Sử Dụng API Văn Bản
API (Application Programming Interface) là cầu nối cho phép các ứng dụng giao tiếp và sử dụng dịch vụ từ bên thứ ba. Với API văn bản, bạn có thể khai thác sức mạnh của các nền tảng như OpenAI, Claude, hay Gemini để xử lý ngôn ngữ tự nhiên, tạo nội dung, và phân tích dữ liệu. Blog này sẽ hướng dẫn bạn cách bắt đầu sử dụng các API này, từ việc thiết lập đến tích hợp chúng vào ứng dụng của mình.
1. Mô hình Client-Server.
Mô hình
Client-Serverlà kiến trúc cơ bản giúp các hệ thống giao tiếp với nhau qua mạng. Trong mô hình này:Client:Là phía yêu cầu, thường là ứng dụng của bạn (ví dụ: một trang web hoặc ứng dụng di động).Clientgửi yêu cầu (request) để lấy dữ liệu hoặc sử dụng dịch vụ từServer.Server:Là phía cung cấp, xử lý yêu cầu từClientvà trả về kết quả (response).
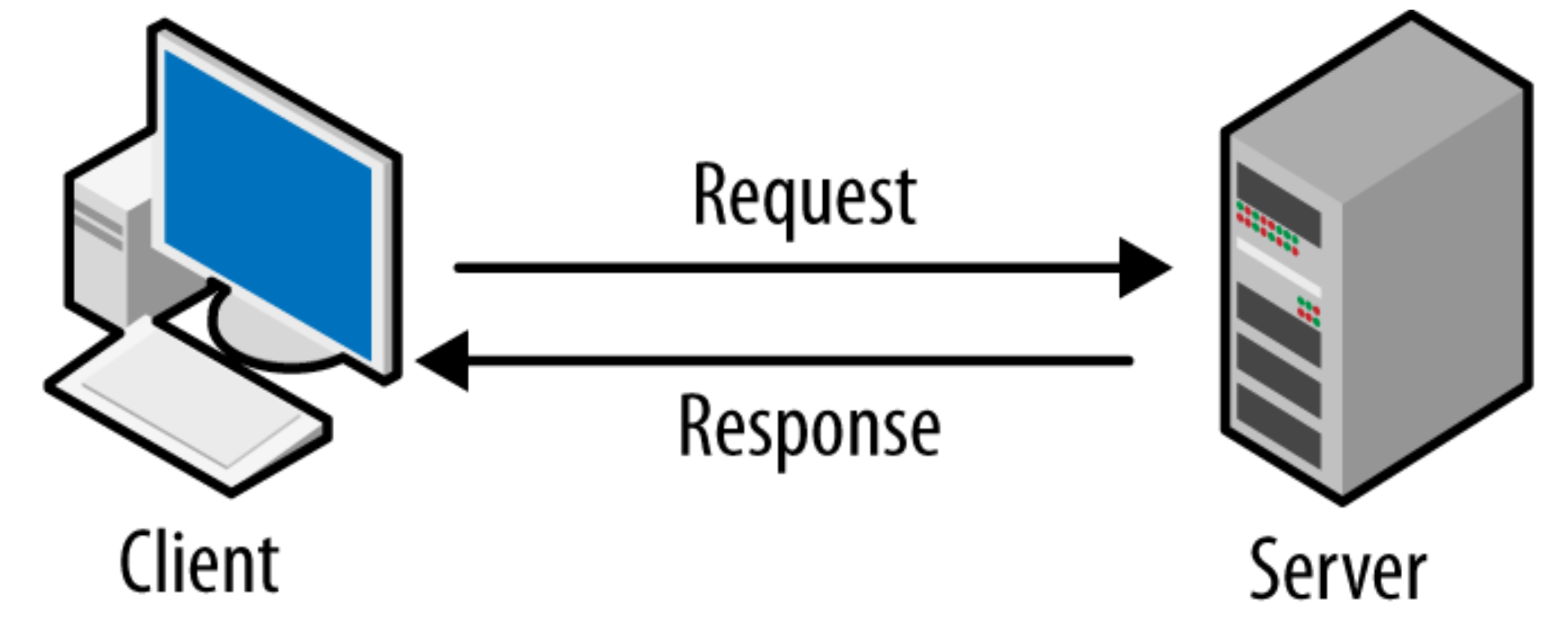
- Khi tích hợp
APIvào ứng dụng,APIđóng vai trò trung gian giữaClientvàServer. Cụ thể:
Client(ứng dụng của bạn) gửi yêu cầu tớiAPI, ví dụ: yêu cầu tạo văn bản từOpenAI GPT.APInhận yêu cầu, xử lý bằng hệ thống của bên thứ ba (nhưOpenAI,ClaudehoặcGemini).- Server
APItrả về kết quả, thường dưới dạng dữ liệuJSON, choClientđể hiển thị hoặc sử dụng.
Ví dụ đơn giản, bạn muốn tạo một đoạn văn bản bằng
OpenAI API:Clientcủa bạn (ứng dụng) gửi yêu cầu gồm nội dung như: “Viết một đoạn văn giới thiệu về công nghệ AI.”ServercủaOpenAInhận yêu cầu, xử lý, và trả về đoạn văn đã tạo. Client nhận kết quả và hiển thị cho người dùng.
2. Cách sử dụng API bên OpenAI.
API liên quan tới văn bản
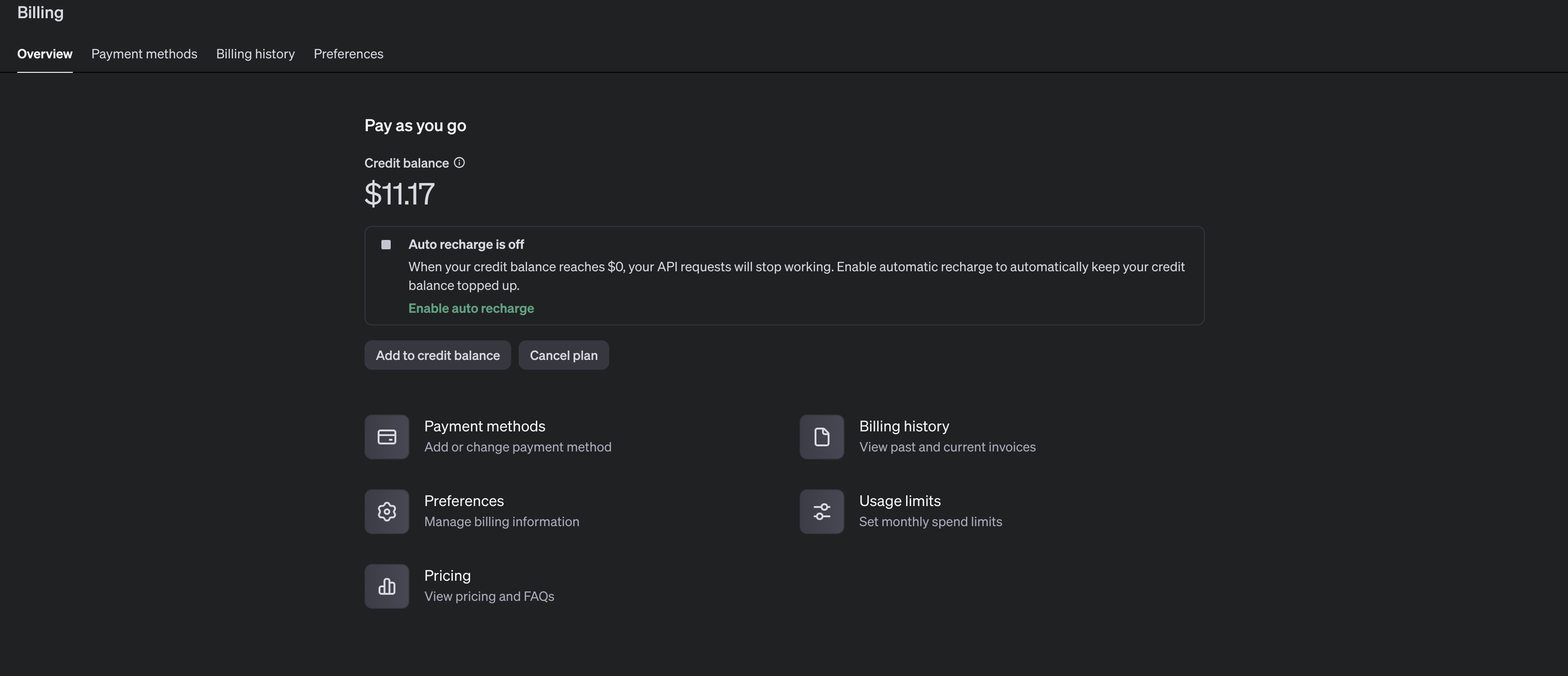
- Đầu tiên, bạn cần phải có một thẻ tín dụng hoặc thẻ visa để có thể sử dụng
APIbênOpenAI. Sau khi nạp tiền vào bạn có thể vào phầnBillingnhư ảnh dưới, như bạn đang thấy, tài khoản của tôi đang có 11.17 USD:
- Trước khi tạo
API, chúng ta hãy thử chơi đùa một chút bên OpenAI PlayGround
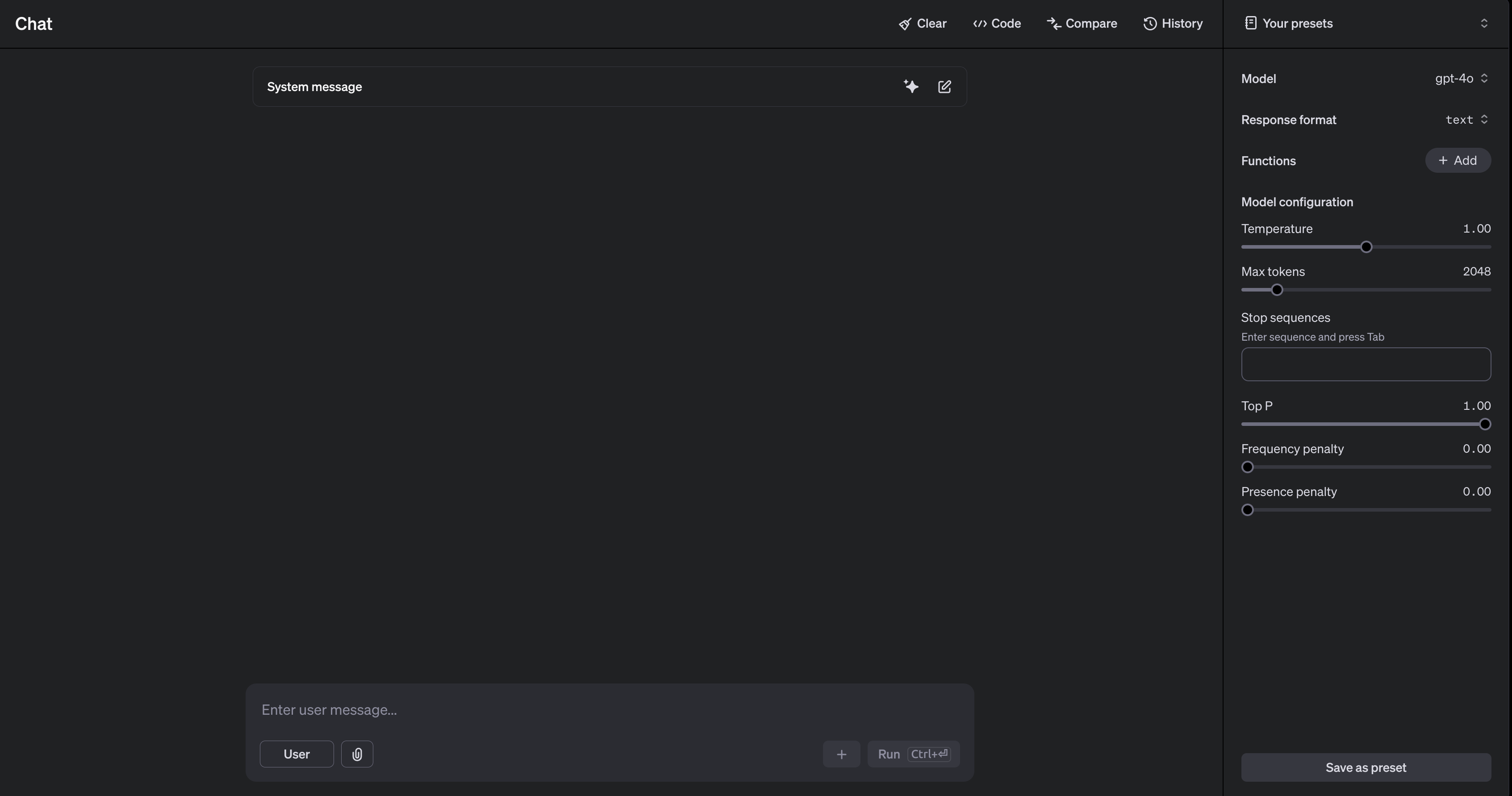
- Lưu ý rằng, bạn phải nạp tiền thì mới dùng được dịch vụ
PlayGroundnày. Nhìn qua thì cái này không khác gì giao diệnChat GPTbạn vẫn hay sử dụng hàng ngày, tuy nhiên phầnPlayGroundnày bạn sẽ được quyền chỉnh sửa các model khác nhau và cũng như các thông số dành riêng cho mô hình ngôn ngữ lớn. Chúng ta cùng điểm qua một vài thông số nào:Temperature: Khi bạn chỉnh thông số này thấp, có nghĩa là bạn muốn mô hình chọn các token có xác suất cao, dùng trong các tác vụ cần chính xác cao như Hỏi đáp (QA) hay suy luận (reasoning). Còn khi bạn chỉnh thông số này cao, có nghĩa là bạn muốn mô hình lựa chọn token ngẫu nhiên hơn, tăng tính sáng tạo, dùng trong các tác vụ sáng tạo như viết văn, sáng tác thơ.Top P:Top Pquan tâm đến một nhóm nhỏ top các tokens có tổng xác suất ít nhất bằng p.Top pnhỏ có nghĩa là nhóm tokens được quan tâm nhỏ, tính chắc chắn cao.Top plớn có nghĩa là nhóm tokens được quan tâm lớn, tính bay bổng cao.Frequency Penalty: Phạt trên tỉ lệ token tiếp theo với số lần token này đã xuất hiện trên prompt + response. Giá trị này cao, token đã xuất hiện ít có khả năng lặp lại.Presence Penalty: Kiểm soát việc lặp lại của những từ phía trước. Tập trung vào việc đa dạng hóa nội dung. Ví dụ từ trước dùng là “chăm chỉ”, mô hình sẽ có xu hướng chọn từ sau là “cần cù”. Khi giá trị này cao, kết quả sinh ra sẽ tập trung vào việc trên.
- Nếu bạn chưa hiểu thông số trên thì bản chất các mô hình ngôn ngữ lớn là các mô hình xác suất. Tức là nó sẽ chọn token có khả năng xuất hiện nhất để nó trả lời. Hãy nhìn vào ảnh dưới đây:
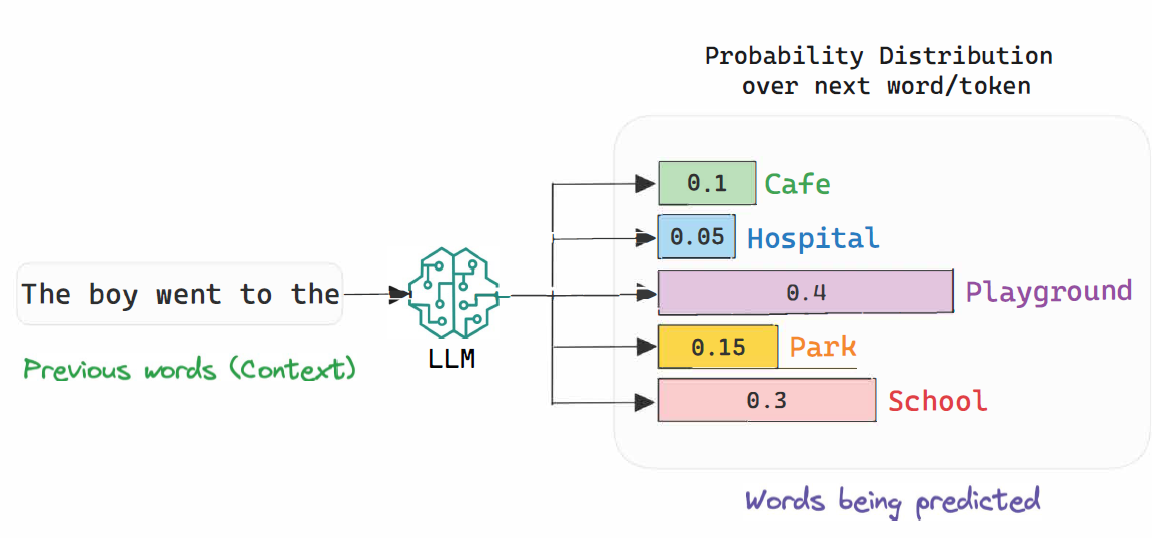
- Ví dụ như mô hình đang trả lời đến câu: “The boy went to the [?]”. Chỗ [?] mô hình sẽ phải suy nghĩa là mình nên chọn token nào có xác suất lớn nhất. Như bạn thấy trên hình, mô hình có 5 phương án là các token: Cafe, Hospital, Playground, Park, School. Trên thực tế thì mô hình có cả triệu token để cân nhắn nên chọn cái nào.
- Quay trở lại với các thông số. Thường thì người ta sẽ chỉnh thông số
Top Ptrước, lưu ý rằng thông số này chạy từ 0 đến 1, nếu tôi chỉnhTop P = 0.5thì mô hình chỉ còn lại một phương án đó là Playground vì nó có xác suất là 0.4. Nếu như tôi chỉnhTop P = 0.7thì mô hình sẽ có hai phương án đó chính là Playground và School. Như vậy thông sốTop Psẽ cho bạn biết kích thước không gian chọn token của mô hình. - Sau khi chỉnh xong thông số
Top Pthì người ta sẽ để ý đến thông sốTemperature. Để cho dễ nhớ, bạn hãy tưởng tượng như này. NếuTemperature(nhiệt độ) càng cao thì càng nóng, mà càng nóng thì sẽ khiến các token “mềm” đi (nóng chảy). Các token mềm đi tức là các token sẽ có xác suất gần bằng nhau hơn. Ví dụ nhưTop P = 0.7thì như ta nói ở trên, mô hình sẽ chỉ có hai phương án làPlayground = 0.4vàSchool = 0.3. Nếu ta đểTemperaturecao thì xác suất của hai token này sẽ tiến gần với nhau,Playground = 0.35vàSchool = 0.35. - Oke chơi vậy là đủ rồi ! Giờ hãy quay lại với
API. Giờ hãy vào phầnAPI Keysvà chọnCreate new secret keyrồi copy lại giá trịAPI:
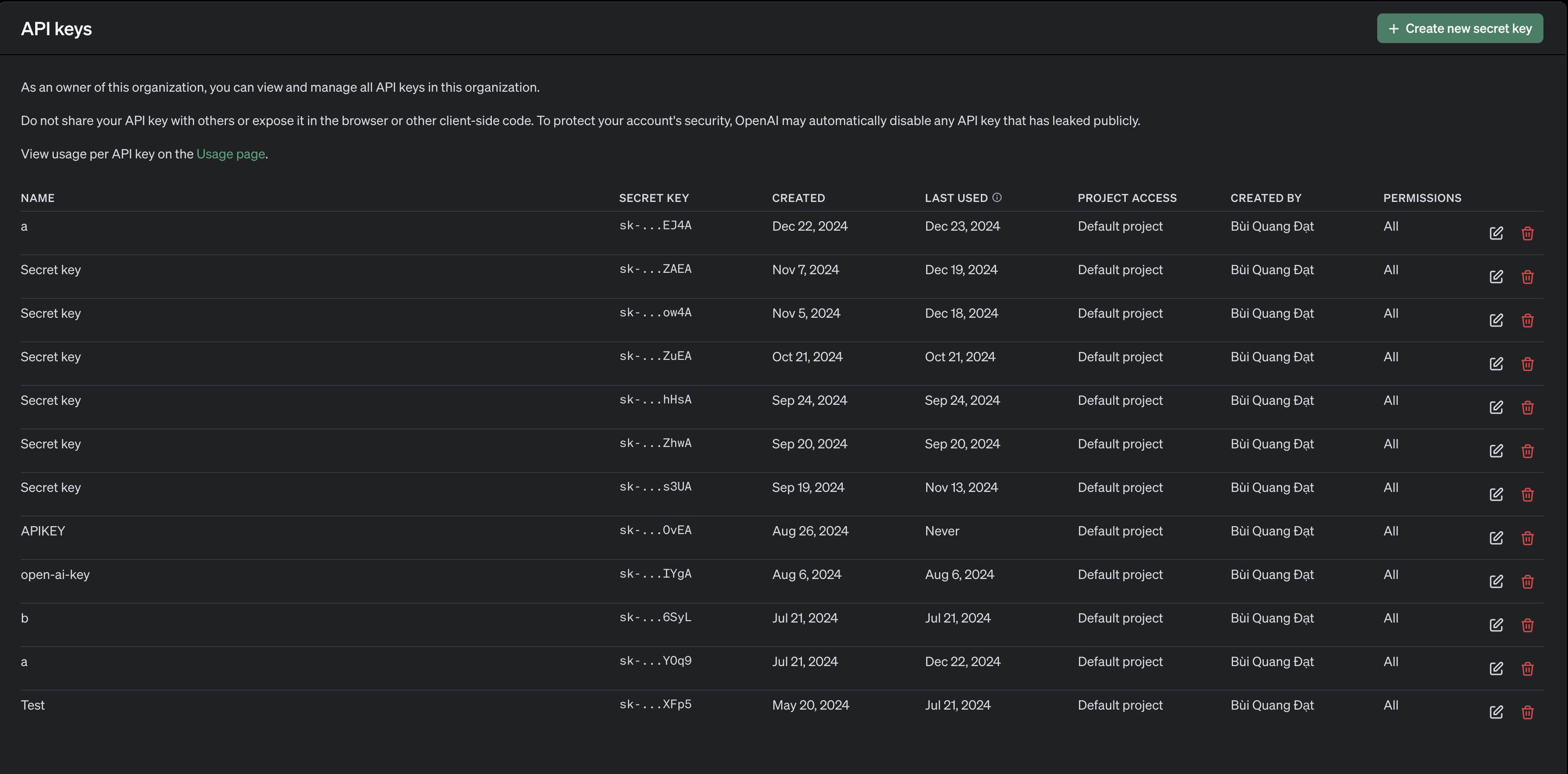
📝 Note: API là giá trị vô cùng nhạy cảm, hãy chắc chắn rằng người khác không biết API của bạn. Vì bạn sẽ không thể kiểm soát được nếu giá trị ấy bị lộ ra ngoài. Thử tượng tưởng 1000 người sử dụng API của bạn, bạn sẽ hết tiền nhanh chóng. Thậm chí không thể đẩy API lên Github, Github sẽ cảnh cáo tài khoản của bạn.
- Hãy lưu trữ giá trị này ở nơi an toàn. Bạn có thể
exportgiá trị này như một biến môi trường bằng lệnh sau ở terminal. Nếu bạn dùng Window thì gõ lệnh sau:
1
setx OPENAI_API_KEY "your_api_key_here"
- Nếu bạn dùng macOS/Linux:
1
export OPENAI_API_KEY="your_api_key_here"
- Một cách khác để lưu biến môi trường ảo đó là hãy tạo ra một file có tên là
.envvà ghi vào file ý (bạn phải sử dùng thư việndotenvđể load biến môi trường, có thể xem ví ở phần sau nữa):
1
OPENAI_API_KEY="your_api_key_here"
- Để sử dụng
OpenAI APItrong python, hãy đảm bảo bạn đã tạo môi trường ảo và tải thư việnopenai:
1
pip install openai
- Giờ hãy lập trình chương trình đầu tiên của bạn sử dụng
OpenAI API:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "developer", "content": "You are a helpful assistant."},
{
"role": "user",
"content": "Write a haiku about recursion in programming."
}
]
)
print(completion.choices[0].message.content)
Code calls to itself,
Layers unfold endlessly—
Elegance in loops.
- Lưu ý là nếu như bạn tạo file
.envvà ghi giá trịOPENAI_API_KEYtrong file đó thay vì sử dụng lệnh trên terminal thì bạn phải code như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from openai import OpenAI
from dotenv import load_dotenv
import os
# Nạp biến từ file .env
load_dotenv()
# Lấy giá trị API key từ biến môi trường
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key = OPENAI_API_KEY)
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "developer", "content": "You are a helpful assistant."},
{
"role": "user",
"content": "Write a haiku about recursion in programming."
}
]
)
print(completion.choices[0].message.content)
- Khi gọi
APIvề văn bản, tham số đầu tiên bạn cần quan tâm chính làmodel. Mô hình bạn chọn có thể ảnh hưởng lớn đến đầu ra và tác động đến chi phí của mỗirequest:- Mô hình lớn như
gpt-4ocung cấp mức độ thông minh rất cao và hiệu suất mạnh mẽ, nhưng có chi phí cao hơn cho mỗi token. - Mô hình nhỏ như
gpt-40-minicó trí thông minh không đạt mức của mô hình lớn hơn, nhưng nó nhanh hơn và ít tốn kém hơn cho mỗi token. - Mô hình lý luận như
o1chậm hơn trong việc đưa ra kết quả và sử dụng nhiều token hơn để “suy nghĩ”, nhưng có khả năng lý luận nâng cao, lập trình, và lập kế hoạch nhiều bước.
- Mô hình lớn như
- Tham số tiếp theo bạn cần quan tâm đó là
messages, tham số này là mộtlistcác từ điển. Bạn có thể tưởng tượng một từ điển chính là một lời tin nhắn. Trong từ điển này có hai giá trị khóa làrolevàcontent. - Cho tới phiên bản
openaikhi tôi đang viết blog này thì tham sốrolesẽ có ba giá trị là:user,developer,assistant. Giá trịusertức là bên phía người dùng gửi tin nhắn, tin nhắn sẽ được lưu vào trong biếncontent. Hãy xem ví dụ ở dưới đây:
1
2
3
4
5
6
7
8
9
10
11
12
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": "Hello! How are you ?"
}
]
)
print(completion.choices[0].message.content)
Hello! I’m just a computer program, so I don’t have feelings, but I’m here to help you. How can I assist you today?
- Tham số
rolekhi có giá trị làassistanttức là tin nhắn phía bên chatbot. Tại sao lại có giá trị này ? Chẳng phải mình chỉ cần gửi tin nhắn bên người dùng thôi sao ? Hãy xem ví dụ dưới đây, khi chỉ có mọt tin nhắn bên người dùng:
1
2
3
4
5
6
7
8
9
10
11
12
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": "Say my name 3 times"
}
]
)
print(completion.choices[0].message.content)
I’m here to help, but I need to respect your privacy, so I don’t have access to your name. If you’d like, feel free to share it, and I can incorporate it into our interaction.
- Giờ hãy thêm hai tin nhắn giữa người dùng và chatbot vào phía trước câu đề nghị: “Say my name 3 times” như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{ "role": "user",
"content": "My name is Dat"
},
{
"role": "assistant",
"content": "Hello Dat"
},
{
"role": "user",
"content": "Say my name 3 times"
}
]
)
print(completion.choices[0].message.content)
Dat, Dat, Dat
- Như bạn thấy, giá trị
assistantsẽ là tin nhắn bên phía chatbot, mục đích chính là giúp chatbot có được các thông tin từ cuộc hội thoại trong quá khứ. - Tham số
rolecòn có thể nhận giá trịdeveloper. Tưởng tượng đơn giản là bạn muốn chatbot trả lời như thế nào, theo cách nào, giống như việc bạn là lập trình viên, code ra con chatbot vậy. Nếu bạn muốn chatbot chỉ trả lời bằng tiếng hàn quốc, bạn có thể code như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{ "role": "developer",
"content": "Only answer in Korean"
},
{
"role": "user",
"content": "Tell me a joke"
}
]
)
print(completion.choices[0].message.content)
왜 스파게티는 컴퓨터를 좋아할까요?
왜냐하면 그들은 이메일을 넣을 수 있어서요!
- Giá trị này rất có ích khi bạn biết các kĩ thuật về
prompt engineering. Bạn có thể xem blogprompt engineeringtrên trang này. - Bạn có thể xem thêm các ví dụ về prompt trong các tác vụ khác nhau tại đây. Một ví dụ khá là thú vị là giả sử bạn muốn chatbot trả lơi chỉ được dùng emoji, bạn có thể code như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "You will be provided with text, and your task is to translate it into emojis. Do not use any regular text. Do your best with emojis only."
},
{
"role": "user",
"content": "Artificial intelligence is a technology with great promise."
}
],
temperature=0.8,
max_tokens=256,
top_p=1
)
print(response.choices[0].message.content)
🤖✨📚🔮
- Để ý rằng bạn cũng có thể chỉnh được các thông số như
temperature,max_tokens,top_pnhư code trên. Ngoài ra, để code được gọn hơn cũng như bảo trì dễ hơn thì người ta hay tạo ra mộtclassriêng cho phầnOpenAInhư sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
from openai import OpenAI
class OpenAIClient():
def __init__(self):
self.client = OpenAI()
def chat(self, messages):
completion = self.client.chat.completions.create(
model="gpt-4o-mini",
messages=messages)
return completion.choices[0].message.content
openAIclient = OpenAIClient()
openAIclient.chat([
{
"role": "user",
"content": "Hello ! Who are you ?"
},
])
import json
def server():
print("Start chatting with the OpenAI API (type 'quit' to stop):")
context = []
while True:
user_input = input("You: ")
if user_input.lower() == 'quit':
break
# Add user input to the context
context.append({"role": "user", "content": user_input})
# Summarize context
# Get response from OpenAI
openai_response = openAIclient.chat(context)
# Add OpenAI response to the context
context.append({"role": "assistant", "content": openai_response})
print(f"AI: {json.dumps(openai_response)}")
server()
API liên quan tới văn bản (kèm hình ảnh)
- Có rất nhiều model
OpenAIcó khả năng nhận diện hình ảnh, nghĩa là bạn có thể gửi request bao gồm cả hình ảnh. Hãy nhìn hình ảnh dưới đây:

- Giờ chúng ta hãy thử hỏi model về hình ảnh này bằng đoạn code như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What's in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0].message.content)
The image depicts a scenic outdoor landscape featuring a wooden pathway or boardwalk that winds through a lush green field with tall grass. In the background, there are trees and bushes, along with a clear blue sky interspersed with clouds. The setting suggests a serene natural environment, likely in a park or nature reserve.
- Nếu bạn có một bức ảnh đuọc lưu cục bộ (local), bạn có thể truyền vào model ảnh ý dưới dạng mã hóa 64, dưới đây là ví dụ:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import base64
from openai import OpenAI
client = OpenAI()
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# Path to your image
image_path = "path_to_your_image.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is in this image?",
},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
},
],
}
],
)
print(response.choices[0].message.content)
- Bạn cũng có thể gửi request gồm nhiều ảnh tới model như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "What are in these images? Is there any difference between them?",
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0].message.content)
API liên quan tới sinh ảnh
- Các model liên quan tới xử lý ảnh bên
OPENAIkhông phải là các model tốt nhất nhưng chúng ta cũng có thể xem qua.APIliên quan tới ảnh củaOpenAIcung cấp cho chúng ta 3 tác vụ chính:- Sinh ảnh dựa vào
prompt(Mô hìnhDALL-E 3vàDALL-E 2) - Tạo ra một ảnh mới được edit bằng cách thay thế một vài vùng trong ảnh dựa vào
prompt(Mô hìnhDALL-E 2) - Tạo ra các phiên bản khác nhau của ảnh gốc (
DALL-E 2)
- Sinh ảnh dựa vào
- Oke, giờ chúng ta hãy thử tác vụ sinh ảnh. Mặc định, hình ảnh sẽ được sinh ở mức tiêu chuẩn (bình thường), nhưng khi bạn sử dụng model
DALL-E 3, bạn có thể đặtquality: "hd"cho chất lượng ảnh tốt hơn. Tất nhiên là ảnh càng chất lượng thì càng phải chờ đợi thời gian lâu để sinh:
1
2
3
4
5
6
7
8
9
10
11
12
from openai import OpenAI
client = OpenAI()
response = client.images.generate(
model="dall-e-3",
prompt="a white siamese cat",
size="1024x1024",
quality="standard",
n=1, # số lượng ảnh
)
print(response.data[0].url)

- Giờ hãy thử sinh ảnh nhưng đặt
quality: "hd":
1
2
3
4
5
6
7
8
9
10
11
12
from openai import OpenAI
client = OpenAI()
response = client.images.generate(
model="dall-e-3",
prompt="a white siamese cat",
size="1024x1024",
quality=hd",
n=1, # số lượng ảnh
)
print(response.data[0].url)

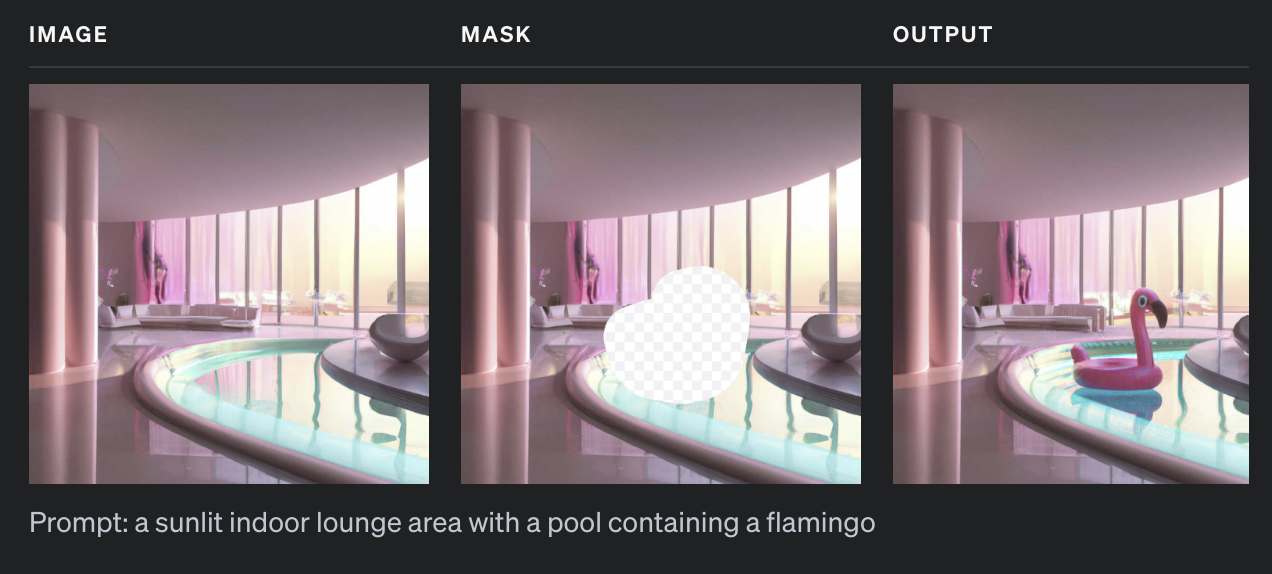
- Tác vụ tiếp theo chúng ta có thể làm là edit ảnh. Trước tiên chúng ta cần phải có hai ảnh, ảnh thứ nhất là ảnh gốc, ảnh thứ hai là ảnh gốc nhưng đã bị khoanh vùng (mask). Sau đó bạn sẽ nhập
promptyêu cầu model sinh ra vùng ảnh ở phần khoanh vùng theo như bạn chỉ định (bạn có thể tải hai ảnh ở code dưới tại đây):
1
2
3
4
5
6
7
8
9
10
11
12
13
from openai import OpenAI
client = OpenAI()
response = client.images.edit(
model="dall-e-2",
image=open("sunlit_lounge.png", "rb"),
mask=open("mask.png", "rb"),
prompt="A sunlit indoor lounge area with a pool containing a flamingo",
n=1,
size="1024x1024",
)
print(response.data[0].url)
- Tác vụ thứ ba đó chính là sinh ra các phiên bản khác nhau của ảnh gốc. Hãy cùng xem qua đoạn code dưới đây:
1
2
3
4
5
6
7
8
9
10
11
from openai import OpenAI
client = OpenAI()
response = client.images.create_variation(
model="dall-e-2",
image=open("corgi_and_cat_paw.png", "rb"),
n=1,
size="1024x1024"
)
print(response.data[0].url)

- Còn rất nhiều thứ hay ho nữa như sinh âm thanh, text to speech, Embediding,… bạn có thể xem trên OpenAI. Vì blog này tập trung vào gọi API liên quan đến văn bản nên tôi sẽ dừng ở đây.
3. Cách sử dụng API bên TogetherAI
Together AIgiống như một “sân chơi chung” dành cho trí tuệ nhân tạo, nơi mọi người có thể sử dụng, chia sẻ và phát triển các công nghệ AI một cách dễ dàng và không bị phụ thuộc vào các công ty lớn. Nó cung cấp các công cụ mạnh mẽ và miễn phí để giúp ai cũng có thể tạo ra hoặc ứng dụng AI, giống như việc mở một kho tài nguyên cho mọi người cùng học và sáng tạo.- Gọi
APIbênTogether AIkhá giống bênOpenAI. Đầu tiên bạn cần phải tải thư việntogether:
1
pip install together
- Tiếp theo chúng ta làm y hệt như bên OpenAI để tạo ra biến môi trường ảo, nhưng lần này, chúng ta sẽ đặt tên biến là
TOGETHER_API_KEY. Như đã nói, bạn có hai cách, cách thứ nhất là gõ lệnh trên terminal, giống hệt như bênOPENAI. Cách thứ hai là tạo ra file.envvà gánTOGETHER_API_KEY = <your api>. Đoạn code dưới đây là cách gọiAPItrongTogetherAI:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from together import Together
client = Together()
response = client.chat.completions.create(
model="meta-llama/Llama-3.3-70B-Instruct-Turbo",
messages=[
{
"role": "user",
"content": "Write a haiku about recursion in programming."
}
],
max_tokens=512,
temperature=0.7,
top_p=0.7,
top_k=50,
repetition_penalty=1,
stop=["<|eot_id|>","<|eom_id|>"],
stream=True
)
for token in response:
if hasattr(token, 'choices'):
print(token.choices[0].delta.content, end='', flush=True)
Functions call within
Echoes of repeating code
4. Cách sử dụng API bên Gemini
Geminilà một bộ công cụ AI tiên tiến được phát triển bởiGoogle, chuyên cung cấp các mô hình học sâu phục vụ nhiều ứng dụng khác nhau, bao gồm xử lý ngôn ngữ tự nhiên, nhận diện hình ảnh, và phân tích dữ liệu. Với khả năng xử lý thông tin mạnh mẽ và chính xác,Geminihỗ trợ các nhà phát triển tích hợp các tính năng AI vào ứng dụng của mình thông quaAPIdễ sử dụng, giúp tăng cường hiệu suất và trải nghiệm người dùng.Geminiđược thiết kế để tối ưu hóa khả năng học máy và cải thiện khả năng tự động hóa trong các ngành công nghiệp khác nhau.- Cách setup
APItôi sẽ không nói nữa, tương tự như các phần ở trên, sử dụng biếnGEMINI_API_KEY. Đầu tiên, bạn sẽ cần phải cài đặt thư việngoogle-generativeai, hãy đảm bảo môi trường ảo của bạn có phiên bảnpython >= 3.9, nếu không thì sẽ xảy ra lỗi khi chạy code:
1
pip install google-generativeai
- Hãy xem đoạn code dưới đây:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import os
import google.generativeai as genai
genai.configure(api_key=os.environ["GEMINI_API_KEY"])
# Create the model
generation_config = {
"temperature": 1,
"top_p": 0.95,
"top_k": 40,
"max_output_tokens": 8192,
"response_mime_type": "text/plain",
}
model = genai.GenerativeModel(
model_name="gemini-2.0-flash-exp",
generation_config=generation_config,
)
chat_session = model.start_chat(
history=[
{
"role": "user",
"parts": [
"Xin chào\n",
],
},
{
"role": "model",
"parts": [
"Chào bạn! Rất vui được trò chuyện với bạn. Bạn có khỏe không? Hôm nay bạn muốn nói về điều gì?\n",
],
},
]
)
response = chat_session.send_message("Who are you ?")
print(response.text)
I am a large language model, trained by Google.
5. Tổng kết.
- Còn rất nhiều các mô hình ngôn ngữ khác ngoài kia như
Claude,DeepSeek,… cũng như rất nhiều mô hình mở trênHugging Facemà bạn có thể gọiAPI. Hy vọng blog này có ích với bạn trên con đường trở thành AI engineer.