Self-Supervised Contrastive Learning Với SimCLR
Trong blog này, chúng ta sẽ học kỹ hơn về self-supervised contrastive learning. Self-supervised learning, đôi khi người ta còn gọi là unsupervised learning, miêu tả kịch bản mà ta chỉ có input data mà không có nhãn để train theo cách học giám sát truyền thống. Tuy nhiên, những data này vẫn chứa rất nhiều thông tin mà chúng ta có thể học: Các hình ảnh khác nhau như thế nào ? Các khuôn mẫu trong các bức ảnh thì sao ? Liệu chúng ta có thể phân cụm các bức ảnh không ?… Cách làm của self-supervised learning là nó sẽ cố gắng học càng nhiều càng tốt từ tập data không có nhãn, để nó có thể dễ dàng finetuned cho các tác vụ phân loại khác. Lợi ích của self-supervised learning là lượng lớn dữ liệu không có nhãn rất dễ để thu nhập. Ví dụ, nếu chúng ta muốn train một model vision trong tác vụ phát hiện vật thể ở ô tô tự động chẳng hạn, chúng ta có thể lắp camera trên ô tô và đi xung quanh thành phố. Nhìn chung, nếu chúng ta muốn làm trên supervised learning, chúng ta phải tốn rất nhiều thời gian để đánh nhãn thủ công, điều này là rất tốn kém. Xa hơn nữa, self-supervised learning có thể cho ta một cách khác thay thế transfer learning từ models đã được huấn luyện trước trên ImageNet vì chúng ta có thể train model từ những data cụ thể.
Chỉ với trỏn vẹn 2 năm, có rất nhiều phương pháp được đưa ra trong self-supervised learning, cụ thể với task vụ liên quan đến hình ảnh, đã có các kết quả rất tốt vượt qua cả mô hình có giám sát khi chỉ có vài nhãn có sẵn. Và một lĩnh vực con chúng ta sẽ đọc trong blog này đó là contrastive learning. Contrastive learning là phương pháp được đề ra dựa trên câu hỏi: Các ảnh khác nhau như thế nào ? Đặc biệt, contrastive learning có thể phân cụm các bức ảnh. Một phương pháp dễ dàng và hiệu quả trong contrastive learning đó là SimCLR, được mô tả ở hình dưới:

Đầu tiên, chúng ta có một tập data hình ảnh không có nhãn, và chúng ta muốn train một model trên tập data này mà nó có thể nhanh chóng đáp ứng bất kỳ nhiệm vụ nhận dạng hình ảnh trong tương lai. Bước đầu tiên trong quá trình train là chúng ta lấy ra một batch các hình ảnh. Với mỗi hình ảnh, chúng ta tạo ra 2 hình ảnh khác bằng cách áp dụng các phương pháp tăng cường dữ liệu như cropping, Gaussian noise, blurring,..etc . Với 2 hình ảnh này, chúng ta áp dụng model CNN như ResNet và thu được output là vector 1D, sau đó chúng ta đưa vector này qua một MLP đơn giản. Hai output của hai hình ảnh này sẽ được train sao cho chúng gần với nhau, trong khi các output của các hình ảnh còn lại phải càng 2 output này càng tốt. Bằng cách này, model có thể học được cách nhận diện nội dung trong bức ảnh bằng cách hiểu những thông tin không bị thay đổi qua các bước tăng cường dữ liệu, ví dụ như vật thể trong ảnh, một thứ mà chúng ta luôn quan tâm trong tác vụ học giám sát.
Chúng ta hãy bắt đầu code thôi ! Đầu tiên cần khai báo các thư viện cần thiết:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
## Standard libraries
import os # Thư viện để tương tác với hệ thống tệp và môi trường
from copy import deepcopy # Thư viện để sao chép sâu các đối tượng
## Imports for plotting
import matplotlib.pyplot as plt # Thư viện để vẽ đồ thị
plt.set_cmap('cividis') # Đặt bảng màu mặc định cho đồ thị
%matplotlib inline # Đảm bảo đồ thị được hiển thị trực tiếp trong notebook
from IPython.display import set_matplotlib_formats # Định dạng đồ thị khi xuất ra file
set_matplotlib_formats('svg', 'pdf') # Xuất đồ thị dưới định dạng SVG và PDF
import matplotlib # Thư viện cài đặt các thuộc tính của đồ thị
matplotlib.rcParams['lines.linewidth'] = 2.0 # Thiết lập độ rộng mặc định cho đường trong đồ thị
import seaborn as sns # Thư viện để vẽ biểu đồ đẹp hơn
sns.set() # Áp dụng cài đặt mặc định của Seaborn
## tqdm for loading bars
from tqdm.notebook import tqdm # Thư viện tạo thanh tiến trình trong notebook
## PyTorch
import torch # Thư viện chính để xây dựng và huấn luyện mô hình deep learning
import torch.nn as nn # Module chứa các lớp cho neural networks
import torch.nn.functional as F # Module chứa các hàm tiện ích cho neural networks
import torch.utils.data as data # Module hỗ trợ làm việc với tập dữ liệu
import torch.optim as optim # Module cho các thuật toán tối ưu
## Torchvision
import torchvision # Thư viện hỗ trợ xử lý dữ liệu hình ảnh
from torchvision.datasets import STL10 # Tập dữ liệu STL10
from torchvision import transforms # Module để thực hiện các phép biến đổi dữ liệu
# PyTorch Lightning
try:
import pytorch_lightning as pl # Framework để quản lý quy trình huấn luyện
except ModuleNotFoundError: # Nếu không cài đặt PyTorch Lightning, cài đặt nó
!pip install --quiet pytorch-lightning>=1.4
import pytorch_lightning as pl
from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint # Callback để giám sát learning rate và lưu mô hình
# Import tensorboard
%load_ext tensorboard # Kích hoạt tensorboard trong notebook
# Path to the folder where the datasets are/should be downloaded (e.g. CIFAR10)
DATASET_PATH = "../data" # Đường dẫn lưu trữ dữ liệu
# Path to the folder where the pretrained models are saved
CHECKPOINT_PATH = "../saved_models/tutorial17" # Đường dẫn lưu trữ mô hình đã huấn luyện
# In this notebook, we use data loaders with heavier computational processing. It is recommended to use as many
# workers as possible in a data loader, which corresponds to the number of CPU cores
NUM_WORKERS = os.cpu_count() # Số lượng worker cho DataLoader tương ứng với số lõi CPU
# Setting the seed
pl.seed_everything(42) # Đặt seed để đảm bảo kết quả có thể tái lập
# Ensure that all operations are deterministic on GPU (if used) for reproducibility
torch.backends.cudnn.deterministic = True # Đảm bảo các phép toán trên GPU có tính xác định
torch.backends.cudnn.benchmark = False # Tắt chế độ benchmark để giảm độ không xác định
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu") # Chọn GPU nếu khả dụng, nếu không thì sử dụng CPU
print("Device:", device) # In ra thiết bị đang sử dụng
print("Number of workers:", NUM_WORKERS) # In ra số worker
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import urllib.request # Thư viện để thực hiện các yêu cầu HTTP, như tải file từ URL
from urllib.error import HTTPError # Lớp ngoại lệ dùng để xử lý lỗi HTTP
# Github URL where saved models are stored for this tutorial
base_url = "https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial17/"
# URL gốc chứa các mô hình đã được huấn luyện sẵn cho tutorial này
# Files to download
pretrained_files = ["SimCLR.ckpt", "ResNet.ckpt",
# Các file checkpoint cho mô hình SimCLR và ResNet
"tensorboards/SimCLR/events.out.tfevents.SimCLR",
"tensorboards/classification/ResNet/events.out.tfevents.ResNet"]
# Các file tensorboard log cho SimCLR và ResNet
pretrained_files += [f"LogisticRegression_{size}.ckpt" for size in [10, 20, 50, 100, 200, 500]]
# Thêm vào danh sách các file checkpoint Logistic Regression tương ứng với kích thước tập huấn luyện
# Create checkpoint path if it doesn't exist yet
os.makedirs(CHECKPOINT_PATH, exist_ok=True)
# Tạo thư mục lưu checkpoint nếu chưa tồn tại
# For each file, check whether it already exists. If not, try downloading it.
for file_name in pretrained_files: # Duyệt qua từng file trong danh sách pretrained_files
file_path = os.path.join(CHECKPOINT_PATH, file_name)
# Xác định đường dẫn đầy đủ nơi file sẽ được lưu
if "/" in file_name:
os.makedirs(file_path.rsplit("/",1)[0], exist_ok=True)
# Nếu đường dẫn file chứa các thư mục con, tạo các thư mục đó nếu chưa tồn tại
if not os.path.isfile(file_path):
# Kiểm tra nếu file chưa tồn tại tại đường dẫn chỉ định
file_url = base_url + file_name
# Tạo URL đầy đủ của file bằng cách ghép base_url và tên file
print(f"Downloading {file_url}...")
# Thông báo quá trình tải file
try:
urllib.request.urlretrieve(file_url, file_path)
# Tải file từ URL và lưu tại đường dẫn chỉ định
except HTTPError as e:
# Xử lý lỗi HTTP nếu quá trình tải gặp sự cố
print("Something went wrong. Please try to download the file from the GDrive folder, or contact the author with the full output including the following error:\n", e)
# In ra thông báo lỗi và hướng dẫn thêm
1. SimCLR
- Chúng ta sẽ bắt đầu khám phá contrastive learning bằng cách thảo luận các ảnh hưởng của từng cách tăng cường dữ liệu khác nhau. Tiếp theo, chúng ta sẽ code SimCLR bằng PyTorch Lightning và cuối cùng là train nó trên tập dữ liệu lớn, không được gán nhãn.
Data Augmentation for Contrastive Learning
- Để huấn luyện một cách hiệu quả, chúng ta cần phải chuẩn bị dữ liệu bằng cách sample ngẫu nhiên tăng cường dữ liệu lên mỗi ảnh trong batch. Cách dễ nhất là tạo ra một class transformation, khi class ý được gọi, nó sẽ áp dụng một tập tăng cường dữ liệu lên ảnh 2 lần. Code ở dưới đây:
1
2
3
4
5
6
7
8
class ContrastiveTransformations(object):
def __init__(self, base_transforms, n_views=2):
self.base_transforms = base_transforms
self.n_views = n_views
def __call__(self, x):
return [self.base_transforms(x) for i in range(self.n_views)]
- Chúng ta có thể mở rộng lên, muốn có nhiều positive examples hơn thì có thể áp dụng nhiều hơn các cách tăng cường dữ liệu thay vì chỉ có 2. Nhưng cách huấn luyện hiệu quả nhất thì thường chỉ cần 2 cách tăng cường dữ liệu thôi.
- Tiếp theo, chúng ta hãy xe các cách tằng cường dữ liệu cụ thể. Chọn cách nào để tăng cường dữ liệu là một việc rất quan trọng trong SimCLR vì nó ảnh hưởng trực tiếp đến cấu trúc không gian tiềm ẩn trong ảnh, cũng như các khuôn mẫu có trong ảnh. Ảnh dưới đây bao gồm các cách tăng cường dữ liệu phổ biến trong ảnh:

- Tất cả các cách trên đều có thể được sử dụng, nhưng có hai cách nổi bật hơn cả đó chính là: crop-and-resize và color distortion. Điều thú vị là hai cách này thực sự có hiệu quả khi bọn chúng được sử dụng cùng với nhau. Khi thực hiện randomly cropping và resizing, chúng ta nhận ra có hai trường hợp khá rõ ràng như ảnh dưới: Ảnh (a) biểu thị resizing, tức là ảnh chỉ co lại hoặc lớn lên, không làm mất nhiều thông tin về ảnh. Còn ảnh (b) thì là bị cropping, tức là ảnh sẽ mất đi rất nhiều thông tin:
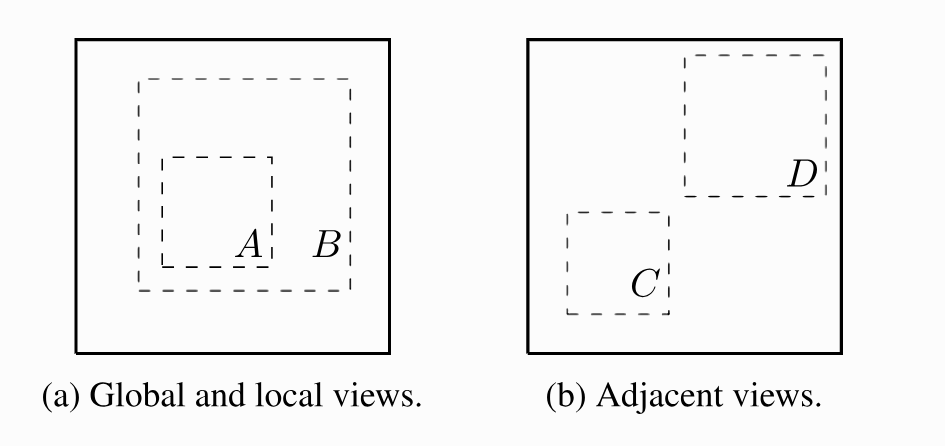
- Trong khi tình huống (a) yêu cầu mô hình học một dạng bất biến về tỷ lệ để làm cho các vùng cắt A và B trở nên giống nhau trong không gian tiềm ẩn, thì tình huống (b) khó khăn hơn vì mô hình cần nhận diện một đối tượng vượt ra khỏi tầm nhìn hạn chế của nó. Tuy nhiên, nếu không có color distortion, mô hình có thể khai thác một lỗ hổng, cụ thể là các vùng cắt khác nhau của cùng một hình ảnh thường trông rất giống nhau về không gian màu sắc.
- Hãy xem xét hình ảnh chú chó ở trên. Chỉ từ màu sắc của bộ lông và tông màu xanh lá của nền, bạn có thể suy luận rằng hai phần này thuộc về cùng một hình ảnh mà không thực sự nhận diện chú chó trong bức ảnh. Trong trường hợp này, mô hình có thể chỉ tập trung vào các biểu đồ màu sắc của hình ảnh và bỏ qua các đặc trưng mang tính tổng quát hơn. Tuy nhiên, nếu chúng ta làm biến đổi màu sắc của hai vùng cắt một cách ngẫu nhiên và độc lập với nhau, mô hình không thể dựa vào đặc trưng đơn giản này nữa. Do đó, bằng cách kết hợp việc cắt ngẫu nhiên và biến đổi màu sắc, mô hình chỉ có thể so khớp hai vùng cắt bằng cách học các biểu diễn mang tính tổng quát.
Tổng quan, trong các thí nghiệm của chúng ta, chúng ta sẽ áp dụng một tập hợp gồm 5 phép biến đổi theo thiết lập gốc của SimCLR: random horizontal flip, crop-and-resize, color distortion, random grayscale, and gaussian blur. So với triển khai gốc, chúng tôi giảm nhẹ hiệu ứng của sự thay đổi màu sắc (color jitter) một chút (0.5 thay vì 0.8 cho brightness, contrast và saturation, và 0.1 thay vì 0.2 cho hue).
- Trong các thí nghiệm của chúng ta, thiết lập này mang lại hiệu suất tốt hơn, đồng thời nhanh hơn và ổn định hơn trong quá trình huấn luyện. Ví dụ, nếu phạm vi thay đổi độ sáng trong tập dữ liệu rất lớn, các thiết lập gốc có thể mang lại lợi ích hơn vì mô hình sẽ không thể dựa vào thông tin này để phân biệt giữa các hình ảnh.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
contrast_transforms = transforms.Compose([ # Kết hợp nhiều phép biến đổi dữ liệu để áp dụng liên tiếp
transforms.RandomHorizontalFlip(), # Lật ngang hình ảnh ngẫu nhiên với xác suất 50%
transforms.RandomResizedCrop(size=96), # Cắt ngẫu nhiên một vùng trong hình ảnh và thay đổi kích thước vùng này về 96x96
transforms.RandomApply([ # Áp dụng danh sách phép biến đổi bên trong với xác suất nhất định
transforms.ColorJitter( # Biến đổi màu sắc bằng cách thay đổi độ sáng, độ tương phản, độ bão hòa và sắc độ
brightness=0.5, # Độ sáng thay đổi ngẫu nhiên trong khoảng ±50%
contrast=0.5, # Độ tương phản thay đổi ngẫu nhiên trong khoảng ±50%
saturation=0.5, # Độ bão hòa thay đổi ngẫu nhiên trong khoảng ±50%
hue=0.1 # Sắc độ thay đổi ngẫu nhiên trong khoảng ±10%
)
], p=0.8), # Áp dụng phép ColorJitter với xác suất 80%
transforms.RandomGrayscale(p=0.2), # Chuyển đổi hình ảnh sang thang độ xám ngẫu nhiên với xác suất 20%
transforms.GaussianBlur(kernel_size=9), # Làm mờ hình ảnh bằng bộ lọc Gaussian với kích thước kernel 9x9
transforms.ToTensor(), # Chuyển đổi hình ảnh từ định dạng PIL hoặc NumPy thành tensor PyTorch
transforms.Normalize((0.5,), (0.5,)) # Chuẩn hóa giá trị pixel về phạm vi [-1, 1] với trung bình 0.5 và độ lệch chuẩn 0.5
])
- Sau khi thảo luận về các kỹ thuật tăng cường dữ liệu, giờ chúng ta có thể tập trung vào tập dữ liệu. Trong blog này, chúng ta sẽ sử dụng tập dữ liệu
STL10, tương tự nhưCIFAR10, chứa hình ảnh của 10 lớp: máy bay, chim, ô tô, mèo, hươu, chó, ngựa, khỉ, tàu, và xe tải. Tuy nhiên, các hình ảnh có độ phân giải cao hơn, cụ thể là 96×96 pixel, và chỉ có 500 hình ảnh được gán nhãn cho mỗi lớp.Ngoài ra, tập dữ liệu còn có một tập lớn hơn với 100,000 hình ảnh không gán nhãn, tương tự như các hình ảnh huấn luyện nhưng được lấy mẫu từ nhiều loại động vật và phương tiện khác nhau. Điều này khiến tập dữ liệu trở nên lý tưởng để minh họa những lợi ích mà học tự giám sát mang lại. - May mắn thay, tập dữ liệu STL10 được cung cấp thông qua thư viện torchvision. Tuy nhiên, hãy lưu ý rằng vì tập dữ liệu này tương đối lớn và có độ phân giải cao hơn đáng kể so với CIFAR10, nên nó yêu cầu nhiều dung lượng lưu trữ hơn (~3GB) và sẽ mất một chút thời gian để tải xuống. Để bắt đầu tìm hiểu về học tự giám sát và SimCLR, chúng ta sẽ tạo hai bộ tải dữ liệu (data loaders) với các phép biến đổi tương phản đã đề cập ở trên:
unlabeled_datasẽ được sử dụng để huấn luyện mô hình bằng phương pháp học tương phản, vàtrain_data_contrastsẽ được sử dụng làm tập kiểm tra trong quá trình học tương phản.
1
2
3
4
unlabeled_data = STL10(root=DATASET_PATH, split='unlabeled', download=True,
transform=ContrastiveTransformations(contrast_transforms, n_views=2))
train_data_contrast = STL10(root=DATASET_PATH, split='train', download=True,
transform=ContrastiveTransformations(contrast_transforms, n_views=2))
- Cuối cùng, trước khi bắt đầu triển khai SimCLR, hãy xem một số cặp hình ảnh mẫu được tạo ra với các phép tăng cường dữ liệu của chúng ta:
1
2
3
4
5
6
7
8
9
10
11
12
13
# Visualize some examples
pl.seed_everything(42)
NUM_IMAGES = 6
imgs = torch.stack([img for idx in range(NUM_IMAGES) for img in unlabeled_data[idx][0]], dim=0)
img_grid = torchvision.utils.make_grid(imgs, nrow=6, normalize=True, pad_value=0.9)
img_grid = img_grid.permute(1, 2, 0)
plt.figure(figsize=(10,5))
plt.title('Augmented image examples of the STL10 dataset')
plt.imshow(img_grid)
plt.axis('off')
plt.show()
plt.close()
SimCLR implementation
- Sử dụng pipeline bộ tải dữ liệu đã trình bày ở trên, giờ đây chúng ta có thể triển khai SimCLR. Trong mỗi lần lặp, đối với mỗi hình ảnh $x$, chúng ta tạo ra hai phiên bản được tăng cường khác nhau, gọi là $\tilde{x}_i$ và $\tilde{x}_j$. Cả hai hình ảnh này được mã hóa thành một vector đặc trưng một chiều, giữa chúng ta muốn tối đa hóa sự tương đồng, đồng thời giảm thiểu sự tương đồng với tất cả các hình ảnh khác trong batch.
- Mạng mã hóa được chia thành hai phần: một mạng mã hóa cơ bản $f(.)$ và một đầu chiếu $g(.)$. Mạng mã hóa cơ bản thường là một mạng CNN sâu, như chúng ta đã thấy ở blog trước, và chịu trách nhiệm trích xuất một vector biểu diễn từ các ví dụ dữ liệu đã được tăng cường. Trong thí nghiệm của chúng ta, chúng ta sẽ sử dụng kiến trúc ResNet-18 phổ biến làm $f(.)$, và đầu ra được ký hiệu là $f(\tilde{x}_i) = h_i$.
- Đầu chiếu $g(.)$ ánh xạ biểu diễn $h$ vào một không gian nơi chúng ta áp dụng hàm mất mát tương phản, tức là, so sánh sự tương đồng giữa các vector. Nó thường được chọn là một mạng MLP nhỏ với phi tuyến tính, và để đơn giản, chúng ta tuân theo thiết lập từ bài báo gốc của SimCLR bằng cách định nghĩa nó là một MLP hai lớp với hàm kích hoạt ReLU ở lớp ẩn. Lưu ý rằng trong bài báo tiếp theo, SimCLRv2, các tác giả đề cập rằng các MLP lớn hơn/rộng hơn có thể tăng hiệu suất đáng kể. Đây là lý do tại sao chúng ta áp dụng một MLP với kích thước ẩn lớn hơn bốn lần, nhưng các MLP sâu hơn thường bị overfit trên tập dữ liệu đã cho. Thiết lập tổng quan được minh họa bên dưới:

- Sau khi hoàn thành giai đoạn huấn luyện với phương pháp học tương phản (contrastive learning), chúng ta sẽ loại bỏ đầu chiếu $g(.)$ và sử dụng $f(.)$ làm bộ trích xuất đặc trưng đã được huấn luyện trước. Các biểu diễn $z$ ược tạo ra từ đầu chiếu $g(.)$ đã được chứng minh là hoạt động kém hơn so với các biểu diễn của mạng cơ bản $f(.)$ khi tinh chỉnh mạng cho một tác vụ mới. Điều này có khả năng xảy ra do các biểu diễn $z$ được huấn luyện để trở nên bất biến với nhiều đặc trưng, chẳng hạn như màu sắc, điều có thể quan trọng đối với các tác vụ phía sau. Do đó, $g(.)$ chỉ cần thiết trong giai đoạn học tương phản.
- Bây giờ, sau khi kiến trúc đã được mô tả, hãy cùng xem xét kỹ hơn cách chúng ta huấn luyện mô hình. Như đã đề cập trước đó, chúng ta muốn tối đa hóa sự tương đồng giữa các biểu diễn của hai phiên bản được tăng cường từ cùng một hình ảnh, tức là $z_i$ và $z_j$ như trong hình minh họa phía trên, đồng thời giảm thiểu sự tương đồng với tất cả các ví dụ khác trong batch. SimCLR sử dụng hàm mất mát InfoNCE, được đề xuất ban đầu bởi Aaron van den Oord và cộng sự, để học tương phản. Nói ngắn gọn, hàm mất mát InfoNCE so sánh sự tương đồng giữa $z_i$ và $z_j$ với sự tương đồng giữa $z_i$ và bất kỳ biểu diễn nào khác trong batch bằng cách thực hiện một phép tính softmax trên các giá trị tương đồng. Hàm mất mát có thể được viết chính thức như sau:
- Giờ chúng ta hãy lập trình hàm class SimCLR bằng Pytorch Lightning:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
class SimCLR(pl.LightningModule): # Định nghĩa một class PyTorch Lightning Module tên SimCLR.
def __init__(self, hidden_dim, lr, temperature, weight_decay, max_epochs=500):
super().__init__() # Gọi hàm khởi tạo của lớp cha (LightningModule).
self.save_hyperparameters() # Lưu lại các tham số vào hparams để sử dụng sau.
assert self.hparams.temperature > 0.0, 'The temperature must be a positive float!' # Kiểm tra giá trị temperature hợp lệ.
# Base model f(.)
# Sử dụng ResNet-18 làm mô hình cơ bản với đầu ra của lớp cuối cùng là 4 * hidden_dim.
self.convnet = torchvision.models.resnet18(num_classes=4*hidden_dim)
# The MLP for g(.) consists of Linear->ReLU->Linear
# Tái định nghĩa lớp fully-connected (fc) của ResNet với cấu trúc MLP Linear -> ReLU -> Linear.
self.convnet.fc = nn.Sequential(
self.convnet.fc, # Giữ nguyên lớp fully-connected cũ.
nn.ReLU(inplace=True), # Thêm hàm kích hoạt ReLU.
nn.Linear(4*hidden_dim, hidden_dim) # Thêm lớp Linear để giảm chiều từ 4*hidden_dim xuống hidden_dim.
)
def configure_optimizers(self):
# Khởi tạo optimizer AdamW với learning rate và weight decay được lấy từ hparams.
optimizer = optim.AdamW(self.parameters(),
lr=self.hparams.lr,
weight_decay=self.hparams.weight_decay)
# Khởi tạo scheduler với cosine annealing để giảm learning rate dần về eta_min.
lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer,
T_max=self.hparams.max_epochs,
eta_min=self.hparams.lr/50)
# Trả về optimizer và scheduler.
return [optimizer], [lr_scheduler]
def info_nce_loss(self, batch, mode='train'): # Hàm tính loss InfoNCE.
imgs, _ = batch # Lấy ảnh từ batch (bỏ qua label).
imgs = torch.cat(imgs, dim=0) # Kết hợp các augmentations của ảnh vào cùng một batch.
# Encode all images
feats = self.convnet(imgs) # Tính đặc trưng (feature) cho tất cả các ảnh.
# Calculate cosine similarity
# Tính độ tương đồng cosine giữa các vector đặc trưng.
cos_sim = F.cosine_similarity(feats[:,None,:], feats[None,:,:], dim=-1)
# Mask out cosine similarity to itself
# Loại bỏ độ tương đồng của vector với chính nó bằng cách gán giá trị -9e15.
self_mask = torch.eye(cos_sim.shape[0], dtype=torch.bool, device=cos_sim.device)
cos_sim.masked_fill_(self_mask, -9e15)
# Find positive example -> batch_size//2 away from the original example
# Tìm cặp ảnh dương cách ảnh gốc một khoảng batch_size//2.
pos_mask = self_mask.roll(shifts=cos_sim.shape[0]//2, dims=0)
# InfoNCE loss
# Tính loss InfoNCE: âm log-likelihood của ví dụ dương.
cos_sim = cos_sim / self.hparams.temperature # Chuẩn hóa cosine similarity theo temperature.
nll = -cos_sim[pos_mask] + torch.logsumexp(cos_sim, dim=-1) # Tính negative log likelihood.
nll = nll.mean() # Lấy giá trị trung bình.
# Logging loss
self.log(mode+'_loss', nll) # Log giá trị loss theo mode (train/val).
# Get ranking position of positive example
# Tính thứ hạng của ví dụ dương.
comb_sim = torch.cat([cos_sim[pos_mask][:,None], # Ghép giá trị của ví dụ dương vào đầu.
cos_sim.masked_fill(pos_mask, -9e15)], # Loại trừ giá trị dương khỏi cosine similarity.
dim=-1)
sim_argsort = comb_sim.argsort(dim=-1, descending=True).argmin(dim=-1) # Tìm thứ hạng của ví dụ dương.
# Logging ranking metrics
# Log các chỉ số xếp hạng.
self.log(mode+'_acc_top1', (sim_argsort == 0).float().mean()) # Tỉ lệ xếp hạng 1.
self.log(mode+'_acc_top5', (sim_argsort < 5).float().mean()) # Tỉ lệ nằm trong top 5.
self.log(mode+'_acc_mean_pos', 1+sim_argsort.float().mean()) # Vị trí trung bình của ví dụ dương.
return nll # Trả về giá trị loss.
def training_step(self, batch, batch_idx): # Hàm định nghĩa bước huấn luyện.
return self.info_nce_loss(batch, mode='train') # Tính InfoNCE loss cho batch huấn luyện.
def validation_step(self, batch, batch_idx): # Hàm định nghĩa bước validation.
self.info_nce_loss(batch, mode='val') # Tính InfoNCE loss cho batch validation.
- Thay vì thực hiện quá trình xác thực (validation) dựa trên hàm loss của học tương phản (contrastive learning) như đã làm, chúng ta cũng có thể sử dụng một tác vụ downstream đơn giản và nhỏ gọn để theo dõi hiệu suất của mạng cơ bản $f(.)$ trên tác vụ đó. Tuy nhiên, trong blog này, chúng ta sẽ giới hạn trong bộ dữ liệu STL10, nơi mà chúng ta sử dụng tác vụ phân loại ảnh trên STL10 làm tác vụ kiểm tra của mình.
Training
- Bây giờ, sau khi đã triển khai SimCLR và pipeline tải dữ liệu, chúng ta sẵn sàng để huấn luyện mô hình. Chúng ta sẽ sử dụng cấu hình hàm huấn luyện tương tự như thông thường. Để lưu checkpoint của mô hình tốt nhất, chúng ta sẽ theo dõi chỉ số
val_acc_top5, chỉ số này mô tả tần suất mà ảnh đúng nằm trong top-5 các ví dụ tương đồng nhất trong batch. Chỉ số này thường ít nhiễu hơn so với chỉ số top-1, khiến nó trở thành lựa chọn tốt hơn để xác định mô hình tốt nhất.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
def train_simclr(batch_size, max_epochs=500, **kwargs): # Định nghĩa hàm huấn luyện SimCLR với tham số batch_size, max_epochs, và các tham số khác truyền vào bằng kwargs.
# Khởi tạo trainer của PyTorch Lightning với các tham số cơ bản.
trainer = pl.Trainer(
default_root_dir=os.path.join(CHECKPOINT_PATH, 'SimCLR'), # Đường dẫn lưu các checkpoint của mô hình.
accelerator="gpu" if str(device).startswith("cuda") else "cpu", # Sử dụng GPU nếu khả dụng, nếu không thì sử dụng CPU.
devices=1, # Sử dụng 1 GPU hoặc 1 CPU.
max_epochs=max_epochs, # Số epoch tối đa để huấn luyện.
callbacks=[
ModelCheckpoint(save_weights_only=True, mode='max', monitor='val_acc_top5'), # Callback để lưu checkpoint dựa trên chỉ số `val_acc_top5`.
LearningRateMonitor('epoch') # Callback để theo dõi learning rate trong từng epoch.
]
)
trainer.logger._default_hp_metric = None # Tắt ghi log mặc định của hyperparameter metric.
# Kiểm tra xem mô hình đã được huấn luyện trước đó chưa. Nếu có, tải mô hình và bỏ qua bước huấn luyện.
pretrained_filename = os.path.join(CHECKPOINT_PATH, 'SimCLR.ckpt') # Đường dẫn tới file checkpoint của mô hình đã huấn luyện.
if os.path.isfile(pretrained_filename): # Kiểm tra xem file checkpoint có tồn tại không.
print(f'Found pretrained model at {pretrained_filename}, loading...') # In thông báo đã tìm thấy mô hình.
model = SimCLR.load_from_checkpoint(pretrained_filename) # Tải mô hình từ file checkpoint (tự động tải các hyperparameter đã lưu).
else:
# Nếu chưa có mô hình, tạo dataloader cho tập dữ liệu huấn luyện không gán nhãn và tập validation.
train_loader = data.DataLoader(
unlabeled_data, # Dữ liệu không gán nhãn để huấn luyện.
batch_size=batch_size, # Kích thước batch.
shuffle=True, # Shuffle dữ liệu trong mỗi epoch.
drop_last=True, # Bỏ các batch cuối nếu không đủ kích thước batch.
pin_memory=True, # Tăng hiệu suất khi sử dụng GPU.
num_workers=NUM_WORKERS # Số luồng worker để tải dữ liệu.
)
val_loader = data.DataLoader(
train_data_contrast, # Dữ liệu để validation.
batch_size=batch_size, # Kích thước batch.
shuffle=False, # Không shuffle trong quá trình validation.
drop_last=False, # Không bỏ các batch cuối trong validation.
pin_memory=True, # Tăng hiệu suất khi sử dụng GPU.
num_workers=NUM_WORKERS # Số luồng worker để tải dữ liệu.
)
pl.seed_everything(42) # Đặt seed để đảm bảo kết quả có thể tái tạo.
model = SimCLR(max_epochs=max_epochs, **kwargs) # Khởi tạo mô hình SimCLR với các tham số đã truyền vào.
trainer.fit(model, train_loader, val_loader) # Huấn luyện mô hình với dataloader huấn luyện và validation.
model = SimCLR.load_from_checkpoint(trainer.checkpoint_callback.best_model_path) # Tải checkpoint tốt nhất sau khi huấn luyện.
return model # Trả về mô hình đã huấn luyện.
- Một quan sát phổ biến trong học tương phản là kích thước batch càng lớn thì mô hình hoạt động càng tốt. Kích thước batch lớn hơn cho phép so sánh mỗi ảnh với nhiều ví dụ âm hơn, từ đó dẫn đến gradient loss mượt mà hơn. Tuy nhiên, trong trường hợp của chúng tôi, chúng tôi nhận thấy rằng kích thước batch 256 là đủ để đạt được kết quả tốt.
1
2
3
4
5
6
simclr_model = train_simclr(batch_size=256,
hidden_dim=128,
lr=5e-4,
temperature=0.07,
weight_decay=1e-4,
max_epochs=500)
- Để có trực giác về cách huấn luyện với học tương phản hoạt động, chúng ta có thể xem xét TensorBoard bên dưới:
1
%tensorboard --logdir ../saved_models/tutorial17/tensorboards/SimCLR/
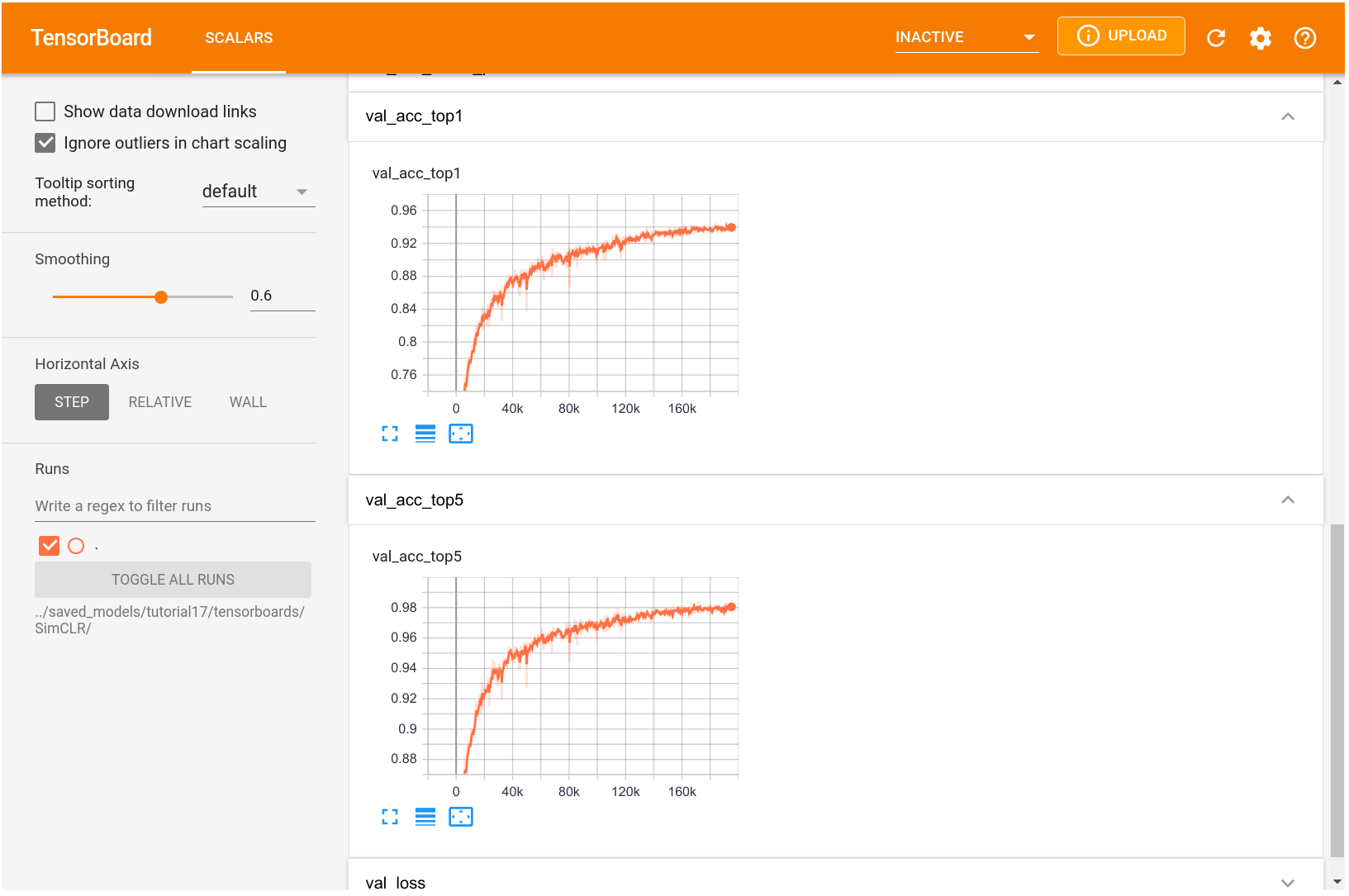
- Một điều cần lưu ý là học tương phản hưởng lợi rất nhiều từ quá trình huấn luyện dài. Biểu đồ được hiển thị ở trên là từ một quá trình huấn luyện kéo dài khoảng 1 ngày trên NVIDIA TitanRTX. Việc huấn luyện mô hình lâu hơn có thể tiếp tục giảm loss, nhưng chúng ta không nhận thấy bất kỳ cải thiện nào cho tác vụ downstream là phân loại ảnh. Nhìn chung, học tương phản cũng có thể hưởng lợi từ việc sử dụng các mô hình lớn hơn nếu có đủ dữ liệu không gán nhãn.
Logistic
Sau khi đã huấn luyện mô hình thông qua học tương phản, chúng ta có thể triển khai nó cho các tác vụ downstream và xem nó hoạt động tốt như thế nào với lượng dữ liệu ít. Một thiết lập phổ biến, cũng giúp xác minh liệu mô hình đã học được các biểu diễn tổng quát hay chưa, là thực hiện hồi quy logistic trên các đặc trưng. Nói cách khác, chúng ta sẽ học một lớp tuyến tính duy nhất để ánh xạ các biểu diễn vào dự đoán lớp. Vì mạng cơ bản không thay đổi trong quá trình huấn luyện, mô hình chỉ có thể hoạt động tốt nếu các biểu diễn này mô tả đầy đủ tất cả các đặc điểm có thể cần thiết cho tác vụ. Hơn nữa, chúng ta không phải lo lắng quá nhiều về việc overfitting vì có rất ít tham số được huấn luyện. Do đó, chúng ta có thể kỳ vọng mô hình hoạt động tốt ngay cả khi chỉ có rất ít dữ liệu.
Đầu tiên, chúng ta hãy triển khai một thiết lập hồi quy logistic đơn giản, trong đó chúng ta giả định rằng các ảnh đã được mã hóa thành các vector đặc trưng. Nếu chỉ có rất ít dữ liệu, việc mã hóa động các ảnh trong quá trình huấn luyện có thể có lợi, vì như vậy chúng ta có thể áp dụng các biến thể dữ liệu. Tuy nhiên, cách triển khai ở đây hiệu quả hơn nhiều và có thể được huấn luyện trong vài giây. Hơn nữa, việc sử dụng biến thể dữ liệu không cho thấy sự cải thiện đáng kể trong thiết lập đơn giản này.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
class LogisticRegression(pl.LightningModule):
def __init__(self, feature_dim, num_classes, lr, weight_decay, max_epochs=100):
super().__init__()
self.save_hyperparameters()
# Mapping from representation h to classes
self.model = nn.Linear(feature_dim, num_classes)
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(),
lr=self.hparams.lr,
weight_decay=self.hparams.weight_decay)
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer,
milestones=[int(self.hparams.max_epochs*0.6),
int(self.hparams.max_epochs*0.8)],
gamma=0.1)
return [optimizer], [lr_scheduler]
def _calculate_loss(self, batch, mode='train'):
feats, labels = batch
preds = self.model(feats)
loss = F.cross_entropy(preds, labels)
acc = (preds.argmax(dim=-1) == labels).float().mean()
self.log(mode + '_loss', loss)
self.log(mode + '_acc', acc)
return loss
def training_step(self, batch, batch_idx):
return self._calculate_loss(batch, mode='train')
def validation_step(self, batch, batch_idx):
self._calculate_loss(batch, mode='val')
def test_step(self, batch, batch_idx):
self._calculate_loss(batch, mode='test')
- Dữ liệu mà chúng ta sử dụng là bộ dữ liệu huấn luyện và kiểm tra của STL10. Bộ huấn luyện chứa 500 ảnh mỗi lớp, trong khi bộ kiểm tra có 800 ảnh mỗi lớp.
1
2
3
4
5
6
7
8
9
10
img_transforms = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
train_img_data = STL10(root=DATASET_PATH, split='train', download=True,
transform=img_transforms)
test_img_data = STL10(root=DATASET_PATH, split='test', download=True,
transform=img_transforms)
print("Number of training examples:", len(train_img_data))
print("Number of test examples:", len(test_img_data))
- Tiếp theo, chúng ta triển khai một hàm nhỏ để mã hóa tất cả các ảnh trong bộ dữ liệu của mình. Các biểu diễn đầu ra sau đó sẽ được sử dụng làm đầu vào cho mô hình hồi quy logistic.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
@torch.no_grad() # Tắt tính toán gradient, vì không cần thiết trong quá trình chuẩn bị đặc trưng.
def prepare_data_features(model, dataset):
# Prepare model
network = deepcopy(model.convnet) # Sao chép mô hình convnet của SimCLR (không sao chép projection head).
network.fc = nn.Identity() # Loại bỏ projection head (g(.)) để chỉ giữ lại phần mạng cơ bản.
network.eval() # Đặt mô hình vào chế độ đánh giá (evaluation mode).
network.to(device) # Chuyển mô hình lên thiết bị (GPU hoặc CPU).
# Encode all images
data_loader = data.DataLoader(
dataset, # Sử dụng bộ dữ liệu đã cho.
batch_size=64, # Kích thước batch là 64.
num_workers=NUM_WORKERS, # Số worker để tải dữ liệu song song.
shuffle=False, # Không xáo trộn dữ liệu trong quá trình mã hóa.
drop_last=False # Không bỏ batch cuối nếu không đủ kích thước batch.
)
feats, labels = [], [] # Khởi tạo danh sách để lưu trữ đặc trưng và nhãn.
# Lặp qua tất cả các batch trong DataLoader
for batch_imgs, batch_labels in tqdm(data_loader): # tqdm để hiển thị tiến độ.
batch_imgs = batch_imgs.to(device) # Chuyển batch ảnh lên thiết bị (GPU hoặc CPU).
batch_feats = network(batch_imgs) # Mã hóa các ảnh trong batch để lấy đặc trưng.
feats.append(batch_feats.detach().cpu()) # Lưu trữ đặc trưng vào danh sách (tách gradient và chuyển về CPU).
labels.append(batch_labels) # Lưu trữ nhãn vào danh sách.
feats = torch.cat(feats, dim=0) # Kết hợp tất cả đặc trưng thành một tensor duy nhất.
labels = torch.cat(labels, dim=0) # Kết hợp tất cả nhãn thành một tensor duy nhất.
# Sort images by labels
labels, idxs = labels.sort() # Sắp xếp nhãn và lấy chỉ số.
feats = feats[idxs] # Sắp xếp các đặc trưng tương ứng với nhãn.
# Trả về một TensorDataset chứa đặc trưng và nhãn đã sắp xếp.
return data.TensorDataset(feats, labels)
- Cuối cùng, chúng ta có thể viết một hàm huấn luyện như thông thường. Chúng ta đánh giá mô hình trên bộ kiểm tra sau mỗi 10 epoch để cho phép dừng sớm (early stopping), nhưng tần suất thấp của quá trình xác thực đảm bảo rằng chúng ta không bị overfit quá nhiều vào bộ kiểm tra.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
def train_logreg(batch_size, train_feats_data, test_feats_data, model_suffix, max_epochs=100, **kwargs):
# Tạo trainer với các tham số huấn luyện, bao gồm việc lưu checkpoint và theo dõi learning rate
trainer = pl.Trainer(
default_root_dir=os.path.join(CHECKPOINT_PATH, "LogisticRegression"), # Thư mục lưu trữ các checkpoint
accelerator="gpu" if str(device).startswith("cuda") else "cpu", # Sử dụng GPU nếu có, nếu không dùng CPU
devices=1, # Sử dụng 1 thiết bị (GPU hoặc CPU)
max_epochs=max_epochs, # Số epoch tối đa cho việc huấn luyện
callbacks=[ # Các callback trong quá trình huấn luyện
ModelCheckpoint(save_weights_only=True, mode='max', monitor='val_acc'), # Lưu mô hình tốt nhất dựa trên độ chính xác validation
LearningRateMonitor("epoch") # Theo dõi learning rate mỗi epoch
],
enable_progress_bar=False, # Tắt progress bar
check_val_every_n_epoch=10 # Kiểm tra trên validation set mỗi 10 epoch
)
trainer.logger._default_hp_metric = None # Không cần theo dõi các thông số hyperparameter mặc định
# Data loaders: Tạo DataLoader cho bộ dữ liệu huấn luyện và kiểm tra
train_loader = data.DataLoader(
train_feats_data, # Bộ dữ liệu huấn luyện
batch_size=batch_size, # Kích thước batch
shuffle=True, # Xáo trộn dữ liệu trong mỗi epoch
drop_last=False, # Không bỏ qua batch cuối nếu kích thước không đủ
pin_memory=True, # Tăng tốc độ chuyển dữ liệu lên GPU
num_workers=0 # Sử dụng 0 worker (có thể thay đổi nếu cần tốc độ tải dữ liệu nhanh hơn)
)
test_loader = data.DataLoader(
test_feats_data, # Bộ dữ liệu kiểm tra
batch_size=batch_size, # Kích thước batch
shuffle=False, # Không xáo trộn dữ liệu
drop_last=False, # Không bỏ qua batch cuối nếu kích thước không đủ
pin_memory=True, # Tăng tốc độ chuyển dữ liệu lên GPU
num_workers=0 # Sử dụng 0 worker
)
# Kiểm tra xem có mô hình đã huấn luyện sẵn không. Nếu có, tải nó và bỏ qua quá trình huấn luyện
pretrained_filename = os.path.join(CHECKPOINT_PATH, f"LogisticRegression_{model_suffix}.ckpt") # Đường dẫn tới checkpoint đã lưu
if os.path.isfile(pretrained_filename): # Kiểm tra xem file checkpoint có tồn tại không
print(f"Found pretrained model at {pretrained_filename}, loading...") # In thông báo nếu tìm thấy mô hình đã huấn luyện
model = LogisticRegression.load_from_checkpoint(pretrained_filename) # Tải mô hình đã huấn luyện
else: # Nếu không có mô hình huấn luyện sẵn, tiến hành huấn luyện mới
pl.seed_everything(42) # Đặt seed để tái tạo kết quả huấn luyện
model = LogisticRegression(**kwargs) # Khởi tạo mô hình LogisticRegression với các tham số đã cho
trainer.fit(model, train_loader, test_loader) # Huấn luyện mô hình với bộ dữ liệu huấn luyện và kiểm tra
model = LogisticRegression.load_from_checkpoint(trainer.checkpoint_callback.best_model_path) # Tải mô hình tốt nhất sau khi huấn luyện
# Kiểm tra mô hình tốt nhất trên bộ dữ liệu huấn luyện và kiểm tra
train_result = trainer.test(model, train_loader, verbose=False) # Đánh giá mô hình trên bộ dữ liệu huấn luyện
test_result = trainer.test(model, test_loader, verbose=False) # Đánh giá mô hình trên bộ dữ liệu kiểm tra
result = {"train": train_result[0]["test_acc"], "test": test_result[0]["test_acc"]} # Lưu kết quả độ chính xác trên cả bộ huấn luyện và kiểm tra
return model, result # Trả về mô hình đã huấn luyện và kết quả độ chính xác
- Mặc dù bộ dữ liệu huấn luyện của STL10 đã chỉ có 500 ảnh có nhãn mỗi lớp, chúng ta sẽ thực hiện các thí nghiệm với các bộ dữ liệu nhỏ hơn. Cụ thể, chúng ta huấn luyện mô hình Hồi quy Logistic cho các bộ dữ liệu chỉ có 10, 20, 50, 100, 200 và tất cả 500 ví dụ mỗi lớp. Điều này giúp chúng ta có cái nhìn về việc các biểu diễn học được từ học sâu tương phản có thể được chuyển giao tốt như thế nào cho một tác vụ nhận diện ảnh như phân loại này. Đầu tiên, hãy định nghĩa một hàm để tạo ra các bộ dữ liệu con theo ý định từ bộ huấn luyện đầy đủ:
1
2
3
4
5
def get_smaller_dataset(original_dataset, num_imgs_per_label):
new_dataset = data.TensorDataset(
*[t.unflatten(0, (10, -1))[:,:num_imgs_per_label].flatten(0, 1) for t in original_dataset.tensors]
)
return new_dataset
- Tiếp theo, chúng ta sẽ chạy tất cả các mô hình. Mặc dù chúng ta huấn luyện 6 mô hình, nhưng đoạn mã này có thể được chạy trong vòng một hoặc hai phút mà không cần các mô hình đã huấn luyện sẵn.
1
2
3
4
5
6
7
8
9
10
11
12
results = {}
for num_imgs_per_label in [10, 20, 50, 100, 200, 500]:
sub_train_set = get_smaller_dataset(train_feats_simclr, num_imgs_per_label)
_, small_set_resultNext, let's run all models. Despite us training 6 models, this cell could be run within a minute or two without the pretrained models.s = train_logreg(batch_size=64,
train_feats_data=sub_train_set,
test_feats_data=test_feats_simclr,
model_suffix=num_imgs_per_label,
feature_dim=train_feats_simclr.tensors[0].shape[1],
num_classes=10,
lr=1e-3,
weight_decay=1e-3)
results[num_imgs_per_label] = small_set_results
- Cuối cùng, hãy trực quan hóa kết quả:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
dataset_sizes = sorted([k for k in results])
test_scores = [results[k]["test"] for k in dataset_sizes]
fig = plt.figure(figsize=(6,4))
plt.plot(dataset_sizes, test_scores, '--', color="#000", marker="*", markeredgecolor="#000", markerfacecolor="y", markersize=16)
plt.xscale("log")
plt.xticks(dataset_sizes, labels=dataset_sizes)
plt.title("STL10 classification over dataset size", fontsize=14)
plt.xlabel("Number of images per class")
plt.ylabel("Test accuracy")
plt.minorticks_off()
plt.show()
for k, score in zip(dataset_sizes, test_scores):
print(f'Test accuracy for {k:3d} images per label: {100*score:4.2f}%')

Như người ta mong đợi, hiệu suất phân loại cải thiện khi chúng ta có nhiều dữ liệu hơn. Tuy nhiên, với chỉ 10 ảnh mỗi lớp, chúng ta đã có thể phân loại hơn 60% ảnh một cách chính xác. Điều này khá ấn tượng, vì các ảnh này có độ chiều cao hơn so với ví dụ như CIFAR10. Với bộ dữ liệu đầy đủ, chúng ta đạt được độ chính xác 81%. Sự gia tăng từ 50 đến 500 ảnh mỗi lớp có thể gợi ý một sự tăng trưởng tuyến tính trong hiệu suất khi bộ dữ liệu mở rộng theo cấp số nhân. Tuy nhiên, với nhiều dữ liệu hơn, chúng ta cũng có thể thực hiện tinh chỉnh mô hình trong quá trình huấn luyện, cho phép các biểu diễn thích ứng tốt hơn với nhiệm vụ phân loại cụ thể.
Để đặt kết quả trên vào bối cảnh, chúng ta sẽ huấn luyện mạng cơ sở, một ResNet-18, trên tác vụ phân loại từ đầu.
Baseline
- Như một mốc cơ bản cho các kết quả trên, chúng ta sẽ huấn luyện một ResNet-18 tiêu chuẩn với khởi tạo ngẫu nhiên trên bộ dữ liệu huấn luyện có nhãn của STL10. Kết quả sẽ giúp chúng ta có cái nhìn về những lợi thế mà học sâu tương phản trên dữ liệu không có nhãn mang lại so với việc chỉ sử dụng huấn luyện có giám sát. Việc triển khai mô hình là khá đơn giản vì kiến trúc ResNet đã được cung cấp trong thư viện torchvision.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class ResNet(pl.LightningModule):
def __init__(self, num_classes, lr, weight_decay, max_epochs=100):
super().__init__() # Khởi tạo lớp cha (pl.LightningModule)
self.save_hyperparameters() # Lưu các siêu tham số để sử dụng sau này
# Khởi tạo mô hình ResNet-18 với số lớp đầu ra được cung cấp
self.model = torchvision.models.resnet18(num_classes=num_classes)
def configure_optimizers(self):
# Định nghĩa bộ tối ưu hóa là AdamW với học tỷ lệ và weight decay từ các siêu tham số
optimizer = optim.AdamW(self.parameters(),
lr=self.hparams.lr,
weight_decay=self.hparams.weight_decay)
# Định nghĩa bộ điều chỉnh học tỷ lệ với các mốc thời gian để giảm học tỷ lệ
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer,
milestones=[int(self.hparams.max_epochs*0.7),
int(self.hparams.max_epochs*0.9)],
gamma=0.1)
return [optimizer], [lr_scheduler] # Trả về bộ tối ưu hóa và bộ điều chỉnh
def _calculate_loss(self, batch, mode='train'):
imgs, labels = batch # Giải nén batch thành ảnh và nhãn
preds = self.model(imgs) # Lấy dự đoán từ mô hình
loss = F.cross_entropy(preds, labels) # Tính toán tổn thất cross-entropy
acc = (preds.argmax(dim=-1) == labels).float().mean() # Tính độ chính xác bằng cách lấy trung bình các dự đoán chính xác
# Ghi log tổn thất và độ chính xác cho chế độ hiện tại (train, val, test)
self.log(mode + '_loss', loss)
self.log(mode + '_acc', acc)
return loss # Trả về tổn thất đã tính toán
def training_step(self, batch, batch_idx):
# Thực hiện bước huấn luyện (tính toán tổn thất và ghi log)
return self._calculate_loss(batch, mode='train')
def validation_step(self, batch, batch_idx):
# Thực hiện bước xác thực (tính toán tổn thất và ghi log)
self._calculate_loss(batch, mode='val')
def test_step(self, batch, batch_idx):
# Thực hiện bước kiểm tra (tính toán tổn thất và ghi log)
self._calculate_loss(batch, mode='test')
- Rõ ràng là ResNet dễ dàng bị overfit trên dữ liệu huấn luyện vì số lượng tham số của nó lớn hơn hơn 1000 lần so với kích thước bộ dữ liệu. Để so sánh công bằng với các mô hình học sâu tương phản, chúng ta áp dụng các phép biến đổi dữ liệu tương tự như trước đây: lật ngang, cắt và thay đổi kích thước, chuyển sang ảnh xám và làm mờ Gaussian. Không sử dụng các biến đổi màu như trước vì phân phối màu của ảnh được cho là một đặc trưng quan trọng cho phân loại. Do đó, chúng tôi không nhận thấy sự cải thiện hiệu suất khi thêm các biến đổi màu vào bộ biến đổi. Tương tự, chúng tôi giới hạn thao tác thay đổi kích thước trước khi cắt sao cho không vượt quá 125% độ phân giải gốc, thay vì 1250% như trong SimCLR. Điều này là vì, đối với phân loại, mô hình cần nhận dạng toàn bộ đối tượng, trong khi trong học sâu tương phản, chúng ta chỉ muốn kiểm tra liệu hai mảng có thuộc về cùng một ảnh/đối tượng hay không. Do đó, các phép biến đổi được chọn dưới đây yếu hơn tổng thể so với trường hợp học sâu tương phản.
1
2
3
4
5
6
7
8
9
10
train_transforms = transforms.Compose([transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(size=96, scale=(0.8, 1.0)),
transforms.RandomGrayscale(p=0.2),
transforms.GaussianBlur(kernel_size=9, sigma=(0.1, 0.5)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_img_aug_data = STL10(root=DATASET_PATH, split='train', download=True,
transform=train_transforms)
- Hàm huấn luyện cho ResNet gần như giống hệt với cấu hình của Logistic Regression. Lưu ý rằng chúng ta cho phép ResNet thực hiện xác thực mỗi 2 epoch để kiểm tra xem mô hình có bị overfit mạnh trong những lần lặp đầu tiên hay không.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
def train_resnet(batch_size, max_epochs=100, **kwargs):
trainer = pl.Trainer(default_root_dir=os.path.join(CHECKPOINT_PATH, "ResNet"),
accelerator="gpu" if str(device).startswith("cuda") else "cpu",
devices=1,
max_epochs=max_epochs,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc"),
LearningRateMonitor("epoch")],
check_val_every_n_epoch=2)
trainer.logger._default_hp_metric = None
# Data loaders
train_loader = data.DataLoader(train_img_aug_data, batch_size=batch_size, shuffle=True,
drop_last=True, pin_memory=True, num_workers=NUM_WORKERS)
test_loader = data.DataLoader(test_img_data, batch_size=batch_size, shuffle=False,
drop_last=False, pin_memory=True, num_workers=NUM_WORKERS)
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, "ResNet.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model at %s, loading..." % pretrained_filename)
model = ResNet.load_from_checkpoint(pretrained_filename)
else:
pl.seed_everything(42) # To be reproducable
model = ResNet(**kwargs)
trainer.fit(model, train_loader, test_loader)
model = ResNet.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
# Test best model on validation set
train_result = trainer.test(model, train_loader, verbose=False)
val_result = trainer.test(model, test_loader, verbose=False)
result = {"train": train_result[0]["test_acc"], "test": val_result[0]["test_acc"]}
return model, result
- ResNet được huấn luyện từ đầu đạt 73,31% trên bộ kiểm tra. Điều này thấp hơn khoảng 8% so với mô hình học sâu tương phản, và thậm chí còn thấp hơn một chút so với kết quả của SimCLR đạt được với 1/10 dữ liệu. Điều này cho thấy rằng học sâu tự giám sát, học sâu tương phản mang lại những cải thiện hiệu suất đáng kể nhờ tận dụng lượng lớn dữ liệu không nhãn khi có rất ít dữ liệu có nhãn.
2. Kết luận
- Trong blog này, chúng ta đã thảo luận về học sâu tự giám sát và học sâu tương phản, và đã triển khai SimCLR như một phương pháp ví dụ. Chúng ta đã áp dụng nó cho bộ dữ liệu STL10 và chỉ ra rằng nó có thể học được những biểu diễn có khả năng tổng quát mà chúng ta có thể sử dụng để huấn luyện các mô hình phân loại đơn giản. Với 500 ảnh mỗi nhãn, nó đạt được độ chính xác cao hơn 8% so với mô hình tương tự chỉ được huấn luyện từ giám sát và có hiệu suất tương đương khi chỉ sử dụng một phần mười dữ liệu có nhãn. Kết quả thí nghiệm của chúng ta chỉ giới hạn ở một bộ dữ liệu duy nhất, nhưng các công trình gần đây như của Ting Chen và các cộng sự đã chỉ ra xu hướng tương tự với các bộ dữ liệu lớn hơn như ImageNet. Bên cạnh các siêu tham số đã thảo luận, kích thước của mô hình cũng có vẻ quan trọng trong học sâu tương phản. Nếu có nhiều dữ liệu không nhãn, các mô hình lớn hơn có thể đạt được kết quả mạnh mẽ hơn và gần với các mô hình giám sát. Hơn nữa, cũng có các phương pháp kết hợp học sâu tương phản và học giám sát, dẫn đến việc cải thiện hiệu suất vượt qua cả giám sát (xem Khosla và các cộng sự). Hơn nữa, học sâu tương phản không phải là phương pháp duy nhất trong học tự giám sát đã xuất hiện trong hai năm qua và đã cho kết quả xuất sắc. Các phương pháp khác bao gồm các phương pháp dựa trên chưng cất như BYOL và kỹ thuật giảm dư thừa như Barlow Twins. Có rất nhiều điều để khám phá trong lĩnh vực tự giám sát, và nhiều bước tiến ấn tượng sẽ còn xuất hiện trong tương lai.