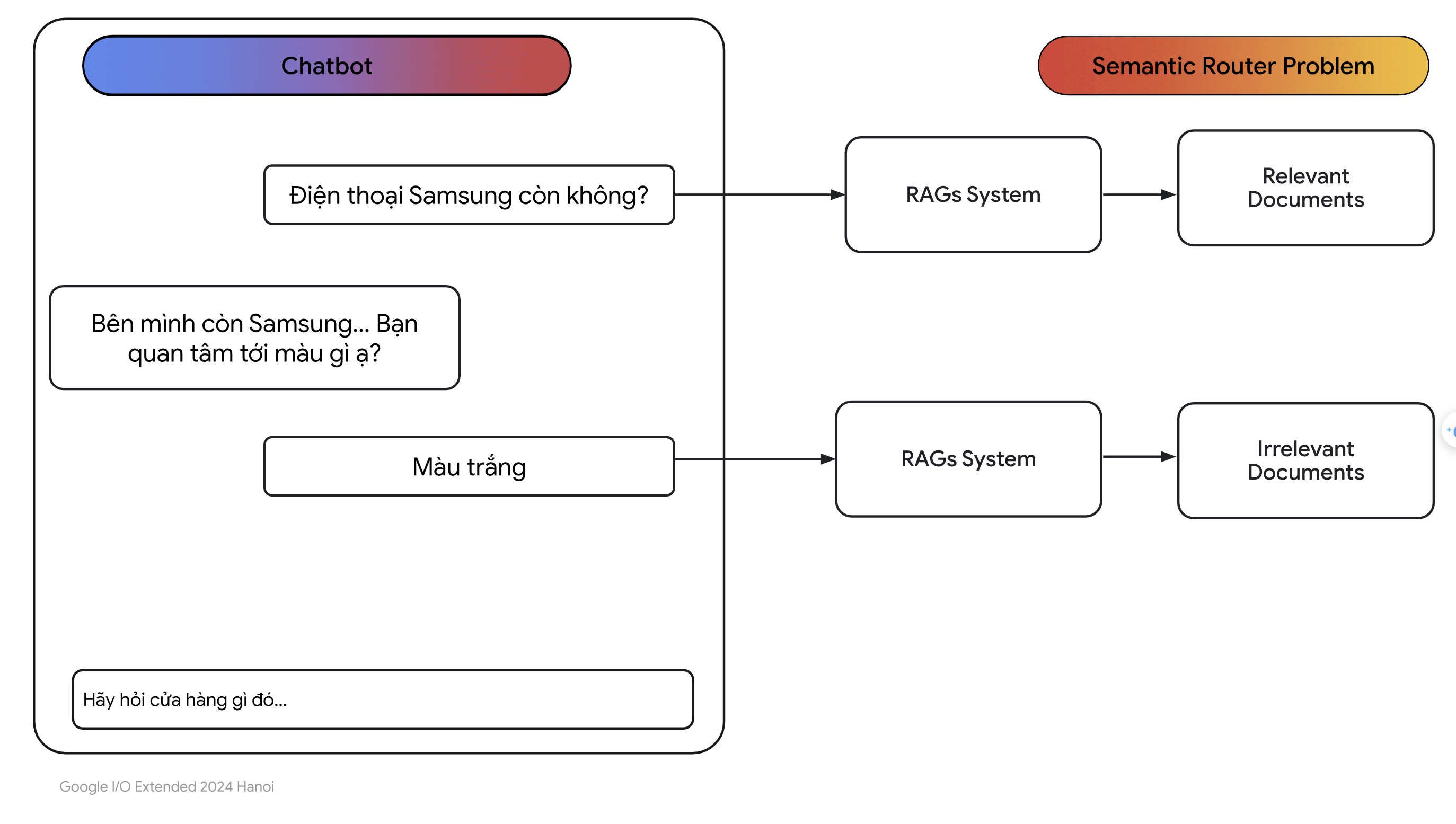
- Như các bạn thấy, người dùng hỏi câu đầu tiên là:
Điện thoại Samsung còn không ?
- Câu hỏi này không có vấn đề gì và sẽ được Semantic Router phân loại thành câu hỏi thuộc dạng hỏi sản phẩm. Tiếp theo người dùng hỏi câu hỏi:
Màu trắng
Ở đây rõ ràng là người dùng không muốn nhắc lại các từ đã hỏi. Có hai vấn đề xảy ra ở đây, câu hỏi này sẽ được Semantic Router phân thành câu hỏi thuộc dạng chitchat (điều chúng ta muốn câu hỏi này thuộc dạng sản phẩm). Và kệ cả như câu hỏi này được phân loại đúng thành câu hỏi thuộc dạng sản phẩm thì hệ thống RAG sẽ tìm kiếm các văn bản liên quan đến câu hỏi này trong vector database, lưu ý là lúc này câu hỏi chỉ là “Màu trắng” nên RAG có thể sẽ tìm ra được những văn bản không liên quan đến câu hỏi này.
Để giải quyết vấn đề này, chúng ta sẽ sử dụng một kĩ thuật nữa gọi là Reflection nhằm tổng hợp tất cả các đoạn hội thoại quá khứ liên quan đến câu hỏi hiện tại của người dùng:
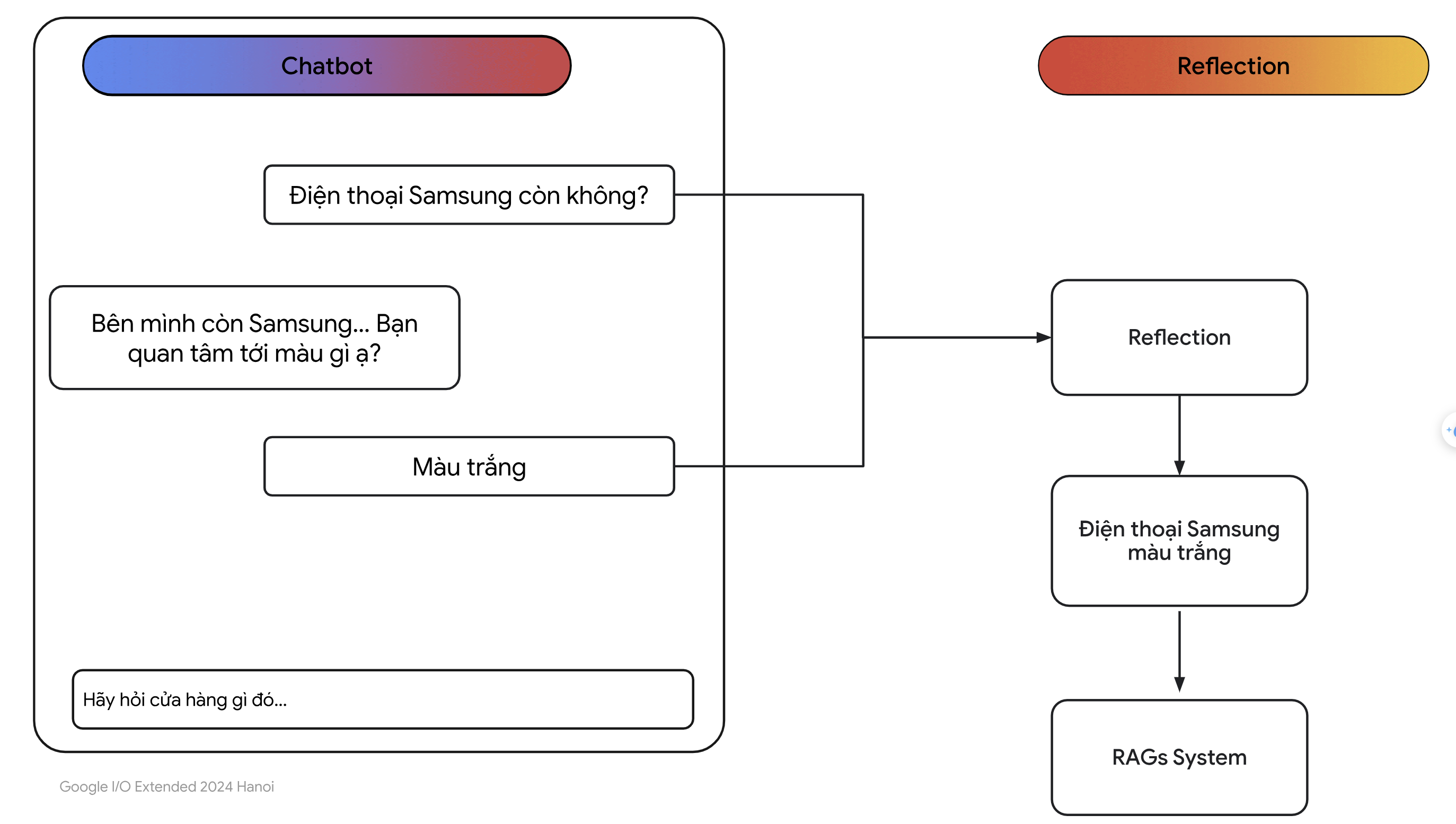
- Luồng chạy của hệ thống RAG sau khi thêm khối Reflection được diễn ra như hình dưới:
- Hiểu đơn giản thì khối Reflection chính là một con LLMs có tác dụng tổng hợp thông tin ở quá khứ. Nhìn vào hình ảnh, sau khi câu hỏi của người dùng được phân vào dạng câu hỏi sản phẩm thì chúng ta đi vào khối Reflection bằng cách hỏi LLMs như sau:
Given a chat history and the latest user question wich might reference context in the chat history, formulate a standalone question which can be understood without the chat history. Do NOT answer the question.
- Đại ý là bạn sẽ phải lưu lại lịch sử trò chuyện của người dùng với chatbot và tổng hợp cuộc hội thoại ý với câu hỏi gần đây nhất trong một câu. Lúc này câu hỏi đã có được thông tin ngữ cảnh trong quá khứ, sẽ rất đễ để mô hình có thể trả lời.
- Pipeline của hệ thống RAG bây giờ sẽ trông như sau:
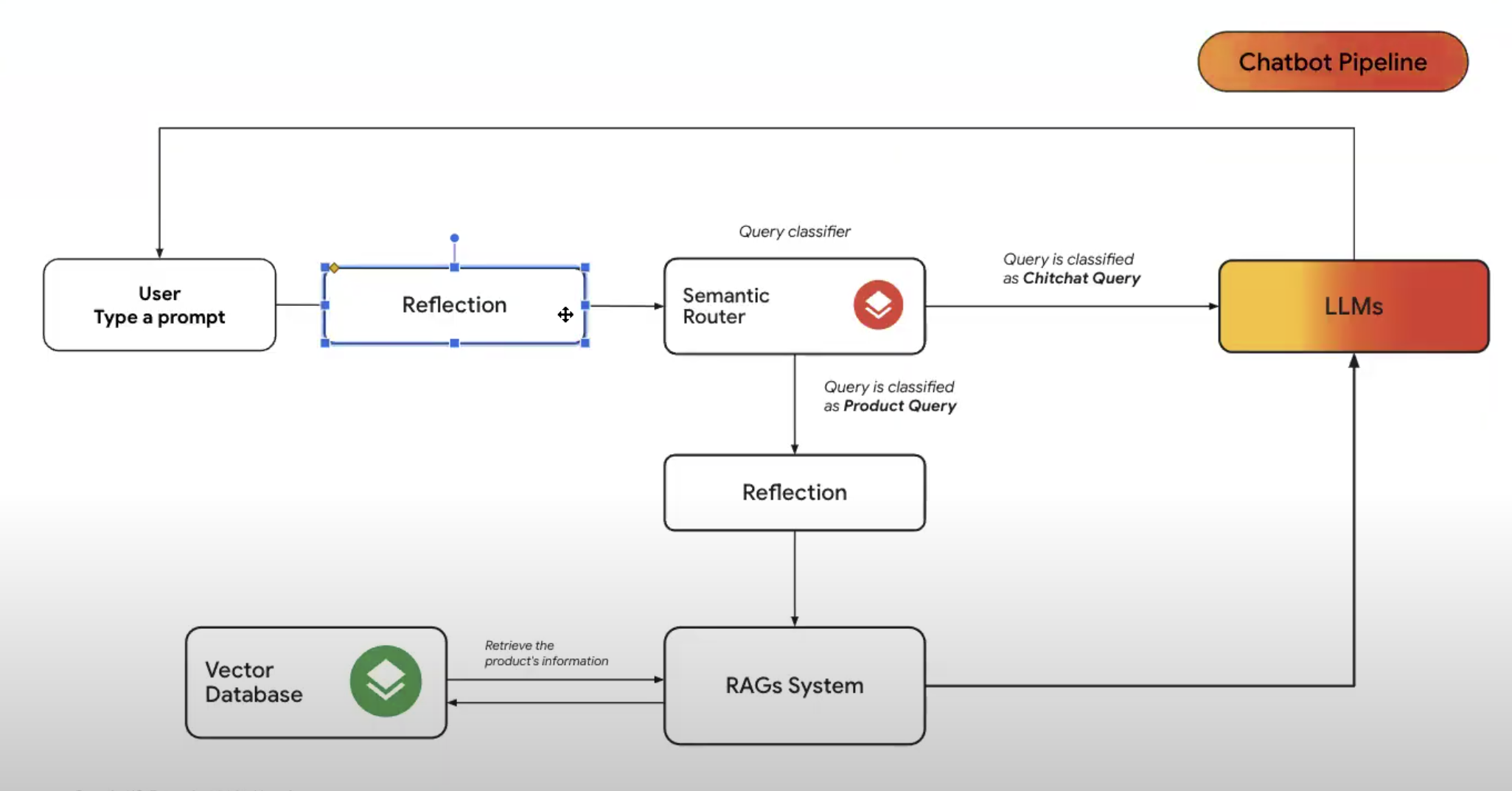
Để ý rằng lúc này, chúng ta có thêm khối Reflection trước khối phân loại Semantic Router, mục đích của việc này để phân loại câu hỏi của người dùng về đúng dạng của nó.
Vậy là chúng ta đã đi qua một số nội dung cơ bản về RAG. Nhưng RAG là một hệ thống rất rộng với rất nhiều kĩ thuật nâng cao, tôi sẽ dành một viết khác nói chi tiết hơn về phần này. Dưới đây là bức tranh toàn thể của hệ thống:
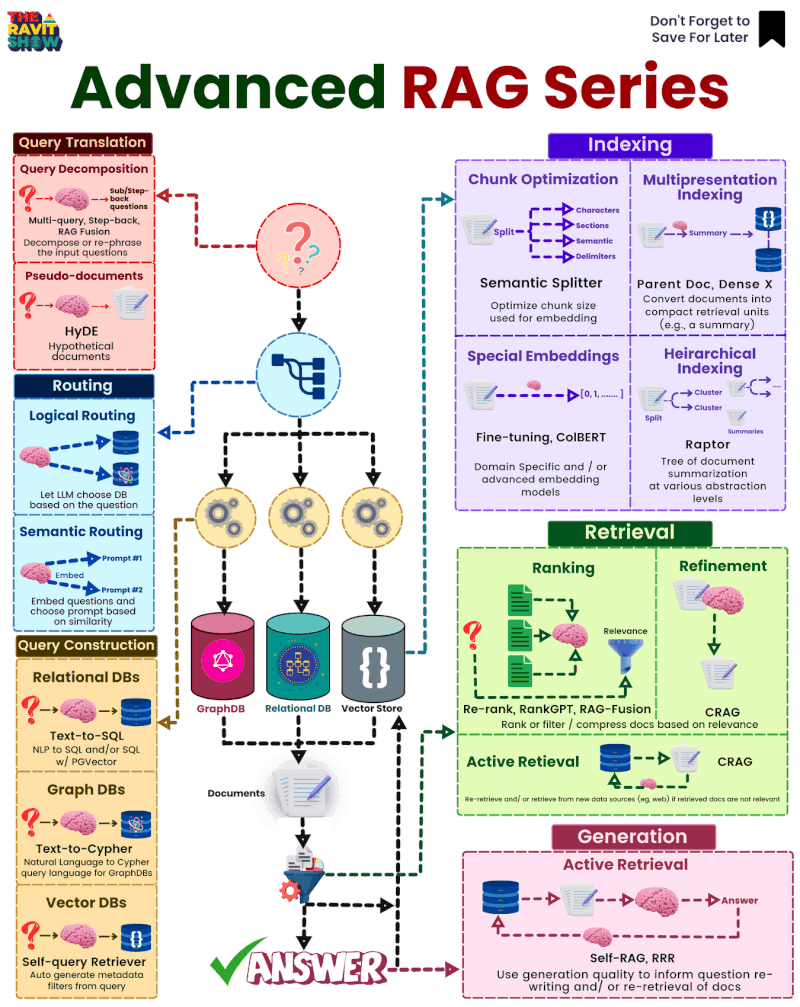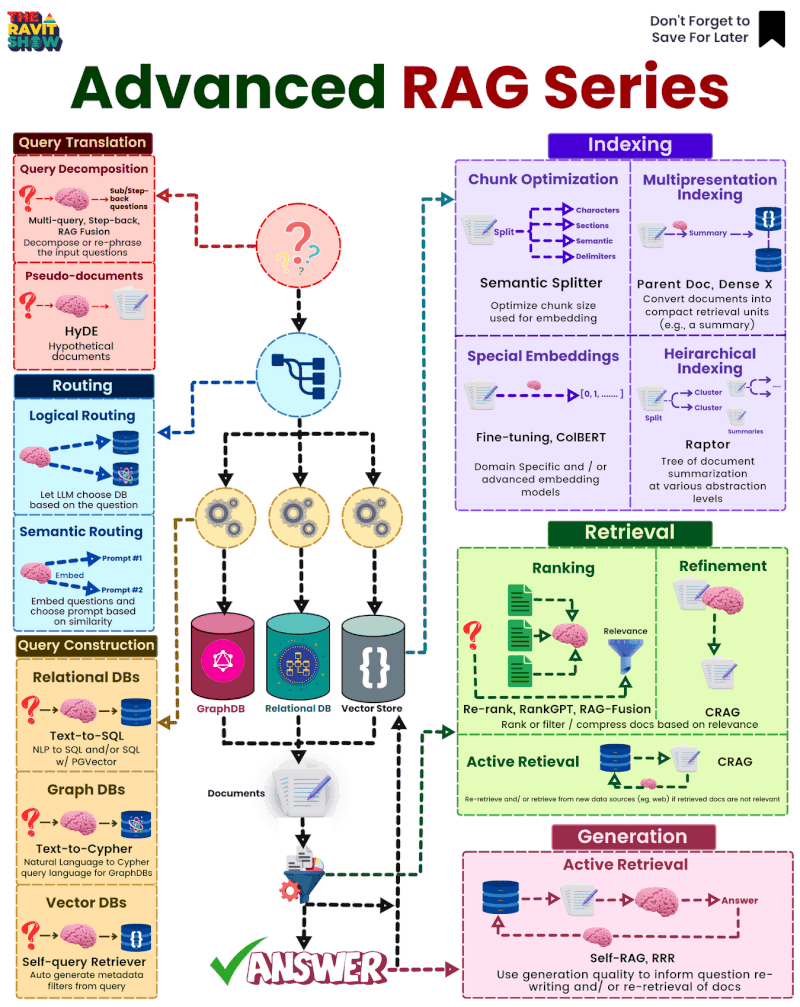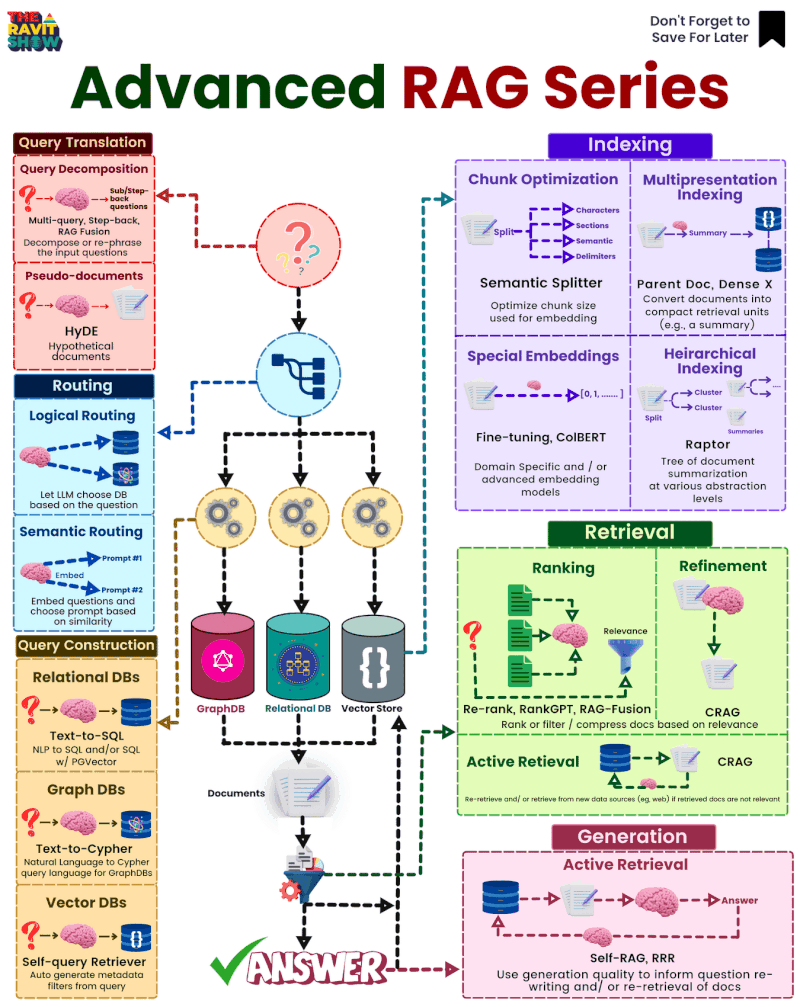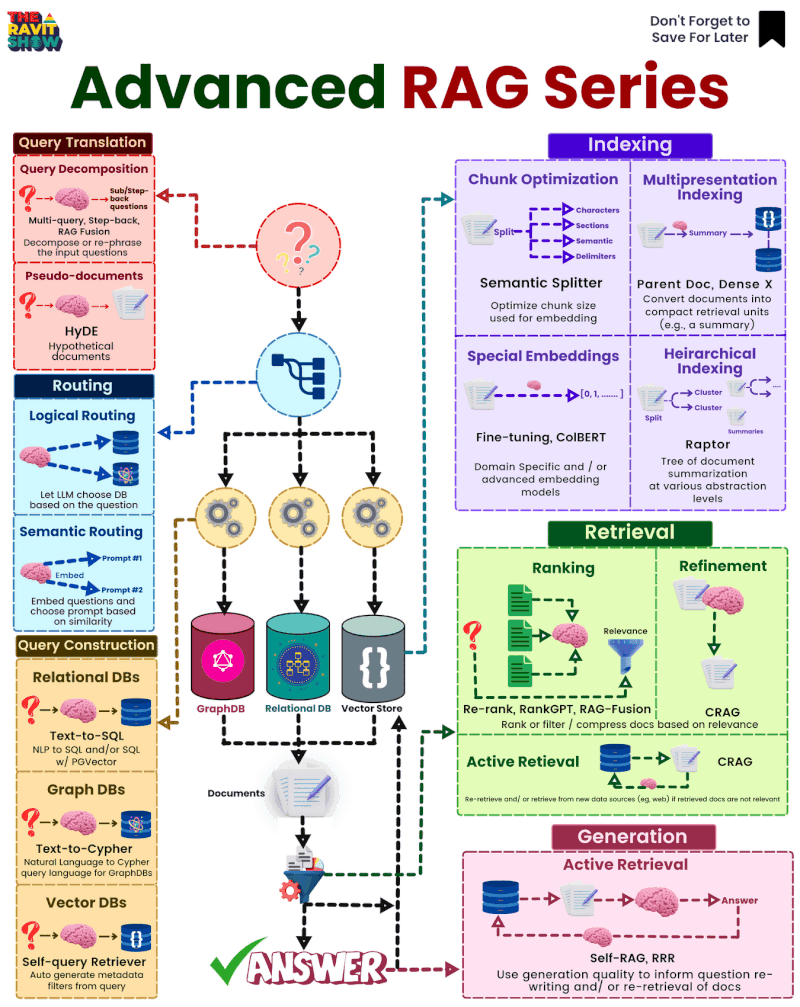
- Bạn có thể đọc qua paper về các best practise trong RAG: Searching for Best Practices in Retrieval-Augmented Generation
4. Tài Liệu Tham Khảo.
- [1] RAG - ProtonX