Text Classification
- Phân loại văn bản là một trong những nhiệm vụ phổ biến nhất trong NLP; Nó có thể được sử dụng cho nhiều ứng dụng, chẳng hạn như gắn thẻ phản hồi của khách hàng vào các danh mục hoặc định tuyến phiếu hỗ trợ theo ngôn ngữ của họ. Rất có thể bộ lọc email của bạn đang sử dụng phân loại văn bản để bảo vệ hộp thư đến của bạn khỏi một đống thư rác !
- Một loại phân loại văn bản phổ biến khác là phân tích cảm xúc (sentiment analysis), nhằm xác định cảm xúc của một văn bản nhất định. Ví dụ, một công ty như Tesla có thể phân tích các bài đăng trên Twitter như trong Hình 2-1 để xác định xem mọi người có thích nóc xe mới của họ hay không.

- Bây giờ hãy tưởng tượng rằng bạn là một nhà khoa học dữ liệu cần xây dựng một hệ thống có thể tự động xác định các trạng thái cảm xúc như “tức giận” hoặc “niềm vui” mà mọi người thể hiện về sản phẩm của công ty bạn trên Twitter. Trong chương này, chúng ta sẽ giải quyết nhiệm vụ này bằng cách sử dụng một biến thể của BERT được gọi là DistilBERT. Ưu điểm chính của mô hình này là nó đạt được hiệu suất tương đương với BERT, đồng thời nhỏ hơn đáng kể và hiệu quả hơn. Điều này cho phép chúng ta train một bộ phân loại trong vài phút và nếu bạn muốn train một mô hình BERT lớn hơn, bạn có thể chỉ cần thay đổi checkpoint của pretrained model. Một checkpoints tương ứng với tập hợp các trọng số được tải vào một kiến trúc transformer nhất định.
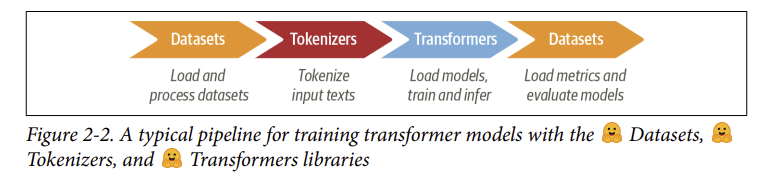
- Đây cũng sẽ là cuộc gặp gỡ đầu tiên của chúng ta với ba trong số các thư viện cốt lõi từ hệ sinh thái Hugging Face: 🤗 Datasets, 🤗 Tokenizers và 🤗 Transformers. Như thể hiện trong Hình 2-2, các thư viện này sẽ cho phép chúng ta nhanh chóng chuyển từ văn bản thô sang một fine-tuned model có thể được sử dụng để suy luận trên các bài tweet mới.
1. The Dataset
- Để xây dựng công cụ phân loại cảm xúc, chúng ta sẽ sử dụng một bộ data tuyệt vời từ một bài báo khám phá cách cảm xúc được thể hiện trong các tin nhắn Twitter bằng tiếng Anh. Hầu hết các bộ data phân loại cảm xúc khác chỉ có hai nhãn là “postive” và “negative”, bộ data này chứa sáu nhãn cảm xúc cơ bản: anger, disgust, fear, joy, sadness, and surprise. Với một tweet, nhiệm vụ của chúng ta sẽ là train một mô hình có thể phân loại nó thành một trong những cảm xúc này.
A First Look at Hugging Face Datasets
- Chúng ta sẽ sử dụng 🤗 Datasets để tải bộ data từ Hugging Face Hub. Chúng ta có thể sử dụng hàm
list_datasets()để xem những bộ dữ liệu nào có sẵn trên Hub:
1
2
3
4
5
from huggingface_hub import list_datasets
all_datasets = list(list_datasets())
print(f"There are {len(all_datasets)} datasets currently available on the Hub")
print(f"The first 10 are: {all_datasets[:10]}")
- Chúng ta thấy rằng mỗi tập dataset được đặt một tên, vì vậy hãy tải tập emotion dataset bằng hàm
load_dataset():
1
2
3
from datasets import load_dataset
emotions = load_dataset("emotion")
- Nếu chúng ta in ra biến
emotions:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
print(emotions)
# DatasetDict({
# train: Dataset({
# features: ['text', 'label'],
# num_rows: 16000
# })
# validation: Dataset({
# features: ['text', 'label'],
# num_rows: 2000
# })
# test: Dataset({
# features: ['text', 'label'],
# num_rows: 2000
# })
# })
- Chúng ta sẽ thấy rất giống với từ điển trong Python, với mỗi khóa tương ứng với một tập dữ liệu. Chúng ta cũng có thể sử dụng các cú pháp của từ điển để truy cập vào tập dữ liệu cụ thể:
1
2
3
4
5
6
7
train_ds = emotions["train"]
train_ds
# Dataset({
# features: ['text', 'label'],
# num_rows: 16000
# })
- Code trên trả về một thực thể của lớp Dataset. Đối tượng Dataset là một trong những cấu trúc dữ liệu cốt lõi trong 🤗 Datasets và chúng ta sẽ khám phá nhiều tính năng của nó trong suốt cuốn sách này. Đối với người mới bắt đầu, nó hoạt động giống như một mảng hoặc danh sách Python thông thường, vì vậy chúng ta có thể truy vấn độ dài của nó:
1
len(train_ds) # 16000
- Hoặc truy cập vào một phần tử cụ thể bằng chỉ số:
1
2
train_ds[0]
# {'text': 'i didnt feel humiliated', 'label': 0}
- Ở đây chúng ta thấy mỗi hàng cụ thể tượng trưng cho dạng từ điển, trong đó khóa của nó là tên các cột:
1
2
train_ds.column_names
# ['text', 'label']
- Và giá trị trong trường hợp này là văn bản tweet và cảm xúc. Điều này phản ánh sự thật là 🤗 Datasets dựa trên Apache Arrow, thứ mà định dạng cột được lưu trữ trong bộ nhớ hiệu quả hơn Python bình thường. Chúng ta có thể xem những kiểu dữ liệu nào đang được bằng cách truy cập thuộc tính
featurescủa đối tượng Dataset:
1
2
3
4
train_ds.features
# {'text': Value(dtype='string', id=None),
# 'label': ClassLabel(names=['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'], id=None)}
- Trong trường hợp này, kiểu dữ liệu của cột
textlàstring, trong khi cộtlabellà một đối tượngClassLabelđặc biệt chứa thông tin về tên lớp và ánh xạ của chúng với số nguyên. Chúng ta cũng có thể truy cập một số hàng với slice:
1
2
3
4
5
6
7
8
train_ds[:5]
# {'text': ['i didnt feel humiliated',
# 'i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake',
# 'im grabbing a minute to post i feel greedy wrong',
# 'i am ever feeling nostalgic about the fireplace i will know that it is still on the property',
# 'i am feeling grouchy'],
# 'label': [0, 0, 3, 2, 3]}
- Chúng ta cũng có thể lấy toàn bộ một cột theo tên:
1
2
3
4
5
6
7
train_ds["text"][:5]
# ['i didnt feel humiliated',
# 'i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake',
# 'im grabbing a minute to post i feel greedy wrong',
# 'i am ever feeling nostalgic about the fireplace i will know that it is still on the property',
# 'i am feeling grouchy']
Nếu Dataset của bạn không có trên Hub thì sao ?
- Chúng ta sẽ sử dụng Hugging Face Hub để tải xuống bộ dữ liệu cho hầu hết các ví dụ trong cuốn sách này. Nhưng trong nhiều trường hợp, bạn sẽ thấy mình làm việc với dữ liệu được lưu trữ trên máy tính cá nhân hoặc trên remote serve trong tổ chức. 🤗 Datasets cung cấp một số lệnh tải để xử lý các tập dữ liệu cục bộ và remote. Ví dụ về các định dạng dữ liệu phổ biến nhất được hiển thị trong Bảng 2-1

- Như bạn có thể thấy, đối với mỗi định dạng dữ liệu, chúng ta chỉ cần chuyển tập lệnh tải có liên quan đến hàm
load_dataset(), cùng với tham sốdata_filesđể chỉ định đường dẫn hoặc URL đến một hoặc nhiều file. Ví dụ: các file về emotion dataset được lưu trữ trên Dropbox, vì vậy một cách thay thế để tải data là:
1
2
dataset_url = "https://www.dropbox.com/s/1pzkadrvffbqw6o/train.txt"
!wget {dataset_url
- Xem kĩ phần này hơn tại 🤗 Datasets Documentation
From Datasets to DataFrames
- Mặc dù 🤗 Datasets cung cấp rất nhiều chức năng cấp thấp để xử lý dữ liệu của chúng ta, nhưng việc chuyển đổi 🤗 Datasets thành Pandas DataFrame thường rất thuận tiện để chúng ta có thể truy cập các API cấp cao để trực quan hóa dữ liệu. Để kích hoạt chuyển đổi, 🤗 Datasets cung cấp phương thức
set_format()cho phép chúng ta thay đổi định dạng đầu ra của Dataset:
1
2
3
4
import pandas as pd
emotions.set_format(type = "pandas")
df = emotions["train"][:]
df.head()

- Như bạn có thể thấy, các tiêu đề cột đã được giữ nguyên và một vài hàng đầu tiên khớp với các chế độ xem dữ liệu trước đó của chúng ta. Tuy nhiên, các nhãn được biểu diễn dưới dạng số nguyên, vì vậy hãy sử dụng phương thức
int2str()để tạo một cột mớilabel_nametrong DataFrame:
1
2
3
4
5
def label_int2str(row):
return emotions["train"].features["label"].int2str(row)
df["label_name"] = df["label"].apply(label_int2str)
df.head()

- Trước khi đi sâu vào việc xây dựng một bộ phân loại, chúng ta hãy xem xét kỹ hơn tập dữ liệu. Như Andrej Karpathy lưu ý trong bài đăng trên blog nổi tiếng của mình “A Recipe for Training Neural Networks”, “Become one with the data” là một bước cần thiết để train các mô hình tuyệt vời!
Looking at the Class Distribution
Bất cứ khi nào bạn đang làm việc với các vấn đề phân loại văn bản, bạn nên kiểm tra sự phân bố của các ví dụ giữa các lớp. Một tập dữ liệu có phân bố lớp sai lệch có thể yêu cầu một cách xử lý khác về evaluation metrics và training loss so với một bộ dữ liệu cân bằng.
Với
PandasvàMatplotlib, chúng ta có thể dễ dàng trực quan hóa phân bố của các nhãn như sau:
1
2
3
4
import matplotlib.pyplot as plt
df["label_name"].value_counts(ascending=True).plot.barh()
plt.title("Frequency of Classes")
plt.show()
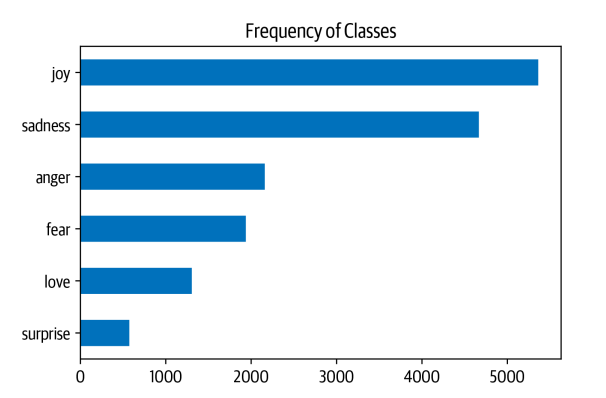
- Trong trường hợp này, chúng ta có thể thấy rằng tập dữ liệu bị mất cân bằng nặng; Các lớp joy và sadness xuất hiện thường xuyên, trong khi love và surprise xuất hiện hiếm hơn khoảng 5-10 lần. Có một số cách để xử lý dữ liệu mất cân bằng, bao gồm:
- Randomly oversample lớp thiểu số
- Randomly undersample lớp đa số
- Thu thập thêm dữ liệu có nhãn từ các lớp thiểu số
- Để giữ cho mọi thứ đơn giản trong chương này, chúng ta sẽ làm việc với các tần số lớp thô, không cân bằng. Nếu bạn muốn tìm hiểu thêm về các kỹ thuật lấy mẫu này, tôi khuyên bạn nên xem thư viện Imbalanced-learn. Chỉ cần đảm bảo rằng bạn không áp dụng các phương pháp sampling trước khi tách thành hai tập train và test, nếu không bạn sẽ bị rò rỉ dữ liệu giữa chúng !
How Long Are Our Tweets?
- Độ dài tối đa của input cho các mô hình transformers được gọi là maximum context size. Đối với các ứng dụng sử dụng DistilBERT, maximum context size là 512 token, tương đương với một vài đoạn văn bản. Như chúng ta sẽ thấy trong phần tiếp theo, token là thành phần nhỏ nhất (thành phần nguyên tử); Bây giờ, để đơn giản, chúng ta sẽ coi một token như một từ. Chúng ta có thể ước tính sơ bộ về độ dài tweet trên mỗi cảm xúc bằng cách xem xét sự phân phối của các từ trên mỗi tweet:
1
2
3
4
5
6
df["Words Per Tweet"] = df["text"].str.split().apply(len)
df.boxplot("Words Per Tweet", by="label_name", grid=False,
showfliers=False, color="black")
plt.suptitle("")
plt.xlabel("")
plt.show()

- Từ đồ thị, chúng ta thấy rằng đối với mỗi cảm xúc, hầu hết các tweet dài khoảng 15 từ và các tweet dài nhất thấp hơn nhiều so với maximum context size của DistilBERT. Các văn bản dài hơn maximum context size của mô hình cần được cắt bớt, điều này có thể dẫn đến giảm hiệu suất nếu văn bản bị cắt bớt chứa thông tin quan trọng; Trong trường hợp của chúng ta, có vẻ như đó sẽ không phải là vấn đề vì các văn bản đều có độ dài nhỏ hơn ngưỡng tối đa.
- Bây giờ chúng ta hãy tìm hiểu cách chúng ta có thể chuyển đổi các văn bản thô này thành một định dạng phù hợp với 🤗 Transformers! Trước khi làm điều đó, chúng ta cũng hãy đặt lại định dạng đầu ra của tập dữ liệu vì chúng ta không cần định dạng DataFrame nữa:
1
emotions.reset_format()
2. From Text to Tokens
- Các mô hình Transformer như DistilBERT không thể nhận văn bản thô làm đầu vào; thay vào đó, các mô hình chỉ nhận văn bản đã được tokenized và encoded dưới dạng số. Tokenization là bước chia nhỏ một chuỗi thành các đơn vị nhỏ (nguyên tử) được sử dụng trong mô hình. Có một số chiến lược tokenization mà người ta có thể áp dụng và việc phân tách các từ thành các đơn vị con tối ưu thường được học từ kho dữ liệu. Trước khi xem xét tokenizer được sử dụng cho DistilBERT, chúng ta hãy xem xét hai trường hợp đơn giản: token ký tự và từ.
Character Tokenization
- Cách tokenization đơn giản nhất là chia thành từng ký tự rồi cho vào mô hình. Trong Python, đối tượng
strthực chất là một mảng, cho phép chúng ta nhanh chóng thực hiện token cấp ký tự chỉ với một dòng code:
1
2
3
4
5
6
7
8
text = "Tokenizing text is a core task of NLP."
tokenized_text = list(text)
print(tokenized_text)
# ['T', 'o', 'k', 'e', 'n', 'i', 'z', 'i', 'n', 'g', ' ', 't', 'e', 'x', 't', ' ',
# 'i', 's', ' ', 'a', ' ', 'c', 'o', 'r', 'e', ' ', 't', 'a', 's', 'k', ' ', 'o',
# 'f', ' ', 'N', 'L', 'P', '.']
- Đây là một khởi đầu tốt, nhưng chúng ta chưa làm xong đâu. Mô hình cần các kí tự phải được chuyển về dạng số, quá trình này đôi khi được gọi là numericalization. Một cách đơn giản là encoding từng token cụ thể (trong trường hợp này là ký tự) sang một số nguyên cụ thể:
1
2
3
4
5
6
token2idx = {ch: idx for idx, ch in enumerate(sorted(set(text)))}
print(token2idx)
# {' ': 0, '.': 1, 'L': 2, 'N': 3, 'P': 4, 'T': 5, 'a': 6, 'c': 7, 'e': 8, 'f': 9,
# 'g': 10, 'i': 11, 'k': 12, 'n': 13, 'o': 14, 'r': 15, 's': 16, 't': 17, 'x': 18,
# 'z': 19}
- Code trên cho chúng ta một cách mapping mỗi kí tự trong từ điển sang một số nguyên duy nhất. Giờ chúng ta có thể sử dụng
token2idxđể chuyển tokenized text sang một list các số nguyên:
1
2
3
4
input_ids = [token2idx[token] for token in tokenized_text]
print(input_ids)
# [5, 14, 12, 8, 13, 11, 19, 11, 13, 10, 0, 17, 8, 18, 17, 0, 11, 16, 0, 6, 0, 7, 14, 15, 8, 0, 17, 6, 16, 12, 0, 14, 9, 0, 3, 2, 4, 1]
- Giờ mỗi token đã được mapping sang một số định danh duy nhất (lưu trong biến
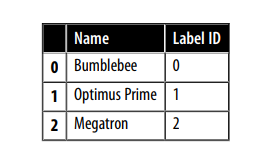
input_ids). Bước cuối cùng là chuyểninput_idssang dạng 2D tensor của các one-hot vectors. One-hot vectors thường rất hay được sử dụng trong machine learning để encode các categorcial data, thường là ordinal hoặc normal. Ví dụ, giả sử chúng ta muốn encoder tên của các nhân vật trong phim Transformers. Một cách để làm đó là map tên sang một ID duy nhất:
1
2
3
categorical_df = pd.DataFrame(
{"Name": ["Bumblebee", "Optimus Prime", "Megatron"], "Label ID": [0,1,2]})
categorical_df
- Vấn đề với cách tiếp cận này là nó tạo ra một thứ tự hư cấu giữa các tên và neural networks thực sự tốt trong việc học các loại mối quan hệ này. Vì vậy, thay vào đó, chúng ta có thể tạo một cột mới cho mỗi loại và gán 1 nếu loại ý đúng, 0 trong trường hợp ngược lại. Trong Pandas, điều này có thể được thực hiện với hàm
get_dummies()như sau:
1
pd.get_dummies(categorical_df["Name"])
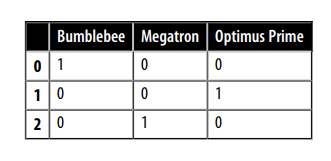
Các hàng của DataFrame này là vector one-hot, hiểu đơn giản là chỉ có một số 1 và còn lại là số 0. Giờ hãy nhìn lại biến
input_ids, chúng ta có vấn đề tương tự: các phần tử tạo ra thứ tự vô nghĩa. Điều này có nghĩa là cộng hay trừ hai ID là một phép toán vô nghiĩ, vì kết quả là một ID tuợng trưng cho một token ngẫu nhiên khác.Mặt khác, kết quả của việc cộng hai vector one-hot có thể dễ dàng được giải thích: Hai số 1 tượng trưng cho 2 token đồng thời có. Chúng ta có thể tạo mã hóa one-hot trong PyTorch bằng cách chuyển đổi
input_idsthành tensor và áp dụng hàmone_hot()như sau:
1
2
3
4
5
6
7
import torch
import torch.nn.functional as F
input_ids = torch.tensor(input_ids)
one_hot_encodings = F.one_hot(input_ids, num_classes = len(token2idx))
one_hot_encodings.shape
# torch.Size([38, 20])
- Mỗi trong số 38 input tokens, có một vectơ ont-hot với 20 chiều, vì từ vựng của chúng ta bao gồm 20 ký tự duy nhất.
Điều quan trọng là phải luôn đặt tham số num_classes trong hàm one_hot() vì nếu không các vectơ one-hot có thể ngắn hơn độ dài của từ vựng (và cần được đệm bằng số 0 theo cách thủ công). Trong TensorFlow, hàm tương đương là tf.one_hot(), trong đó tham số depth đóng vai trò như tham số num_classes.
- Bằng cách kiểm tra vectơ đầu tiên, chúng ta có thể xác nhận rằng số 1 xuất hiện ở vị trí được chỉ ra bởi input_ids[0]:
1
2
3
4
5
6
7
print(f"Token: {tokenized_text[0]}")
print(f"Tensor index: {input_ids[0]}")
print(f"One-hot: {one_hot_encodings[0]}")
# Token: T
# Tensor index: 5
# One-hot: tensor([0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
- Từ ví dụ đơn giản trên, chúng ta có thể thấy rằng tokenization cấp ký tự bỏ qua bất kỳ cấu trúc nào trong văn bản và coi toàn bộ chuỗi như một luồng ký tự. Mặc dù điều này giúp đối phó với lỗi chính tả và các từ hiếm, nhưng hạn chế chính là các cấu trúc ngôn ngữ như từ cần được học từ dữ liệu. Điều này đòi hỏi tính toán, bộ nhớ và dữ liệu đáng kể. Vì lý do này, tokenization ký tự hiếm khi được sử dụng trong thực tế. Thay vào đó, một số cấu trúc của văn bản được giữ nguyên trong bước tokenization. tokenization cấp độ từ là một cách tiếp cận đơn giản để đạt được điều này, vì vậy chúng ta hãy xem nó hoạt động như thế nào.
Word Tokenization
Thay vì chia văn bản thành các ký tự, chúng ta có thể chia nó thành các từ và ánh xạ mỗi từ thành một số nguyên. Sử dụng từ ngay từ đầu cho phép mô hình bỏ qua bước học từ dựa trên các ký tự và do đó giảm độ phức tạp của quá trình training.
Một cách đơn giản để chia từ đó là dựa vào khoảng trắng. Chúng ta có thể dùng hàm
split()trực tiếp trên chuỗi thô để chia từ dựa vào khoảng trắng:
1
2
3
tokenized_text = text.split()
print(tokenized_text)
# ['Tokenizing', 'text', 'is', 'a', 'core', 'task', 'of', 'NLP.']
Từ đây, chúng ta có thể thực hiện các bước tương tự như chúng ta đã thực hiện đối với token cấp đô ký tự để ánh xạ từng từ với một ID duy nhất. Tuy nhiên, chúng ta đã có thể thấy một vấn đề tiềm ẩn với cách encode này: dấu câu không được tính đến, vì vậy “NLP.” được coi là một token duy nhất. Điều này dẫn đến vocab bao gồm các từ sai lệch, chia từ hoặc sai chính tả, kích thước của từ vựng có thể dễ dàng tăng lên hàng triệu !
Việc có một vocab lớn là một vấn đề vì nó yêu cầu neural networks phải có một số lượng tham số khổng lồ. Để minh họa, giả sử chúng ta có 1 triệu từ duy nhất và muốn nén các vector đầu vào có kích thước 1 triệu chiều xuống các vector 1 nghìn chiều trong lớp đầu tiên của neural networks. Đây là một bước tiêu chuẩn trong hầu hết các kiến trúc NLP, và ma trận trọng số kết quả của lớp đầu tiên này sẽ chứa 1 triệu × 1 nghìn = 1 tỷ trọng số. Điều này đã gần bằng số tham số của mô hình GPT-2 lớn nhất, với khoảng 1,5 tỷ tham số!
Tất nhiên, chúng ta muốn tránh lãng phí tài nguyên mô hình như vậy bởi vì việc huấn luyện mô hình rất tốn kém, và các mô hình lớn hơn khó duy trì hơn. Một cách tiếp cận phổ biến là giới hạn kích thước từ vựng và loại bỏ các từ hiếm bằng cách chỉ xét, ví dụ, 100.000 từ phổ biến nhất trong tập dữ liệu. Các từ không thuộc từ vựng này sẽ được phân loại là “không xác định” và được ánh xạ đến một token UNK chung. Điều này có nghĩa là chúng ta mất một số thông tin tiềm năng quan trọng trong quá trình token hóa từ, vì mô hình không có thông tin về các từ liên quan đến token UNK.
Liệu sẽ thật tuyệt nếu có một sự thỏa hiệp giữa token hóa ký tự và token hóa từ, cho phép giữ lại toàn bộ thông tin đầu vào và một phần cấu trúc của đầu vào? Và câu trả lời là: subwork tokenization.
Subword Tokenization
Ý tưởng cơ bản đằng sau subword tokenization là kết hợp những điểm mạnh nhất của token hóa ký tự và token hóa từ. Một mặt, chúng ta muốn tách các từ hiếm thành những đơn vị nhỏ hơn để mô hình có thể xử lý các từ phức tạp và lỗi chính tả. Mặt khác, chúng ta muốn giữ các từ phổ biến như các thực thể duy nhất để có thể giữ độ dài đầu vào ở mức hợp lý. Điểm khác biệt chính của subword tokenization là nó được học từ tập dữ liệu huấn luyện bằng cách sử dụng sự kết hợp của các quy tắc thống kê và thuật toán.
Có một số thuật toán subword tokenization thường được sử dụng trong NLP, nhưng hãy bắt đầu với WordPiece, thuật toán được sử dụng bởi bộ token hóa của BERT và DistilBERT. Cách dễ nhất để hiểu WordPiece hoạt động như thế nào là xem nó trong thực tế. 🤗 Transformers cung cấp một lớp tiện lợi là
AutoTokenizer, cho phép bạn nhanh chóng tải bộ tokenizer liên kết với một mô hình đã được huấn luyện trước. Chỉ cần gọi phương thứcfrom_pretrained(), cung cấp ID của mô hình trên Hub hoặc đường dẫn file cục bộ. Hãy bắt đầu bằng cách tải bộ token hóa cho DistilBERT:
1
2
3
4
5
from transformers import AutoTokenizer
model_ckpt = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
- Lớp AutoTokenizer thuộc về một nhóm lớn hơn các lớp “auto” có nhiệm vụ tự động lấy cấu hình của mô hình, trọng số đã được huấn luyện, hoặc từ vựng từ tên checkpoint. Điều này cho phép bạn nhanh chóng chuyển đổi giữa các mô hình, nhưng nếu muốn tải một lớp cụ thể theo cách thủ công, bạn cũng có thể như sau. Ví dụ, chúng ta có thể tải DistilBERT tokenizer như sau:
1
2
3
from transformers import DistilBertTokenizer
tokenizer = DistilBertTokenizer.from_pretrained(model_ckpt)
Khi bạn chạy phương thức
AutoTokenizer.from_pretrained()lần đầu tiên, bạn sẽ thấy một thanh tiến trình hiển thị các tham số của bộ token hóa được tải từ Hugging Face Hub. Khi chạy lại mã lần thứ hai, token hóa sẽ được tải từ bộ nhớ đệm (thường là~/.cache/huggingface).
- Hãy kiểm tra cách bộ tokenizer này hoạt động bằng cách cung cấp một ví dụ đơn giản: “Tokenizing text is a core task of NLP.”
1
2
3
4
5
encoded_text = tokenizer(text)
print(encoded_text)
# {'input_ids': [101, 19204, 6026, 3793, 2003, 1037, 4563, 4708, 1997, 17953,
# 2361, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
- Cũng giống như với việc token ký tự, chúng ta có thể thấy rằng các từ đã được ánh xạ thành các số nguyên duy nhất trong trường input_ids. Chúng ta sẽ thảo luận vai trò của trường
attention_masktrong phần tiếp theo. Bây giờ, khi đã cóinput_ids, chúng ta có thể chuyển đổi chúng thành các token bằng cách sử dụng phương thứcconvert_ids_to_tokens()củatokenizer:
1
2
3
4
tokens = tokenizer.convert_ids_to_tokens(encoded_text.input_ids)
print(tokens)
# ['[CLS]', 'token', '##izing', 'text', 'is', 'a', 'core', 'task', 'of', 'nl',
# '##p', '.', '[SEP]']
- Chúng ta có thể quan sát ba điều ở đây. Thứ nhất, một số token đặc biệt [CLS] và [SEP] đã được thêm vào để đánh dấu bắt đầu và kết thúc của chuỗi. Các token này có thể khác nhau tùy thuộc vào mô hình, nhưng chức năng chính của chúng là chỉ ra điểm bắt đầu và kết thúc của chuỗi. Thứ hai, các token đã được chuyển đổi thành chữ thường, đây là một tính năng của checkpoint cụ thể này. Cuối cùng, chúng ta có thể thấy rằng “tokenizing” và “NLP” đã được chia thành hai token, điều này có ý nghĩa vì chúng không phải là các từ phổ biến. Tiền tố ## trong ##izing và ##p cho biết rằng chuỗi trước đó không có khoảng trắng; bất kỳ token nào với tiền tố này nên được nối với token trước đó khi bạn chuyển đổi chúng thành một chuỗi. Lớp
AutoTokenizercó phương thứcconvert_tokens_to_string()để thực hiện điều này, vì vậy hãy áp dụng nó với các token của chúng ta:
1
2
print(tokenizer.convert_tokens_to_string(tokens))
# [CLS] tokenizing text is a core task of nlp. [SEP]
- Lớp
AutoTokenizercũng có một số thuộc tính khác cung cấp thông tin về tokenizer. Ví dụ, chúng ta có thể kiểm tra kích thước từ vựng:
1
tokenizer.vocab_size # 30522
- Maximum context size của mô hình:
1
tokenizer.model_max_length # 512
- Một thuộc tính thú vị khác cần biết là tên của các trường mà mô hình mong đợi trong quá trình truyền dữ liệu đầu vào:
1
2
tokenizer.model_input_names
# ['input_ids', 'attention_mask']
- Bây giờ chúng ta đã có hiểu biết cơ bản về quá trình tokenization cho một câu văn bản, hãy xem cách chúng ta có thể tokenization toàn bộ tập dữ liệu!
Khi sử dụng các mô hình được huấn luyện trước, điều cực kỳ quan trọng là bạn phải sử dụng chính tokenizer mà mô hình đã được huấn luyện cùng. Từ góc nhìn của mô hình, việc thay đổi tokenizer giống như thay đổi hoàn toàn từ vựng. Nếu mọi người xung quanh bạn bắt đầu tráo đổi ngẫu nhiên các từ như “nhà” với “mèo”, bạn cũng sẽ gặp khó khăn trong việc hiểu chuyện gì đang diễn ra!
Tokenizing the Whole Dataset
Để tokenize toàn bộ tập dữ liệu, chúng ta sẽ sử dụng phương thức
map()của đối tượng DatasetDict. Chúng ta sẽ gặp phương thức này nhiều lần trong sách này, vì nó cung cấp một cách thuận tiện để áp dụng một hàm xử lý cho từng phần tử trong tập dữ liệu. Như bạn sẽ sớm thấy, phương thứcmap()cũng có thể được sử dụng để tạo các hàng và cột mới.Để bắt đầu, việc đầu tiên chúng ta cần là một hàm xử lý để tokenize các ví dụ của chúng ta, như sau:
1
2
def tokenize(batch):
return tokenizer(batch["text"], padding=True, truncation=True)
- Hàm này áp dụng tokenizer lên một batch;
padding=Truesẽ điền thêm các số 0 để đảm bảo rằng tất cả các chuỗi có cùng độ dài với chuỗi dài nhất trong batch, vàtruncation=Truesẽ cắt ngắn các chuỗi vượt quá độ maximum context size của mô hình. Để thấytokenize()hoạt động, hãy thử áp dụng nó với hai ví dụ từ tập huấn luyện:
1
2
3
4
5
6
7
8
print(tokenize(emotions["train"][:2]))
# {'input_ids': [[101, 1045, 2134, 2102, 2514, 26608, 102, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0], [101, 1045, 2064, 2175, 2013, 3110, 2061, 20625, 2000,
# 2061, 9636, 17772, 2074, 2013, 2108, 2105, 2619, 2040, 14977, 1998, 2003, 8300,
# 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
# 1, 1]]}
- Ở đây, chúng ta có thể thấy kết quả của việc padding: phần tử đầu tiên của input_ids ngắn hơn phần tử thứ hai, vì vậy các số 0 đã được thêm vào để làm cho chúng có cùng độ dài. Các số 0 này tương ứng với token đặc biệt [PAD] trong từ vựng, và bộ các token đặc biệt này cũng bao gồm các token [CLS] và [SEP] mà chúng ta đã thấy trước đó:
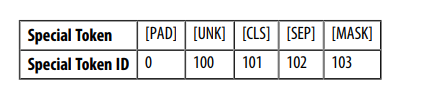
- Ngoài ra, lưu ý rằng bên cạnh việc trả về văn bản đã được mã hóa dưới dạng
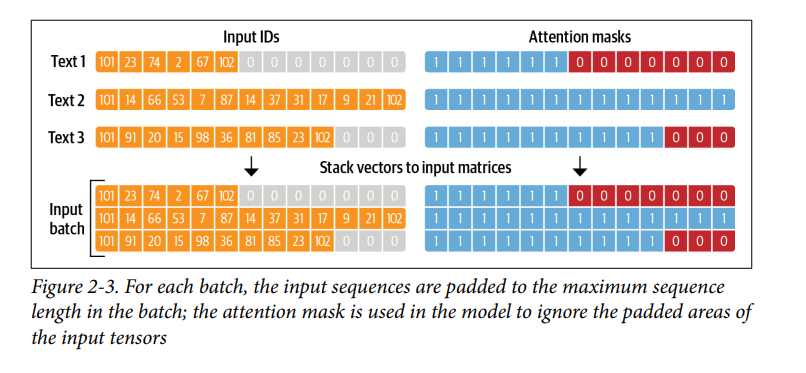
input_ids,tokenizercòn trả về một danh sách các mảngattention_mask. Điều này nhằm ngăn mô hình bị nhầm lẫn bởi các token padding (các số 0 tronginput_ids);attention_maskcho phép mô hình bỏ qua các token padding này. Hình 2-3 cung cấp hình ảnh minh họa về cách cácinput_idsvàattention_maskđược áp dụng khi token padding:
- Khi chúng ta đã định nghĩa một hàm xử lý xong, chuún ta có thể áp dụng nó cho tất cả các phần trong tập dữ liệu chỉ với một dòng lệnh:
1
emotions_encoded = emotions.map(tokenize, batched=True, batch_size=None)
Theo mặc định, phương thức
map()hoạt động trên từng ví dụ riêng lẻ trong tập dữ liệu. Do đó, khi đặtbatched=True, phương thức này sẽ encode theo từng batch. Vì chúng ta đã đặtbatch_size=None, hàmtokenize()của chúng ta sẽ được áp dụng trên toàn bộ tập dữ liệu dưới dạng một batch duy nhất. Điều này đảm bảo rằng các tensor đầu vào (input_ids) và mặt nạ chú ý (attention_mask) có cùng kích thước trên toàn bộ tập dữ liệu.Chúng ta có thể thấy rằng thao tác này đã thêm các cột mới là
input_idsvàattention_maskvào tập dữ liệu:
1
2
print(emotions_encoded["train"].column_names)
# ['text', 'label', 'input_ids', 'attention_mask']
3. Training a Text Classifier
- Như đã thảo luận trong Chương 1, các mô hình như DistilBERT được đào tạo trước để dự đoán các từ được che giấu trong một chuỗi văn bản. Tuy nhiên, chúng ta không thể sử dụng các mô hình ngôn ngữ này trực tiếp để phân loại văn bản; chúng ta cần sửa đổi chúng một chút. Để hiểu những sửa đổi nào là cần thiết, chúng ta hãy xem kiến trúc của một mô hình dựa trên encoder-based như DistilBERT, được mô tả trong Hình 2-4.
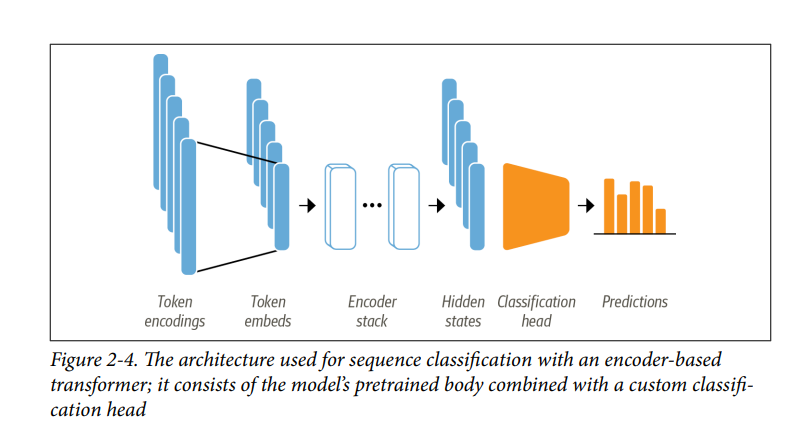
- Đầu tiên, văn bản được tokenized và biểu diễn dưới dạng one-hot vectors được gọi là token encodings. Kích thước của tokenizer vocabulary xác định số chiều của token encodings và nó thường bao gồm 20k–200k token duy nhất. Tiếp theo, các token encodings này được chuyển đổi thành token embeddings, là các vectơ có số chiều thấp hơn. Sau đó, các token embeddings được chuyển qua các lớp encoder block để tạo ra hidden state cho mỗi input token. Đối với mục tiêu pretrained của language modeling (Đối với mô hình DistilBERT, nó là đoán các token mask), mỗi hidden state được đưa vào một lớp dự đoán các mask input token. Đối với nhiệm vụ phân loại, chúng ta thay thế lớp language moedeling bằng lớp phân loại.
Trong thực tế, PyTorch bỏ qua bước tạo one-hot vectơ cho token encodings vì nhân một ma trận với one-hot vector cũng giống như chọn một cột từ ma trận. Điều này có thể được thực hiện trực tiếp bằng cách lấy cột có token ID từ ma trận. Chúng ta sẽ thấy điều này trong Chương 3 khi chúng ta sử dụng nn.Embedding.
- Chúng ta có hai lựa chọn để train một mô hình phân loại trên bộ dữ liệu Twitter:
- Feature extraction: Chúng ta sử dụng các hidden state như feature và chỉ train bộ phân loại mà không train trọng số của pretrained model (trọng số của pretrained model được đóng băng).
- Fine-tuning: Chúng ta train toàn bộ mô hình, có cập nhật cả trọng số của pretrained model.
- Trong các phần sau, chúng ta khám phá cả hai lựa chọn cho DistilBERT và xem xét sự đánh đổi của chúng.
Transformers as Feature Extractors
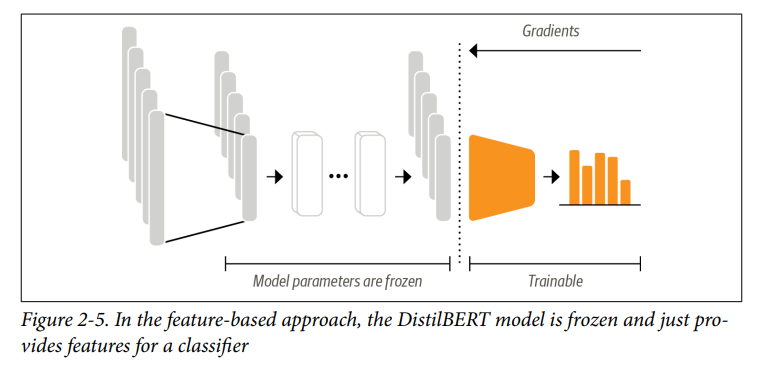
- Sử dụng Transformers làm Feature Extractors khá đơn giản. Như thể hiện trong Hình 2-5, chúng ta đóng băng trọng số của pretrained model trong quá trình train và sử dụng các hidden state làm feature cho bộ phân loại. Ưu điểm của cách tiếp cận này là chúng ta có thể nhanh chóng train một mô hình nhỏ hoặc mô hình nông (shallow model). Một mô hình như vậy có thể là một neural classification layer hoặc một phương pháp không dùng đến gradient, ví dụ như random forest. Phương pháp như random forest đặc biệt thuận tiện nếu GPU không khả dụng, vì các hidden state chỉ cần được tính toán trước một lần.
Using pretrained models
- Chúng ta sẽ sử dụng một auto class tiện lợi khác từ 🤗 Transformers có tên là
AutoModel. Tương tự như lớpAutoTokenizer,AutoModelcó một phương thứcfrom_pretrained()để tải trọng số của một pretrained model. Hãy sử dụng phương thức này để tải DistilBERT checkpoint:
1
2
3
4
5
from transformers import AutoModel
model_ckpt = "distilbert-base-uncased"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModel.from_pretrained(model_ckpt).to(device)
- Ở đây chúng ta đã sử dụng PyTorch để kiểm tra xem GPU có sẵn hay không. Điều này đảm bảo mô hình sẽ chạy trên GPU nếu chúng ta có. Nếu không, mô hình sẽ chạy trên CPU, có thể chậm hơn đáng kể.
- Lớp
AutoModelchuyển đổi token encoding thành embedding và sau đó cho chúng qua encoder stack để trả về các hidden state. Hãy xem cách chúng ta có thể trích xuất các trạng thái này từ kho dữ liệu của mình.
Extracting the last hidden states
- Để khởi động, hãy truy xuất last hidden states cho một chuỗi duy nhất. Điều đầu tiên chúng ta cần làm là encode chuỗi và chuyển đổi các token thành tensor PyTorch. Điều này có thể được thực hiện bằng cách cung cấp tham số
return_tensors="pt"chotokenizernhư sau:
1
2
3
4
text = "this is a test"
inputs = tokenizer(text, return_tensors = "pt")
print(f"Input tensor shape: {inputs['input_ids'].size()}")
# Input tensor shape: torch.Size([1, 6])
- Như chúng ta có thể thấy, tensor kết quả có kích thước là [batch_size, n_tokens]. Bây giờ chúng ta đã có các encoding dưới dạng tensor, bước cuối cùng là đặt chúng trên cùng một
devicevới mô hình và chuyển các đầu vào như sau:
1
2
3
4
5
6
7
8
9
10
11
12
inputs = {k:v.to(device) for k,v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
print(outputs)
# BaseModelOutput(last_hidden_state=tensor([[[-0.1565, -0.1862, 0.0528, ...,
# -0.1188, 0.0662, 0.5470],
# [-0.3575, -0.6484, -0.0618, ..., -0.3040, 0.3508, 0.5221],
# [-0.2772, -0.4459, 0.1818, ..., -0.0948, -0.0076, 0.9958],
# [-0.2841, -0.3917, 0.3753, ..., -0.2151, -0.1173, 1.0526],
# [ 0.2661, -0.5094, -0.3180, ..., -0.4203, 0.0144, -0.2149],
# [ 0.9441, 0.0112, -0.4714, ..., 0.1439, -0.7288, -0.1619]]],
# device='cuda:0'), hidden_states=None, attentions=None)
- Ở đây chúng ta đã sử dụng trình quản lý ngữ cảnh
torch.no_grad()để vô hiệu hóa tính toán tự động của gradient. Điều này rất hữu ích cho suy luận vì nó làm giảm lượng bộ nhớ của các tính toán. Tùy thuộc vào cấu hình mô hình, đầu ra có thể chứa một số đối tượng, chẳng hạn như hidden state, losses hoặc attention, được sắp xếp trong một lớp tương tự như một bộ có tên trong Python. Trong ví dụ của chúng ta, đầu ra của mô hình là một thực thể củaBaseModelOutput và chúng ta có thể chỉ cần truy cập các thuộc tính của nó theo tên. Mô hình hiện tại chỉ trả về một thuộc tính, đó là last hidden state, vì vậy hãy kiểm tra kích thước của nó:
1
2
outputs.last_hidden_state.size()
# torch.Size([1, 6, 768])
- Nhìn vào hidden state tensor, chúng ta thấy rằng nó có kích thước là [batch_size, n_tokens, hidden_dim]. Nói cách khác, một vectơ 768 chiều được trả về cho mỗi trong số 6 input token. Đối với các tác vụ phân loại, thông thường chúng ta chỉ sử dụng hidden state được liên kết với token [CLS] làm feature đầu vào. Vì token này xuất hiện ở đầu mỗi chuỗi, chúng ta có thể trích xuất nó bằng cách chỉ cần gọi chỉ số của outputs.last_hidden_state như sau:
1
2
output.last_hidden_state[:,0].size()
# torch.Size([1, 768])
- Bây giờ chúng ta đã biết cách lấy last hidden state cho một chuỗi duy nhất; Hãy làm tương tự cho toàn bộ tập dữ liệu bằng cách tạo ra một cột hidden_state mới lưu trữ tất cả các vector này. Như chúng ta đã làm với tokenizer, chúng ta sẽ sử dụng phương thức
map()củaDatasetDictđể trích xuất tất cả các hidden state trong một lần. Điều đầu tiên chúng ta cần làm là bao bọc các bước trước đó trong một hàm xử lý:
1
2
3
4
5
def extract_hidden_states(batch):
inputs = {k:v.to(device) for k,v in batch.items() if k in tokenizer.model_input_names}
with torch.no_grad():
last_hidden_state = model(**inputs).last_hidden_state
return {"hidden_state": last_hidden_state[:,0].cpu().numpy()}
- Sự khác biệt duy nhất giữa hàm này và logic trước đó của chúng ta là bước cuối cùng khi chúng ta đặt last hidden state trở lại CPU dưới dạng mảng NumPy. Phương thức
map()yêu cầu hàm xử lý trả về các đối tượng Python hoặc NumPy khi chúng ta đang sử dụng đầu vào là batch. - Vì mô hình của chúng ta mong đợi tensor làm đầu vào, điều tiếp theo cần làm là chuyển đổi các cột
input_idsvàattention_masksang định dạng “torch”, như sau:
1
emotions_encoded.set_format("torch", columns = ["input_ids", "attention_mask", "label"])
- Sau đó, chúng ta có thể trích xuất các hidden state trong một lần:
1
emotions_hidden = emotions_encoded.map(extract_hidden_states, batched = True)
- Lưu ý rằng chúng ta đã không đặt
batch_size=Nonetrong trường hợp này, có nghĩa là mặc địnhbatch_size=1000được sử dụng thay thế. Đúng như dự đoán, việc áp dụng hàmextract_ hidden_ states()đã thêm một cộthidden_statemới vào tập dữ liệu của chúng ta:
1
2
emotions_hidden["train"].column_names
# ['attention_mask', 'hidden_state', 'input_ids', 'label', 'text']
- Bây giờ chúng ta đã có các hidden states được liên kết với mỗi tweet, bước tiếp theo là train một bộ phân loại trên chúng. Để làm được điều đó, chúng ta sẽ cần một ma trận tính feature — chúng ta hãy xem xét ở phần tiếp theo.
Creating a feature matrix
- Tập dữ liệu giờ chứa tất cả thông tin chúng ta cần để train một bộ phân loại. Chúng ta sẽ sử dụng các hidden states làm input features và label làm target. Chúng ta có thể dễ dàng tạo các mảng tương ứng ở định dạng Scikit-learn nổi tiếng như sau:
1
2
3
4
5
6
7
import numpy as np
X_train = np.array(emotions_hidden["train"]["hidden_state"])
X_valid = np.array(emotions_hidden["validation"]["hidden_state"])
y_train = np.array(emotions_hidden["train"]["label"])
y_valid = np.array(emotions_hidden["validation"]["label"])
X_train.shape, X_valid.shape
# ((16000, 768), (2000, 768)
- Trước khi chúng ta train một mô hình về các hidden states, bạn nên thực hiện kiểm tra nhanh để đảm bảo rằng hidden states cung cấp một biểu diễn hữu ích về cảm xúc mà chúng ta muốn phân loại. Trong phần tiếp theo, chúng ta sẽ thấy cách trực quan hóa các features một cách nhanh chóng.
Visualizing the training set
- Vì việc trực quan hóa các hidden state trong 768 chiều là rất khó, chúng ta sẽ sử dụng thuật toán UMAP để chiếu các vectơ xuống 2D. Vì UMAP hoạt động tốt nhất khi các feature được scaled để nằm trong khoảng [0,1], trước tiên chúng ta sẽ áp dụng
MinMaxScalervà sau đó sử dụng triển khai UMAP từ thư việnumap-learnđể giảm số chiều các hidden states:
1
2
3
4
5
6
7
from umap import UMAP # !pip install umap-learn
from sklearn.preprocessing import MinMaxScaler
X_scaled = MinMaxScaler().fit_transform(X_train)
mappper = UMAP(n_components=2, metric = "cosine").fit(X_scaled)
df_emb = pd.DataFrame(mapper.embedding_, columns = ["X","Y"])
df_emb["label"] = y_train
df_emb.head()
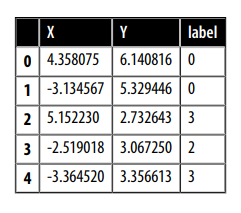
- Kết quả là một mảng có cùng số lượng mẫu đào tạo, nhưng chỉ có 2 chiều thay vì 768 mà chúng ta đã bắt đầu ! Hãy nghiên cứu dữ liệu nén thêm một chút và vẽ mật độ của các điểm cho từng danh mục riêng biệt:
1
2
3
4
5
6
7
8
9
10
11
12
fig, axes = plt.subplots(2, 3, figsize=(7,5))
axes = axes.flatten()
cmaps = ["Greys", "Blues", "Oranges", "Reds", "Purples", "Greens"]
labels = emotions["train"].features["label"].names
for i, (label, cmap) in enumerate(zip(labels, cmaps)):
df_emb_sub = df_emb.query(f"label == {i}")
axes[i].hexbin(df_emb_sub["X"], df_emb_sub["Y"], cmap=cmap,gridsize=20, linewidths=(0,))
axes[i].set_title(label)
axes[i].set_xticks([]), axes[i].set_yticks([])
plt.tight_layout()
plt.show()
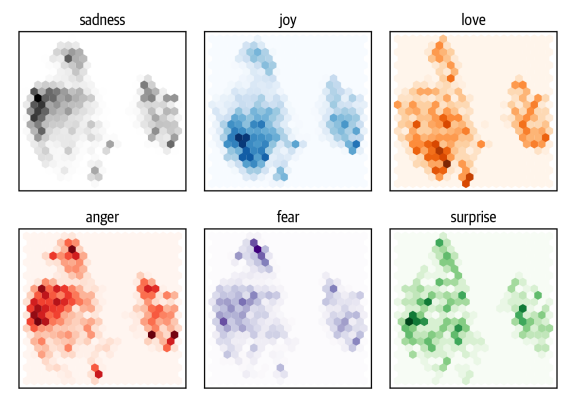
- Từ đồ thị này, chúng ta có thể thấy một số mô hình rõ ràng: những cảm xúc tiêu cực như sadness, anger và fear đều chiếm các vùng tương tự với sự phân bố hơi khác nhau. Mặt khác, joy và love được tách biệt tốt với những cảm xúc tiêu cực và cũng chia sẻ một không gian tương tự. Cuối cùng, surprise nằm rải rác khắp nơi. Mặc dù chúng ta có thể hy vọng vào một số sự tách biệt, nhưng điều này không được đảm bảo vì mô hình không được train để biết sự khác biệt giữa những cảm xúc này. Nó chỉ học chúng một cách ngầm định bằng cách đoán các từ được che giấu trong văn bản.
- Bây giờ chúng ta đã có được một số thông tin chi tiết về các features của bộ dữ liệu, giờ hãy train một mô hình trên đó.
Training a simple classifier
- Chúng ta đã thấy rằng các hidden state có phần khác nhau giữa các cảm xúc, mặc dù đối với một số trong số chúng không có ranh giới rõ ràng. Hãy sử dụng các hidden state này để train một mô hình hồi quy logistic với Scikit-learn. Train một mô hình đơn giản như vậy rất nhanh và không yêu cầu GPU:
1
2
3
4
5
6
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(max_iter = 3000)
lr_clf.fit(X_train, y_train)
lr_clf.score(X_valid, y_valid)
# 0.633
- Nhìn vào độ chính xác, có vẻ như mô hình của chúng ta chỉ tốt hơn một chút so với dự đoán ngẫu nhiên - nhưng vì chúng ta đang xử lý một bộ dữ liệu đa lớp không cân bằng, nó thực sự tốt hơn đáng kể. Chúng ta có thể kiểm tra xem mô hình có tốt hay không bằng cách so sánh nó với một baseline đơn giản. Trong Scikit-learn có
DummyClassifiercó thể được sử dụng để xây dựng một bộ phân loại với các phương pháp phỏng đoán đơn giản như luôn chọn lớp đa số hoặc luôn chọn một lớp ngẫu nhiên. Trong trường hợp này, heuristic hoạt động tốt nhất là luôn chọn lớp thường xuyên nhất, mang lại độ chính xác khoảng $35\%$:
1
2
3
4
5
6
from sklearn.dummy import DummyClassifier
dummy_clf = DummyClassifier(strategy = "most_frequent")
dummy_clf.fit(X_train, y_train)
dummy_clf.score(X_valid, y_valid)
# 0.352
- Vì vậy, bộ phân loại đơn giản của chúng ta vớ DistilBERT embedding tốt hơn đáng kể so với baseline. Chúng ta có thể điều tra thêm hiệu suất của mô hình bằng cách xem confusion matrix của bộ phân loại, cho chúng ta biết mối quan hệ giữa nhãn thực tế và nhãn dự đoán:
1
2
3
4
5
6
7
8
9
10
11
12
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
def plot_confusion_matrix(y_preds, y_true, labels):
cm = confusion_matrix(y_true, y_preds, normalize = "true")
fig, ax = plt.subplots(figsize = (6,6))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels = labels)
disp.plot(cmap = "Blues", values_format = ".2f", ax = ax, colorbar = False)
plt.title("Normalized confusion matrix")
plt.show()
y_preds = lr_clf.predict(X_valid)
plot_confusion_matrix(y_preds,y_valid, labels)
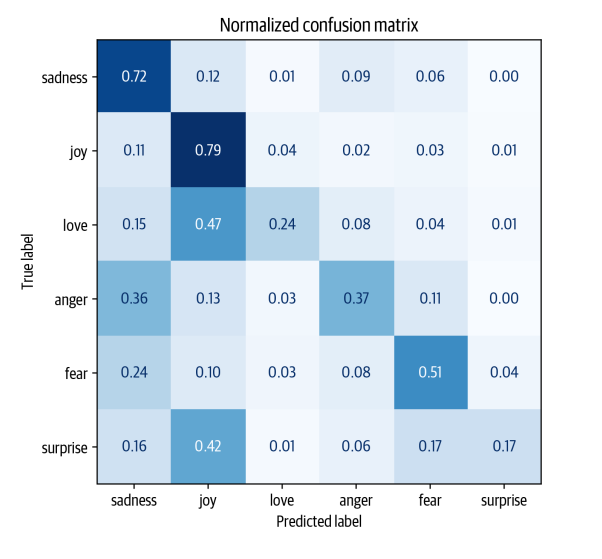
- Chúng ta có thể thấy rằng anger và fear thường bị nhầm lẫn với sadness, điều này phù hợp với quan sát mà chúng ta đã trực quan hóa embeddings. Ngoài ra, love và surprise thường bị nhầm lẫn với joy.
- Trong phần tiếp theo, chúng ta sẽ khám phá cách tiếp cận fine-tuning, dẫn đến hiệu suất phân loại vượt trội. Tuy nhiên, điều quan trọng cần lưu ý là làm điều này đòi hỏi nhiều tài nguyên tính toán hơn, chẳng hạn như GPU, có thể không có sẵn trong máy tính của bạn. Trong những trường hợp như thế này, cách tiếp cận dựa trên features có thể là một sự thỏa hiệp tốt giữa việc thực hiện học máy truyền thống và học sâu.
Fine-Tuning Transformers
- Bây giờ chúng ta hãy khám phá những gì cần thiết để fine-tune transformer từ đầu đến cuối. Với cách tiếp cận fine-tune, chúng ta không sử dụng các hidden state như các feature cố định, mà thay vào đó train chúng như trong Hình 2-6. Điều này đòi hỏi đầu phân loại phải có thể phân biệt, đó là lý do tại sao phương pháp này thường sử dụng neural network để phân loại.
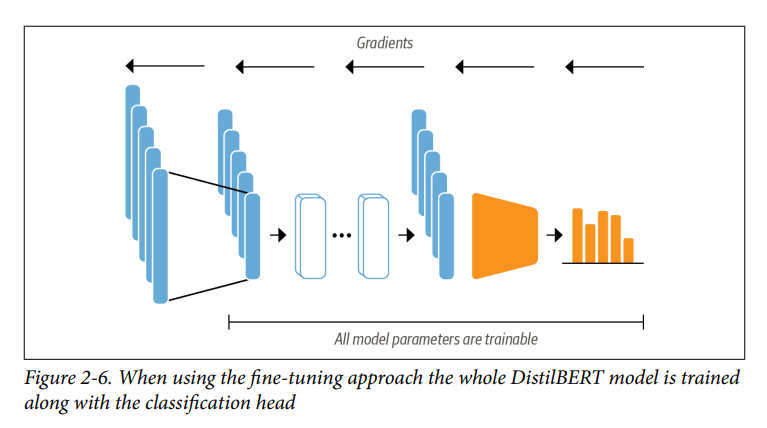
- Training các hidden states đóng vai trò là đầu vào cho mô hình phân loại sẽ giúp chúng ta tránh được vấn đề làm việc với dữ liệu có thể không phù hợp với nhiệm vụ phân loại. Thay vào đó, các hidden state ban đầu thích ứng trong quá trình train để giảm loss của mô hình và do đó tăng hiệu suất của nó.
- Chúng ta sẽ sử dụng API Trainer từ 🤗 Transformers để đơn giản hóa training loop. Hãy xem các thành phần chúng ta cần thiết lập !
Loading a pretrained model
- Điều đầu tiên chúng ta cần là một mô hình pretrained DistilBERT giống như mô hình chúng ta đã sử dụng trong cách tiếp cận dựa trên features. Sửa đổi nhỏ duy nhất là chúng ta sử dụng mô hình
AutoModelForSequenceClassificationthay vìAutoModel. Sự khác biệt là mô hìnhAutoModelForSequenceClassificationcó classification head ở đầu ra của pretrained model, có thể dễ dàng train với mô hình baseline. Chúng ta chỉ cần chỉ định có bao nhiêu label mà mô hình phải dự đoán (6 trong trường hợp của chúng ta), vì điều này quyết định số lượng đầu ra mà đầu phân loại có:
1
2
3
4
from transformers import AutoModelForSequenceClassification
num_labels = 6
model = (AutoModelForSequenceClassification.from_pretrained(model_ckpt, num_labels = num_labels).to(device))
- Bạn sẽ thấy cảnh báo rằng một số phần của mô hình được khởi tạo ngẫu nhiên. Điều này là bình thường vì classification head vẫn chưa được train. Bước tiếp theo là xác định các chỉ số mà chúng ta sẽ sử dụng để đánh giá hiệu suất của mô hình trong quá trình fine-tuning.
Defining the performance metrics
- Để theo dõi các metrics trong quá trình train, chúng ta cần xác định một hàm
compute_metrics()choTrainer. Hàm này nhận một đối tượngEvalPrediction(là một tuple với các thuộc tínhpredictionsvàlabel_ids) và cần trả về một từ điển ánh xạ tên của từng metrics với giá trị của nó. Đối với ứng dụng của chúng ta, chúng ta sẽ tính $F_1$ scores và accuracy, recall, precision của mô hình:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
# Tính các metrics
f1 = f1_score(labels, preds, average="weighted")
acc = accuracy_score(labels, preds)
precision = precision_score(labels, preds, average="weighted")
recall = recall_score(labels, preds, average="weighted")
return {
"accuracy": acc,
"f1": f1,
"precision": precision,
"recall": recall
}
- Với dataset và metrics đã sẵn sàng, chúng ta chỉ có hai điều cuối cùng cần quan tâm trước khi xác định lớp
Trainer:
- Đăng nhập tài khoản trên Hugging Face Hub. Điều này sẽ cho phép bạn đẩy mô hình fine-tuned của mình vào tài khoản của bạn trên Hub và chia sẻ nó với cộng đồng.
- Xác định tất cả các siêu tham số cho quá trình chạy.
- Chúng ta sẽ xem xét các bước này trong phần tiếp theo.
Training the model
- Nếu bạn đang chạy code trong Jupyter notebook, bạn có thể đăng nhập vào Hub bằng hàm trợ giúp sau:
1
2
from huggingface_hub import notebook_login
notebook_login()
- Code này sẽ hiển thị một tiện ích trong đó bạn có thể nhập tên người dùng và mật khẩu của mình hoặc access token có đặc quyền write. Bạn có thể tìm thấy chi tiết về cách tạo access token trong tài liệu Hub. Nếu bạn đang làm việc trên ternimal, bạn có thể đăng nhập bằng cách chạy lệnh sau:
1
huggingface-cli login
- Để xác định các training parameters, chúng ta sử dụng lớp
TrainingArguments. Lớp này lưu trữ rất nhiều thông tin và cho phép bạn kiểm soát chi tiết quá trình training và evaluation. Tham số quan trọng nhất cần chỉ định làoutput_dir, đó là nơi lưu trữ tất cả các tạo tác từ đào tạo. Đây là một ví dụ về `TrainingArguments:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from transformers import Trainer, TrainingArguments
batch_size = 64
logging_steps = len(emotions_encoded["train"]) // batch_size # 250
model_name = f"{model_ckpt}-finetuned-emotion"
training_args = TrainingArguments(output_dir = model_name,
num_train_epochs = 20,
learning_rate = 2e-5,
per_device_train_batch_size = batch_size,
per_device_eval_batch_size = batch_size,
weight_decay = 0.01,
eval_strategy = "epoch",
disable_tqdm = False,
logging_steps = logging_steps,
push_to_hub = True,
log_level = "error")
- Ở đây chúng ta cũng đặt tham số batch size, learning rate và số epoch, đồng thời chỉ định tải best model vào cuối quá trình training. Với thành phần cuối cùng này, chúng ta có thể khởi tạo và fine-tune mô hình của mình với
Trainer:
1
2
3
4
5
6
7
8
from transformers import Trainer
trainer = Trainer(model = model, args = training_args,
compute_metrics = compute_metrics,
train_dataset = emotions_encoded["train"],
eval_dataset = emotions_encoded["validation"],
tokenizer = tokenizer)
trainer.train()
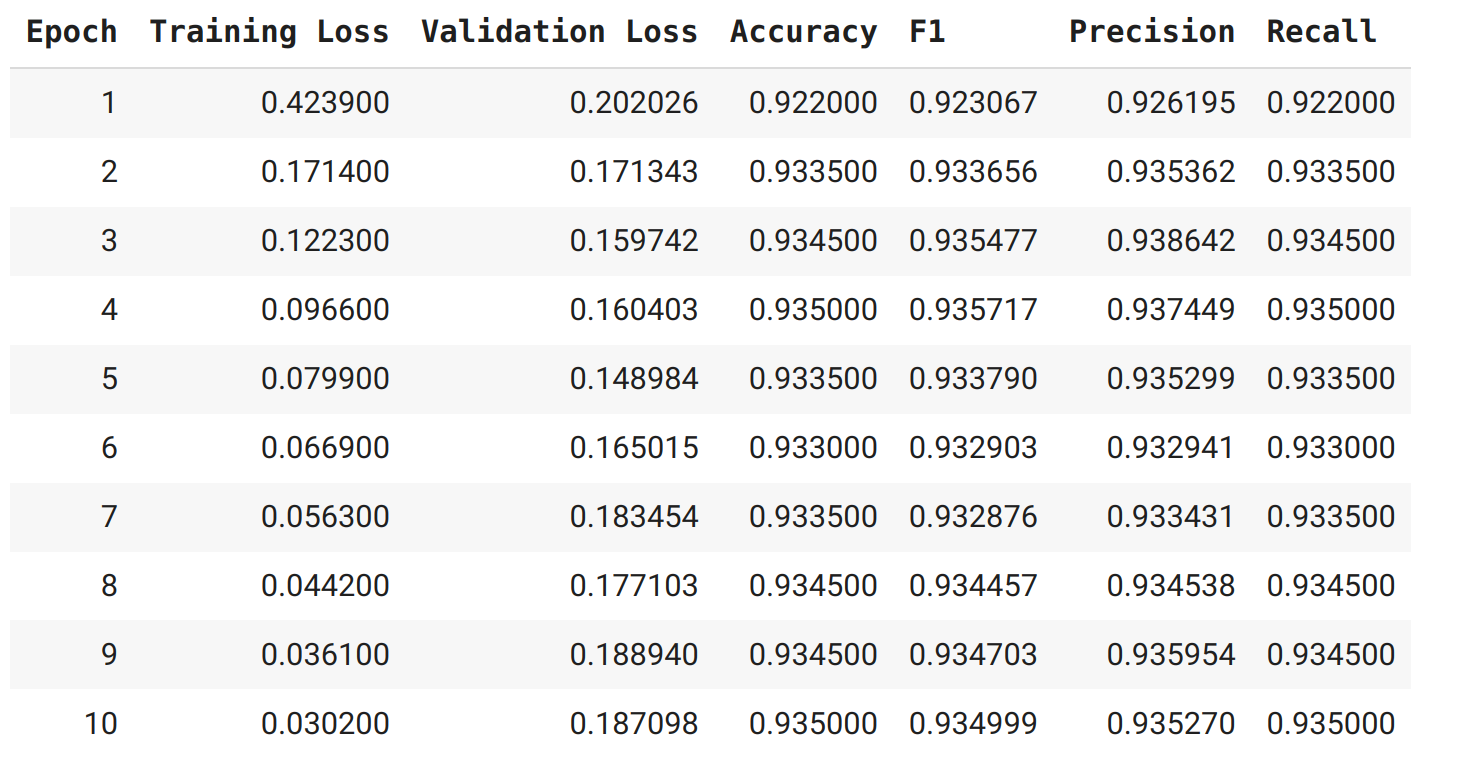
- Nhìn vào logs, chúng ta có thể thấy rằng mô hình đạt các metrics xấp xỉ $92\%$ — đây là một cải tiến đáng kể so với cách tiếp cận dựa trên feature !
- Chúng ta có thể xem xét chi tiết hơn các training metrics bằng cách tính toán confusion matrix. Để trực quan hóa confusion matrix, trước tiên chúng ta cần lấy các dự đoán trên tập valdidation. Phương thức
predict()của lớpTrainertrả về một số đối tượng hữu ích mà chúng ta có thể sử dụng để đánh giá:
1
preds_output = trainer.predict(emotions_encoded["validation"])
- Đầu ra của phương thức
predict()là một đối tượngPredictionOutputchứa các mảngpredictionsvàlabel_ids, cùng với các metrics mà chúng tôi đã pass chotrainer. Ví dụ: metrics trên tập validation có thể được truy cập như sau:
1
2
3
4
5
6
7
preds_output.metrics
# {'test_loss': 0.22047173976898193,
# 'test_accuracy': 0.9225,
# 'test_f1': 0.9225500751072866,
# 'test_runtime': 1.6357,
# 'test_samples_per_second': 1222.725,
# 'test_steps_per_second': 19.564}
- Nó cũng chứa các dự đoán thô cho mỗi lớp. Chúng ta có thể decode các dự đoán một cách tham lam bằng cách sử dụng
np.argmax(). Điều này mang lại các nhãn dự đoán và có cùng định dạng với các nhãn được trả về bởi các mô hình Scikit-learn trong cách tiếp cận dựa trên feature:
1
y_preds = np.argmax(preds_output.predictions, axis = 1)
- Với các dự đoán, chúng ta có thể vẽ lại confusion matrix:
1
plot_confusion_matrix(y_preds, y_valid, labels)
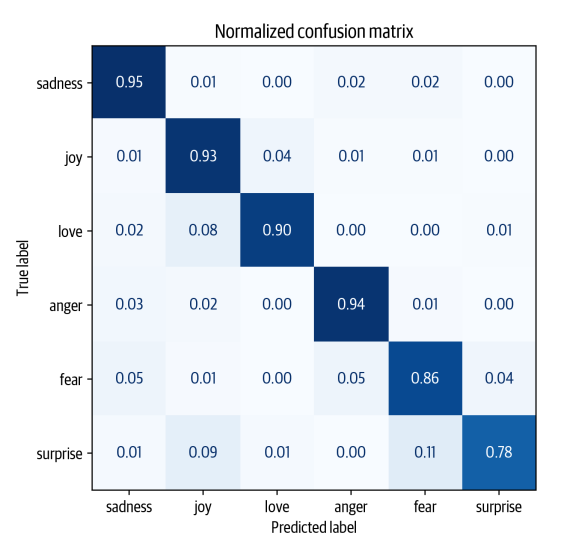
- Điều này gần với confusion matrix có đường chéo lý tưởng. Phạm trù love vẫn thường bị nhầm lẫn với joy, điều này dường như tự nhiên. Surprise cũng thường bị nhầm lẫn với joy, hoặc nhầm lẫn với fear. Nhìn chung, hiệu suất của mô hình có vẻ khá tốt, chúng ta hãy tìm hiểu sâu hơn một chút về các loại lỗi mà mô hình của chúng ta có thể mắc phải.
Error analysis
- Trước khi tiếp tục, chúng ta nên điều tra các dự đoán của mô hình thêm một chút. Một kỹ thuật đơn giản nhưng mạnh mẽ là sắp xếp validation samples theo model loss. Khi chúng ta chuyển label trong quá trình forawrd pass, loss sẽ tự động được tính toán và trả về. Dưới đây là một hàm trả về loss cùng với label dự đoán:
1
2
3
4
5
6
7
8
9
10
from torch.nn.functional import cross_entropy
def forward_pass_with_label(batch):
inputs = {k:v.to(device) for k,v in batch.items() if k in tokenizer.model_input_names}
with torch.no_grad():
output = model(**inputs)
pred_label = torch.argmax(output.logits, axis = -1)
loss = cross_entropy(output.logits, batch["label"].to(device), reduction = "none")
return {"loss": loss.cpu().numpy(),
"predicted_label": pred_label.cpu().numpy()}
- Sử dụng phương thức
map()một lần nữa, chúng ta có thể áp dụng hàm này để lấy loss cho tất cả các samples:
1
2
3
4
# Convert our dataset back to PyTorch tensors
emotions_encoded.set_format("torch",columns=["input_ids", "attention_mask", "label"])
# Compute loss values
emotions_encoded["validation"] = emotions_encoded["validation"].map(forward_pass_with_label, batched=True, batch_size=16)
- Cuối cùng, chúng ta tạo một
DataFramevới các text, losses và predicted/true label:
1
2
3
4
5
emotions_encoded.set_format("pandas")
cols = ["text", "label", "predicted_label", "loss"]
df_test = emotions_encoded["validation"][:][cols]
df_test["label"] = df_test["label"].apply(label_int2str)
df_test["predicted_label"] = (df_test["predicted_label"].apply(label_int2str))
- Bây giờ chúng ta có thể dễ dàng sắp xếp
emotions_encodedtheo loss với thứ tự tăng dần hoặc giảm dần. Mục tiêu của bài tập này là phát hiện một trong những điều sau:
- Wrong labels: Mọi quy trình thêm nhãn vào dữ liệu đều có thể có sai sót. Người chú thích có thể mắc lỗi hoặc không đồng ý, trong khi các nhãn được suy ra từ các tính năng khác có thể sai. Nếu dễ dàng tự động chú thích dữ liệu, thì chúng ta sẽ không cần một mô hình để làm điều đó. Vì vậy, việc có một số ví dụ được dán nhãn sai là điều bình thường. Với cách tiếp cận này, chúng ta có thể nhanh chóng tìm và sửa chúng.
- Quirks of the dataset: Data trong thực tế luôn có một chút lộn xộn. Khi làm việc với văn bản, các ký tự hoặc chuỗi đặc biệt trong đầu vào có thể có tác động lớn đến các định vị của mô hình. Kiểm tra các dự đoán yếu nhất của mô hình có thể giúp xác định các đặc điểm như vậy và làm sạch dữ liệu hoặc chèn các ví dụ tương tự có thể làm cho mô hình mạnh mẽ hơn.
- Trước tiên, chúng ta hãy xem xét các samples có loss cao nhất:
1
df_test.sort_values("loss", ascending=False).head(10)
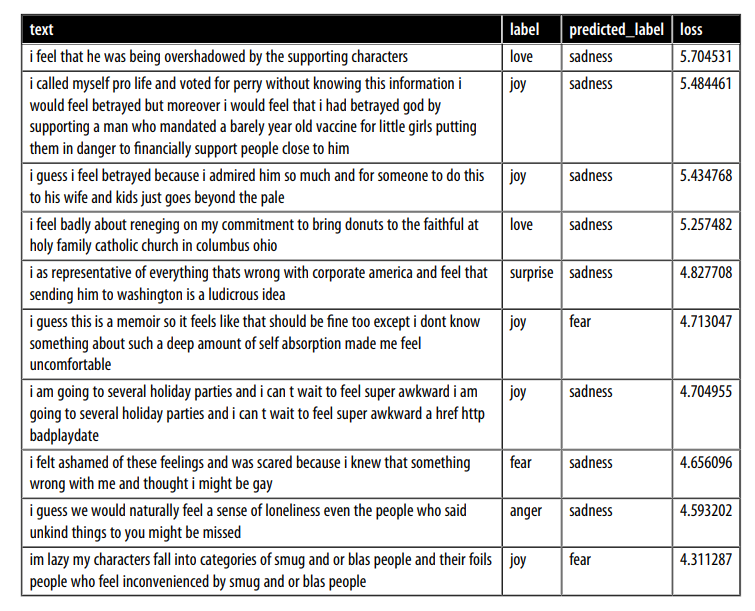
- Chúng ta có thể thấy rõ rằng mô hình dự đoán một số nhãn không chính xác. Mặt khác, có vẻ như có khá nhiều ví dụ không có lớp rõ ràng, có thể bị dán nhãn sai hoặc yêu cầu một lớp mới hoàn toàn. Đặc biệt, joy dường như bị dán nhãn sai nhiều lần. Với thông tin này, chúng ta có thể tinh chỉnh bộ dữ liệu, điều này thường có thể dẫn đến tăng hiệu suất lớn (hoặc nhiều hơn) như có nhiều dữ liệu hơn hoặc mô hình lớn hơn !
- Khi nhìn vào các samples có loss thấp nhất, chúng ta quan sát thấy rằng mô hình dường như tự tin nhất khi dự đoán lớp sadness. Các mô hình deep learning đặc biệt giỏi trong việc tìm và khai thác các phím tắt để đưa ra dự đoán. Vì lý do này, cũng nên đầu tư thời gian vào việc xem xét các ví dụ mà mô hình tự tin nhất, để chúng ta có thể tự tin rằng mô hình không khai thác không đúng cách một số feature nhất định của văn bản. Vì vậy, chúng ta cũng hãy xem xét các dự đoán có mức loss nhỏ nhất:
1
df_test.sort_values("loss", ascending=True).head(10)
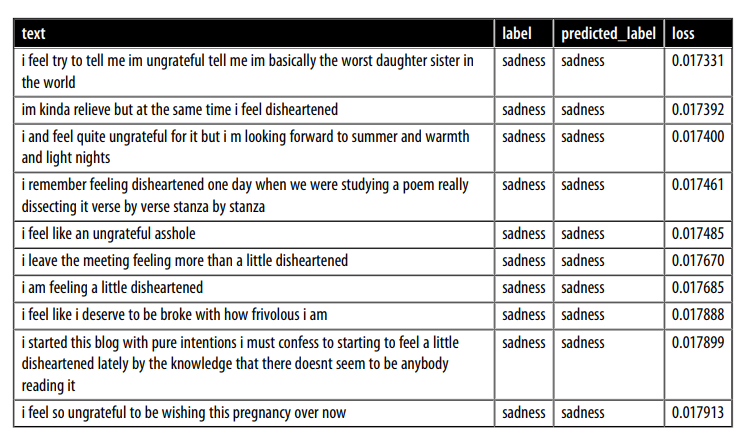
- Bây giờ chúng ta biết rằng joy đôi khi bị dán nhãn sai và mô hình tự tin nhất trong việc dự đoán sadness của nhãn hiệu. Với thông tin này, chúng ta có thể thực hiện các cải tiến có mục tiêu đối với bộ dữ liệu của mình và cũng theo dõi lớp mà mô hình dường như rất tự tin.
- Bước cuối cùng trước khi phục vụ mô hình đã đào tạo là lưu nó để sử dụng sau này. 🤗 Transformers cho phép chúng ta thực hiện điều này trong một vài bước, hãy cùng xem trong phần tiếp theo.
Saving and sharing the model
-Cộng đồng NLP được hưởng lợi rất nhiều từ việc chia sẻ các pretrained model và fine-tuned model, đồng thời mọi người có thể chia sẻ mô hình của họ với những người khác thông qua Hugging Face Hub. Bất kỳ mô hình do cộng đồng tạo ra nào cũng có thể được tải xuống từ Hub giống như chúng ta đã sử dụng mô hình DistilBERT. Với Trainer API, việc lưu và chia sẻ mô hình rất đơn giản:
1
trainer.push_to_hub(commit_message = "Training completed!")
- Chúng ta cũng có thể sử dụng fine-tuned model của mình để đưa ra dự đoán về các tweet mới. Vì chúng ta đã đẩy mô hình của mình lên Hub, bây giờ chúng ta có thể sử dụng nó với hàm
pipeline(), giống như chúng ta đã làm trong Chương 1:
1
2
3
4
from transformers import pipeline
# Change `Dat1710` to your Hub username
model_id = "Dat1710/distilbert-base-uncased-finetuned-emotion"
classifier = pipeline("text-classification", model=model_id)
- Giờ hãy test thử mô hình với một câu tweet mới:
1
2
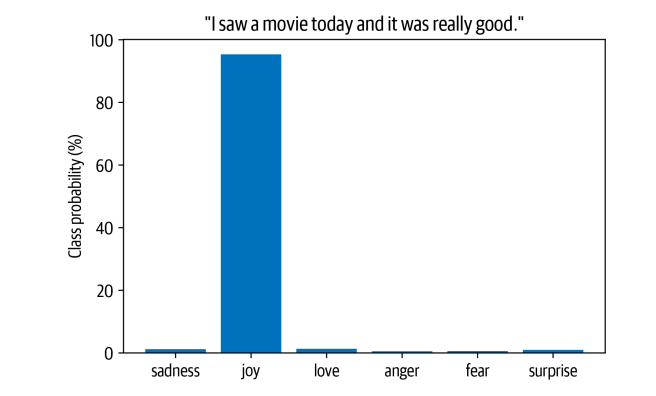
custom_tweet = "I saw a movie today and it was really good."
preds = classifier(custom_tweet, return_all_scores=True)
- Cuối cùng, chúng ta có thể vẽ xác suất cho mỗi lớp thành biểu đồ cột. Rõ ràng, mô hình ước tính rằng cảm xúc có khả năng nhất là joy, điều này có vẻ hợp lý với dòng tweet:
1
2
3
4
5
preds_df = pd.DataFrame(preds[0])
plt.bar(labels, 100 * preds_df["score"], color='C0')
plt.title(f'"{custom_tweet}"')
plt.ylabel("Class probability (%)")
plt.show()
4. Kết Luận
- Xin chúc mừng, bây giờ bạn đã biết cách train mô hình transformer để phân loại cảm xúc trong tweet! Chúng ta đã thấy hai cách tiếp cận là dựa trên các features và fine-tuning, đồng thời điều tra điểm mạnh và điểm yếu của chúng.
- Tuy nhiên, đây chỉ là bước đầu tiên trong việc xây dựng một ứng dụng trong thế giới thực với các mô hình transformer và chúng ta có nhiều nền tảng hơn để đề cập. Dưới đây là danh sách những thách thức mà bạn có thể gặp phải trong hành trình NLP của mình:
- My boss wants my model in production yesterday! : Trong hầu hết các ứng dụng, mô hình của bạn không chỉ nằm ở đâu đó bám bụi — bạn muốn đảm bảo rằng nó đang phục vụ các dự đoán! Khi một mô hình được đẩy đến Hub, checkpoint suy luận sẽ tự động được tạo có thể được gọi bằng các yêu cầu HTTP. Tôi khuyên bạn nên xem tài liệu về Inference API nếu bạn muốn tìm hiểu thêm.
- My users want faster predictions! : Chúng ta đã thấy một cách tiếp cận cho vấn đề này: sử dụng DistilBERT. Trong Chương 8, chúng ta sẽ đi sâu vào khowledge distillation (quá trình mà DistilBERT được tạo ra), cùng với các thủ thuật khác để tăng tốc các mô hình transformer của bạn.
- Can your model also do X ? : Như chúng ta đã ám chỉ trong chương này, transformer cực kỳ linh hoạt. Trong phần còn lại của cuốn sách, chúng ta sẽ khám phá một loạt các nhiệm vụ, như trả lời câu hỏi và nhận dạng thực thể được đặt tên, tất cả đều sử dụng cùng một kiến trúc cơ bản.
- None of my texts are in English !: Hóa ra các mô hình transformer cũng có nhiều ngôn ngữ khác nhau và chúng ta sẽ sử dụng chúng trong Chương 4 để giải quyết nhiều ngôn ngữ cùng một lúc.
- I don’t have any labels ! : Nếu có rất ít dữ liệu được dán nhãn, fine-tuning có thể không phải là một lựa chọn. Trong Chương 9, chúng ta sẽ khám phá một số kỹ thuật để đối phó với tình huống này.
- Bây giờ chúng ta đã thấy những gì liên quan đến việc training và sharing transformer, trong chương tiếp theo, chúng ta sẽ khám phá việc triển khai mô hình transformer của riêng mình từ đầu.