Transformer Anatomy
Trong blog “Text Classification”, chúng ta đã thấy những gì cần thiết để fine-tune và đánh giá transformer. Bây giờ chúng ta hãy xem cách chúng hoạt động cụ thể. Trong blog này, chúng ta sẽ khám phá các khối xây dựng chính của các mô hình transformer và cách triển khai chúng bằng PyTorch. Chúng tôi cũng sẽ cung cấp hướng dẫn về cách thực hiện tương tự trong TensorFlow. Đầu tiên chúng ta sẽ tập trung vào việc xây dựng cơ chế chú ý, sau đó thêm các thành phần cần thiết để làm cho transforrmer encoder hoạt động. Chúng ta cũng sẽ có một cái nhìn ngắn gọn về sự khác biệt về kiến trúc giữa các encoder và decoder. Đến cuối blog này, bạn sẽ có thể tự mình thực hiện một mô hình transformer đơn giản!
- Mặc dù hiểu biết kỹ thuật sâu sắc về kiến trúc Transformer thường không cần thiết để sử dụng 🤗 Transformers và fine-tune các mô hình cho trường hợp sử dụng của bạn, nhưng nó có thể hữu ích để hiểu và điều hướng các hạn chế của Transformer và sử dụng chúng trong các lĩnh vực mới.
- Blog này cũng giới thiệu nhiều kiểu transformers để giúp bạn hiểu hàng loạt các mô hình đã xuất hiện trong những năm gần đây. Trước khi đi sâu vào code, hãy bắt đầu với cái nhìn tổng quan về kiến trúc đầu tiên của transformers - thứ mà đã khởi động cuộc cách mạng về transformer.
1. Kiến trúc của Transformer
- Như chúng ta đã biết, Transformer ban đầu dựa trên kiến trúc encoder-decoder được sử dụng rộng rãi cho các tác vụ như dịch máy, trong đó một chuỗi từ được dịch từ ngôn ngữ này sang ngôn ngữ khác. Kiến trúc này bao gồm hai thành phần:
- Encoder: Chuyển đổi một chuỗi token đầu vào thành một chuỗi embedding vectors, thường được gọi là hidden state hoặc context.
- Decoder: Sử dụng hidden state của encoder để tạo ra một chuỗi token ouput, mỗi token một lần (tức là lần lượt tạo ra từng token một, không phải song song).
- Như minh họa trong Hình 3-1, bản thân bên trong encoder và decoder bao gồm một số khối xây dựng.
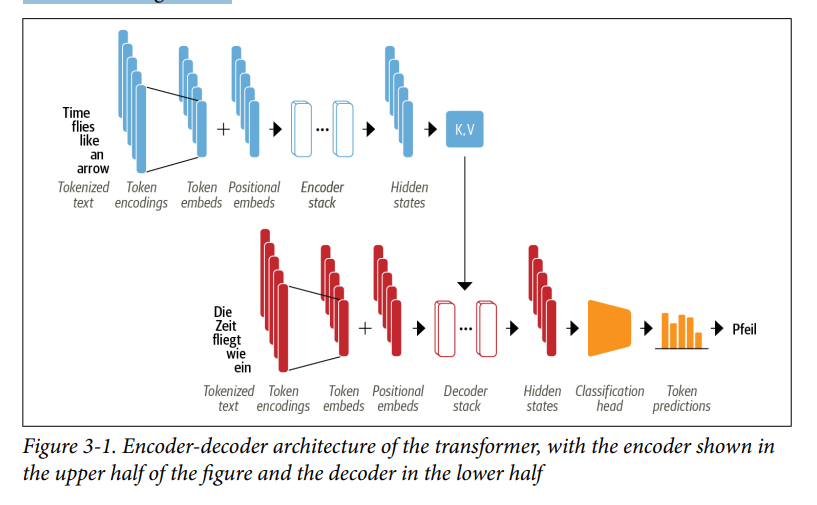
- Chúng ta sẽ xem xét chi tiết từng thành phần sau, nhưng chúng ta có thể thấy một số điều trong Hình 3-1 đặc trưng cho kiến trúc Transformer:
- Văn bản đầu vào được tokenized và chuyển đổi thành token embeddings bằng cách sử dụng các kỹ thuật mà chúng ta đã nói trong các blog khác. Vì cơ chế chú ý không nhận thức được vị trí tương đối của các token, chúng ta cần một cách để đưa thông tin về vị trí token vào đầu vào để mô hình hóa bản chất tuần tự của văn bản. Do đó, các token embeddings được kết hợp với positional embeddings chứa thông tin vị trí cho mỗi token.
- Encoder bao gồm một chồng các encoder stack hoặc gọi là các khối (blocks), tương tự như xếp chồng các lớp tích chập trong thị giác máy tính. Điều này cũng đúng với decoder, có các decoder stack.
- Đầu ra của encoder được đưa đến từng lớp encoder layer và sau đó decoder tạo ra dự đoán cho token tiếp theo có khả năng xảy ra nhất trong chuỗi. Đầu ra của bước này sau đó được đưa trở lại decoder để tạo token tiếp theo, v.v. cho đến khi đạt được token kết thúc chuỗi (EOS). Trong ví dụ từ Hình 3-1, hãy tưởng tượng decoder đã dự đoán “Die” và “Zeit”. Bây giờ nó sẽ nhận hai cái này làm đầu vào cũng như tất cả các đầu ra của encoder để dự đoán token tiếp theo, “fliegt”. Trong bước tiếp theo, decoder lại nhận được “fliegt” như một đầu vào bổ sung. Chúng ta lặp lại quá trình này cho đến khi decoder dự đoán token EOS hoặc chúng ta đạt đến độ dài tối đa của output.
- Kiến trúc Transformer ban đầu được thiết kế cho các tác vụ sequence-sequence như dịch máy, nhưng cả khối encoder và decoder đều sớm được điều chỉnh thành các mô hình độc lập. Mặc dù có hàng trăm kiến trúc transformer khác nhau, nhưng hầu hết chúng thuộc một trong ba loại:
- Encoder-only: Các mô hình này chuyển đổi một chuỗi văn bản đầu vào thành một biểu diễn số phong phú (vector embedding), rất phù hợp cho các tác vụ như phân loại văn bản hoặc nhận dạng thực thể được đặt tên (NER). BERT và các biến thể của nó, như RoBERTa và DistilBERT, thuộc loại kiến trúc này. Vector embedding được tính toán cho token nhất định trong kiến trúc này phụ thuộc vào cả bên trái (trước token đó) và bên phải (sau token đó). Điều này thường được gọi là cơ chế chú ý hai chiều (bidirectional attention).
- Decoder-only: Cho một đoạn văn bản như “Thanks for a lunch, I had a…” Các mô hình này sẽ tự động hoàn thành câu bằng cách dự đoán từ tiếp theo có khả năng xảy ra nhất. Họ mô hình GPT thuộc lớp này. Vector embeddings được tính toán cho một token nhất định trong kiến trúc này chỉ phụ thuộc vào ngữ cảnh bên trái. Điều này thường được gọi là causal hoặc autoregressive attention.
- Encoder-Decoder: Chúng được sử dụng để mô hình hóa ánh xạ phức tạp từ chuỗi văn bản này sang chuỗi văn bản khác. Chúng phù hợp với các tác vụ dịch máy và tóm tắt. Ngoài kiến trúc Transformer, các mô hình BART và T5 thuộc lớp này.
Thực tế, sự phân biệt giữa các ứng dụng dành cho kiến trúc decoder-only so với encoder-only có phần mờ nhạt. Ví dụ, các mô hình chỉ sử dụng decoder như họ GPT có thể được tùy chỉnh để thực hiện các nhiệm vụ như dịch thuật, vốn thường được xem là các nhiệm vụ sequence-to-sequence. Tương tự, các mô hình chỉ sử dụng encoder như BERT cũng có thể được áp dụng cho các nhiệm vụ tóm tắt, mà thông thường gắn liền với các mô hình encoder-decoder hoặc decoder-only (paper).
- Bây giờ bạn đã có hiểu biết sâu sắc về kiến trúc Transformer, chúng ta hãy xem xét kỹ hơn hoạt động bên trong của encoder.
The Encoder
- Như chúng ta đã thấy trước đó, encoder của transformer bao gồm nhiều lớp encoder xếp cạnh nhau. Như minh họa trong Hình 3-2, mỗi lớp encoder nhận được chuỗi embedding là đầu vào và cung cấp chúng qua các sublayers sau:
- Một lớp multi-head self-attention.
- Một lớp fully connected feed-forward được áp dụng cho mỗi input embedding.
- Các output embedding của mỗi lớp encoder có cùng kích thước với input và chúng ta sẽ sớm thấy rằng vai trò chính của lớp encoder là “cập nhật” các input embedding để tạo ra các biểu diễn mã hóa một số thông tin ngữ cảnh trong câu. Ví dụ, từ “apple” sẽ được cập nhật để “company-like” hơn và ít “fruit-like” hơn nếu các từ “keynote” hoặc “phone” có trong câu (Nói chung là, mục đích của các lớp encoder là nhằm giàu thông tin của embedding dựa vào ngữ cảnh trong câu).
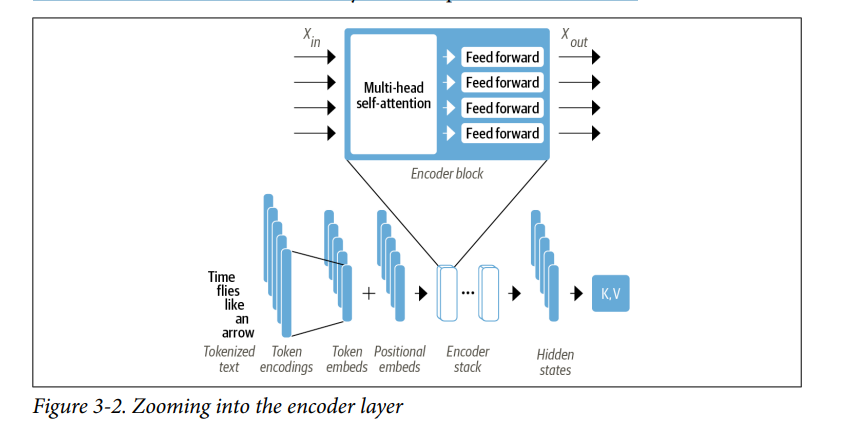
- Các sublayers trong các lớp encoder cũng sử dụng skip connections và layer normalization, điều này giúp cho mô hình học sâu được train hiệu quả hơn. Nhưng để thực sự hiểu điều gì làm cho transformer hoạt động, chúng ta phải đi sâu hơn. Hãy bắt đầu với khối quan trọng nhất: self-attention layer.
Self-Attention
- Như chúng ta đã thảo luận trong blog trước, cơ chế attention là một phương pháp cho phép mạng nơ-ron gán một mức độ trọng số khác nhau, hay gọi là “sự chú ý” cho từng phần tử trong một chuỗi. Đối với chuỗi văn bản, các phần tử là các token embedding giống như những gì chúng ta đã gặp trong blog trước, nơi mỗi token được ánh xạ thành một vector có số chiều cố định. Ví dụ, trong mô hình BERT, mỗi token được biểu diễn dưới dạng một vector 768 chiều. Phần “self” của self-attention ám chỉ rằng các trọng số này được tính toán cho tất cả hidden states trong cùng một tập hợp — ví dụ, tất cả các hidden states của encoder. Ngược lại, cơ chế attention trong các mô hình hồi quy (recurrent models) liên quan đến việc tính toán mức độ liên quan của mỗi hidden state của encoder đến hidden state của decoder tại thời điểm decoding.
- Ý tưởng chính đằng sau self-attention là thay vì sử dụng embedding cố định cho từng token, chúng ta có thể sử dụng toàn bộ chuỗi để tính một trung bình có trọng số (weighted average) của mỗi embedding. Một cách khác để diễn đạt điều này là ví dụ như ta có mỗi chuỗi các token embedding $x_1. \dots, x_n$, self-attention tạo ra một chuỗi token embedding mới $x_1’, \dots, x_n’$ sao cho $x_i’$ là tổ hợp tuyến tính của toàn bộ $x_j$:
- Các hệ số $w_{ji}$ được gọi là trọng số attention (attention weights) và được chuẩn hóa sao cho $\displaystyle \sum_{j=1}^{n}w_{ji} = 1$. Để hiểu tại sao việc tính trung bình các token embedding lại là một ý tưởng hay, hãy xem xét ví dụ khi bạn thấy từ “flies”. Bạn có thể nghĩ đến con ruồi, nhưng nếu được cung cấp thêm ngữ cảnh, như “time flies like an arrow,” thì bạn sẽ nhận ra rằng “flies” thực ra là động từ. Tương tự, chúng ta có thể tạo một biểu diễn cho từ “flies” mà tích hợp ngữ cảnh này bằng cách kết hợp tất cả các token embedding với các tỷ lệ khác nhau, có thể bằng cách gán một trọng số lớn hơn cho token embedding của “time” và “arrow.” Các embedding được tạo ra theo cách này được gọi là embedding có ngữ cảnh hóa (contextualized embeddings) và đã xuất hiện trước khi có sự ra đời của các mô hình transformer trong xử lý ngôn ngữ, chẳng hạn như ELMo (paper).
Một sơ đồ của quy trình này được hiển thị trong Hình 3-3, nơi chúng ta minh họa hai cách biểu diễn khác nhau cho từ “flies” dựa vào ngữ cảnh, nhờ self-attention.
- Bây giờ hãy xem cách chúng ta có thể tính toán trọng số chú ý (attention weights).
Scaled dot-product attention
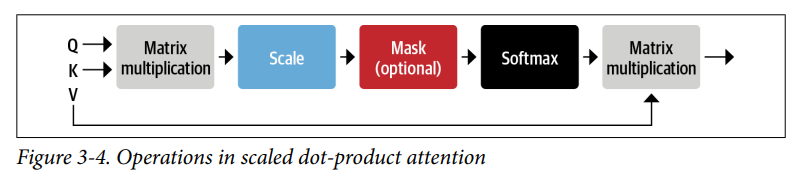
- Có nhiều cách để code self-attention layer, nhưng cách phổ biến nhất là scaled dot-product attention, từ bài báo giới thiệu kiến trúc Transformer. Có bốn bước chính cần thiết để code cái này:
- Biến mỗi token embedding thành ba vectơ được gọi là query, key và value.
- Tính attention scores. Chúng ta xác định mức “giống nhau” của vector query và vector key bằng cách sử dụng similarity function. Đúng như cái tên, similarity function cho scaled dot-product attention chỉ đơn giản là dot-product, dot-product được tính toán hiệu quả bằng cách sử dụng phép nhân ma trận của embedding. Query và key nếu như có sự “giống nhau” lớn thì dot-product sẽ lớn, ngược lại, nếu như query và key mà không có sự “giống nhau” thì dot-product sẽ bé. Đầu ra của dot-product này được gọi là attention scores, và nếu như chuỗi đầu vào có $n$ token thì sẽ tương đương với ma trận $n \times n$ chứa các attention scores.
- Tính toán attention weights. Dot-product có thể tạo ra số rất lớn, điều này làm mất đi tính ổn định của quá trình train. Để xử lý điều này, attention scores đầu tiên sẽ được nhân với hệ số tỷ lệ để chuẩn hóa phương sai, sau đó lại tiếp tục được chuẩn hóa bằng hàm softmax để đảm bảo tổng tất cả giá trị bằng 1. Ma trận $n \times n$ lúc này sẽ chứa tất cả các attention weights, $w_{ji}$
- Cập nhập token embeddings. Khi attention weights đã được tính toán xong, chúng ta nhân nó với value vector $v_1,\dots,v_n$ để nhận được kết quả mới của embedding:
- Chúng ta có thể hình dung cách tính toán attention weights với một thư viện tiện lợi có tên là
BertVizcho Jupyter. Thư viện này cung cấp một số chức năng có thể được sử dụng để trực quan hóa các khía cạnh khác nhau của attention trong các mô hình transformer. Để trực quan hóa attention weights, chúng ta có thể sử dụngneuron_view, mô-đun này theo dõi việc tính toán các trọng số để cho thấy cách query và key được kết hợp để tạo ra trọng số cuối cùng. VìBertVizcần khai thác các attention layers của mô hình, chúng ta sẽ khởi tạo BERT checkpoint với lớp mô hình từ BertViz và sau đó sử dụng hàmshow()để tạo ra hình ảnh tương tác cho một encoder layer cụ thể và attention head. Lưu ý rằng bạn cần nhấp vào dấu “+” ở bên trái để kích hoạt trực quan hóa attention:
1
2
3
4
5
6
7
8
from transformers import AutoTokenizer
from bertviz.transformers_neuron_view import BertModel
from bertviz.neuron_view import show
model_ckpt = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = BertModel.from_pretrained(model_ckpt)
text = "time flies like an arrow"
show(model, "bert", tokenizer, text, display_mode="light", layer=0, head=8)
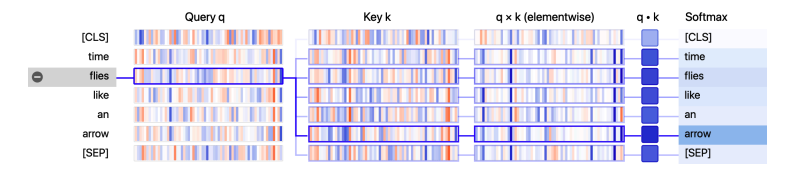
- Từ hình ảnh trực quan, chúng ta có thể thấy các giá trị của vector query và vectơ key được biểu diễn dưới dạng dải dọc, trong đó cường độ của mỗi dải tương ứng với độ lớn. Các đường kết nối là trọng số theo attention giữa các token và chúng ta có thể thấy rằng vectơ query của token “flies” có sự liên quan nhất với vectơc key của token “arrow”.
Khái niệm về vectơ query, key và value có vẻ hơi khó hiểu trong lần đầu tiên bạn gặp chúng. Tên của chúng được lấy cảm hứng từ các hệ thống truy xuất thông tin, nhưng chúng ta có thể thúc đẩy ý nghĩa của chúng bằng một phép so sánh đơn giản. Hãy tưởng tượng rằng bạn đang ở siêu thị mua tất cả các nguyên liệu bạn cần cho bữa tối của mình. Bạn có công thức của món ăn và mỗi thành phần cần thiết có thể được coi là một query. Khi bạn xem qua các kệ chứa nguyên liệu, bạn nhìn vào nhãn (key) và kiểm tra xem chúng có khớp với một thành phần trong danh sách của bạn hay không (similarity function). Nếu bạn có một sản phẩm trùng khớp, bạn sẽ lấy mặt hàng (value) từ kệ. Trong phép so sánh này, bạn chỉ nhận được một mặt hàng tạp hóa cho mỗi nhãn phù hợp với thành phần. Self-attention là một phiên bản trừu tượng và “mượt mà” hơn của điều này: mọi nhãn trong siêu thị khớp với thành phần ở mức độ mà mỗi key phù hợp với query. Vì vậy, nếu danh sách của bạn bao gồm một tá quả trứng, thì bạn có thể lấy được 10 quả trứng, một quả trứng tráng và một cánh gà.
- Chúng ta hãy xem xét quá trình này chi tiết hơn bằng cách triển khai sơ đồ các phép toán để tính toán scaled dot-product attention, như thể hiện trong Hình 3-4.
- Chúng ta sẽ sử dụng PyTorch để triển khai kiến trúc Transformer trong blog này, nhưng các bước trong TensorFlow là tương tự. Chúng ta sẽ nhìn qua các chức năng giống nhau trong hai framewwork ở Bảng 3-1.
- Điều đầu tiên chúng ta cần làm là tokenize văn bản, vì vậy hãy sử dụng
tokenizercủa chúng ta để trích xuất các input IDs:
1
2
3
inputs = tokenizer(text, return_tensors = "pt", add_special_tokens = False)
inputs.input_ids
# tensor([[ 2051, 10029, 2066, 2019, 8612]])
- Như chúng ta đã thấy trong blog “Text Classification”, mỗi token trong câu đã được ánh xạ đến một ID duy nhất trong tokenizer’s vocabulary. Để đơn giản, chúng ta loại trừ token đặc biệt [CLS] và [SEP] bằng cách đặt
add_special_tokens=False. Tiếp theo, chúng ta cần tạo một số embeddings dày đặc. “Dày đặc” trong ngữ cảnh này có nghĩa là các giá trị trong embedding là khác 0. Ngược lại, các one-hot embedding mà chúng ta thấy trong blog “Text Classification” là thưa thớt, vì tất cả đều có giá trị là 0 trừ một phần tử (Hiểu đơn giản, vecotr dày đặc có nghĩa là ít phần tử bằng 0, vector thưa thớt là có nhiều phần từ bằng 0). Trong PyTorch, chúng ta có thể làm điều này bằng cách sử dụng lớptorch.nn.Embeddinghoạt động như một bảng tra cứu cho mỗi ID đầu vào:
1
2
3
4
5
from torch import nn
from transformers import AutoConfig
config = AutoConfig.from_pretrained(model_ckpt)
token_emb = nn.Embedding(config.vocab_size, config.hidden_size)
token_emb
- Ở đây chúng ta đã sử dụng lớp
AutoConfigđể tải tệpconfig.jsonđược liên kết vớibert-base-uncasedcheckpoint. Trong 🤗 Transformers, mỗi checkpoint được gán một tệp cấu hình chỉ định các siêu tham số khác nhau nhưvocab_sizevàhidden_size, trong ví dụ trên chúng ta thấy rằng mỗi ID đầu vào sẽ được ánh xạ đến một trong 30.522 vectơ embedding được lưu trữ trongnn.Embedding, mỗi vector có kích thước 768. LớpAutoConfigcũng lưu trữ metadata bổ sung, chẳng hạn như tên nhãn, được sử dụng để định dạng dự đoán của mô hình. Lưu ý rằng các token embeddings tại thời điểm này độc lập với ngữ cảnh của chúng. Điều này có nghĩa là các từ đồng âm (các từ có cùng chính tả nhưng có nghĩa khác nhau), như “flies” trong ví dụ trước, có cùng biểu diễn trong các câu khác nhau. Tại vì chúng ta mới chỉ đang gọi
nn.Embeddingchứ chưa train gì (các trọng số củann.Embeddingđược khởi tạo ngẫu nhiên) nên các vector hay các trọng số trongnn.Embeddingchưa được học gì, điều này dẫn đến là nếu bạn embedding từ “flies” trong câu “time flies like an arrow” và trong câu “fruit flies like a banana” thì vector embedding giống hệt nhau. Vai trò của các attention layer sẽ là kết hợp các token embedding này để phân biệt và thông báo cho sự đại diện của từng token với nội dung ngữ cảnh của câu.- Bây giờ chúng ta đã có bảng tra cứu vector embedding, chúng ta có thể tạo các embedding bằng cách cung cấp các input ID:
1
2
inputs_embeds = token_emb(inputs.input_ids)
inputs_embeds.size() # torch.Size([1, 5, 768])
💡 Fact:
nn.Embeddinggần giống vớinn.Linearnên bạn chỉ cần hiểu đơn giảnnn.Embeddinglà một ma trận, khi cho một đầu vào x quann.Embeddingthì chúng ta đang thực hiện phép nhân x*(Ma trận trọng số bên trongnn.Embedding). Xem về sự khác biết củann.Embeddingvànn.Lineartại đây.
- Điều này đã cho chúng ta một tensor có shape là [batch_size, seq_len, hidden_dim], giống như chúng ta đã thấy trong blog “Text Classification”. Chúng ta sẽ tạm thời bỏ qua positional encoding, bước tiếp theo sẽ là tạo vectơ query, key, value và tính attention score bằng cách dùng similarity function là dot product:
1
2
3
4
5
6
import torch
from math import sqrt
query = key = value = inputs_embeds # Q,K,V
dim_k = key.size(-1)
scores = torch.bmm(query, key.transpose(1,2)) / sqrt(dim_k) # Q*K^T / sqrt(dim_k)
scores.size() # torch.Size([1, 5, 5])
- Điều này đã tạo ra ma trận $5 \times 5$ attention scores cho một sample trong batch. Sau này chúng ta sẽ thấy rằng các ma trận query, key, value được tạo ra bằng cách nhân ma trận trọng lượng $W_{Q,K,V}$ cho các embedding, nhưng hiện tại chúng ta để ba ma trận bằng nhau cho đơn giản. Trong scaled dot-product attention, dot-product được chia cho kích thước vectơ embedding để chúng ta không nhận được quá nhiều số lớn trong quá trình train, các số lớn có thể gây ra softmax sự bão hòa.
- Hãy áp dụng hàm softmax nào:
1
2
3
4
import torch.nn.functional as F
weights = F.softmax(scores, dim=-1)
weights.sum(dim=-1)
# tensor([[1., 1., 1., 1., 1.]], grad_fn=<SumBackward1>)
- Bước cuối cùng là nhân attention scores với ma trận values:
1
2
attn_outputs = torch.bmm(weights, value)
attn_outputs.shape # torch.Size([1, 5, 768])
- Và thế là xong - chúng ta đã trải qua tất cả các bước để thực hiện một hình thức đơn giản hóa của self-attention! Lưu ý rằng toàn bộ quá trình chỉ là hai phép nhân ma trận và softmax, vì vậy bạn có thể coi self-attention chỉ là một cách rất ngầu để tính trung bình. Hãy gói các bước này thành một hàm mà chúng ta có thể sử dụng sau này:
1
2
3
4
5
def scaled_dot_product_attention(query, key, value):
dim_k = query.size(-1)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k)
weights = F.softmax(scores, dim=-1)
return torch.bmm(weights, value)
Cơ chế attention với các ma trận query và key giống nhau sẽ gán một giá trị rất lớn cho các từ giống nhau trong ngữ cảnh, đặc biệt là với chính từ hiện tại: tích vô hướng của một query với chính nó luôn bằng 1. Nhưng trong thực tế, ý nghĩa của một từ sẽ được hiểu rõ hơn thông qua các từ bổ sung trong ngữ cảnh hơn là bởi các từ giống hệt nhau — ví dụ, ý nghĩa của từ “flies” (bay/con ruồi) được xác định tốt hơn bằng cách kết hợp thông tin từ “time” (thời gian) và “arrow” (mũi tên) thay vì từ một lần xuất hiện khác của từ “flies”. Làm thế nào để chúng ta thúc đẩy hành vi này?
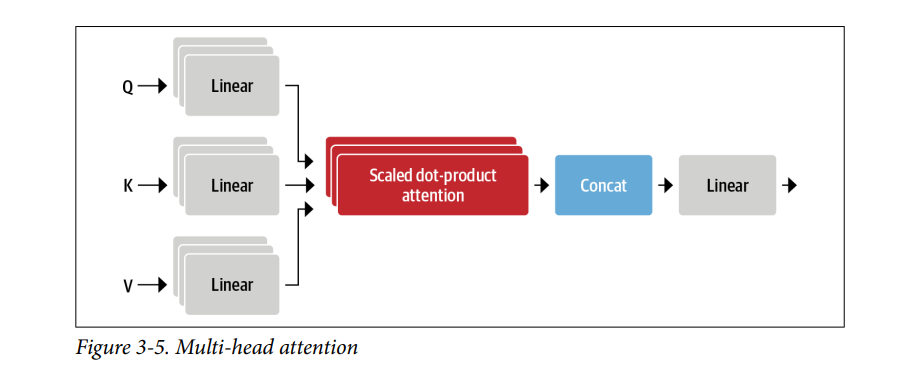
Hãy để mô hình tạo ra một ma trận khác nhau cho query, key, và value bằng cách sử dụng ba phép chiếu tuyến tính khác nhau để chiếu vector token ban đầu của chúng ta vào ba không gian khác nhau.
Multi-headed attention
Trong ví dụ đơn giản, chúng ta chỉ sử dụng các embeddings “như nó vốn có” để tính toán điểm số và trọng số chú ý (attention scores and weights). Nhưng thực tế không chỉ có vậy. Trong lớp self-attention, mỗi embedding được áp dụng ba phép biến đổi tuyến tính riêng biệt để tạo ra các vector query, key, và value. Những phép biến đổi này giúp mô hình hiểu ý nghĩa của các từ trong câu và tập trung vào những mối liên hệ quan trọng giữa chúng.
Ngoài ra, việc có nhiều tập hợp các phép biến đổi gọi là “đầu chú ý” (attention heads) cũng rất hữu ích. Mỗi attention head có thể tập trung vào một khía cạnh khác nhau của câu. Ví dụ, một head có thể tập trung vào mối quan hệ giữa chủ ngữ và động từ, trong khi một head khác chú ý đến những từ mô tả gần đó như tính từ. Những mối quan hệ này không phải do con người lập trình thủ công, mà được mô hình tự học từ dữ liệu. Nếu bạn quen với các mô hình nhận diện hình ảnh, điều này giống như các bộ lọc (filters) trong mạng nơ-ron tích chập (convolutional neural networks). Một bộ lọc có thể dùng để nhận diện khuôn mặt, trong khi bộ lọc khác tìm bánh xe của xe. Các attention heads hoạt động tương tự như vậy nhưng áp dụng cho ngữ nghĩa trong câu.
- Giờ hãy thử code class
AttentionHeadnhư sau:
1
2
3
4
5
6
7
8
9
class AttentionHead(nn.Module):
def __init__(self, embed_dim, head_dim):
self.q = nn.Linear(embed_dim, head_dim)
self.k = nn.Linear(embed_dim, head_dim)
self.v = nn.Linear(embed_dim, head_dim)
def forward(self, hidden_state):
attn_ouputs = scaled_dot_product_attention(self.q(hidden_state), self.k(hidden_state), self.v(hidden_state))
return attn_ouputs
Ở đây chúng ta đã khởi tạo 3
nn.Linearđộc lập nhau mà khi cho embedding vectors quann.Linearthì có nghĩa là chúng ta đang thực hiện phép nhân ma trận, đầu ra củann.Linearsẽ có kích cỡ là [batch_size,seq_len,head_dim], trong đóhead_dimlà số chiều mà chúng ta muốn ở đầu ra. Mặc dùhead_dimkhông nhất thiết phải nhơ hơnembed_dimnhưng trong thực thế người ta thường chọnhead_dimbằng cách lấyembed_dimchia cho số heads. Ví dụ, mô hình BERT có 12 attentons heads, nên người ta đã chọnhead_dimbằngembed_dim/num_headtương đường với $\frac{768}{12} = 64$.- Để cho mọi thứ dễ hiểu hơn, chúng ta sẽ xem xét lại từ đầu. Giả sử đầu vào là một câu văn bản: “time flies like an arrow”. Sau khi được văn bản được tokenizer thì ta có input_ids bằng
tensor([[ 2051, 10029, 2066, 2019, 8612]]), sau đó input_ids sẽ được embedding thành [1, 5, 768], gọi làinputs_embeds, tức là 1 token sẽ được embedding thành vector có 768 chiều. Đầu vào của lớpAttentionHeadsẽ làinputs_embeds. Cụ thể, kiến trúc củaAttentionHeadsẽ như sau:- Đầu vào: $[1,5,768]$ (
inputs_embeds) - $Q, K, V$ được tạo ra bằng cách cho $[1, 5, 768]$ qua tầng Linear có kích thước là [embed_dim, head_dim], ví dụ là $(768, 64)$.
- Khi đó $Q,K,V = [1, 5, 64]$, lưu ý là theo paper gốc “Attention for all you need” thì chiều cuối cùng của $V$ có thể khác bọn $Q,K$. Nhưng $Q,K$ chiều phải giống nhau.
- Tính $\text{Attention} = \text{Softmax}(\frac{Q.K^T}{\sqrt{d}}).V = [1 , 5, 64]$ (lưu ý là $d$ chính là chiều cuối cùng của ma trận $Q$, tức là $d = 64$ trong ví dụ này)
- Đầu ra: $[1,5,64]$
- Đầu vào: $[1,5,768]$ (
- Code trên chỉ là một attention head, class
MultiHeadAttentionsẽ concat tất cả ouput của mỗi attention head lại với nhau tạo thành một ma trận, và cho ma trận ấy qua một lớpnn.Linear:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
embed_dim = config.hidden_size
num_heads = config.num_attention_heads
head_dim = embed_dim // num_heads
self.heads = nn.ModuleList(
[AttentionHead(embed_dim, head_dim) for _ in range(num_heads)]
)
self.output_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, hidden_state):
x = torch.cat([h(hidden_state) for h in self.heads], dim = -1)
x = self.output_linear(x)
return x
- Kiến trúc của
MultiHeadAttentionhiểu đơn giản như sau:- Đầu vào: $[1,5,768]$ (
inputs_embeds). - Ta sẽ dùng 12 lớp
AttentionHead. Bản chấthead_dimbằng $64$ vì $\frac{768}{12} = 64$ (Khi thiết kế kiến trúc, người ta thường sẽ chọn xem kiến trúc có bao nhiêu lớp attention head, xong đó mới tính đếnhead_dim. Tức là người ta chọn $12$ lớpAttentionHeadsau đó mới tính đến số chiều của mỗi head). Sau đó, ta sẽ tính đầu ra của $12$ lớpAttentionHeadxong rồi concat lại theo chiều ngang để tạo ra $[1,5,64*12]$ = $[1,5,768]$. Sau đó đưa qua tầngnn.Linearcó kích cỡ $[768,768]$, đầu ra thành $[1,5,768]$. - Đầu ra: $[1,5,768]$.
- Đầu vào: $[1,5,768]$ (
- Để chứng minh đầu ra của lớp
MultiHeadAttentioncó đúng như trên không, chúng ta hãy thử code như sau:
1
2
3
4
multihead_attn = MultiHeadAttention(config)
attn_output = multihead_attn(inputs_embeds)
attn_output.size()
# torch.Size([1, 5, 768])
- Nó đã hoạt động! Để kết thúc phần này về attention, hãy sử dụng
BertVizmột lần nữa để trực quan hóa attention đối với hai cách sử dụng khác nhau của từ “flies”. Ở đây chúng ta có thể sử dụng hàmhead_view()từBertVizbằng cách tính toán attenion của pretrained checkpoint:
1
2
3
4
5
6
7
8
9
10
from bertviz import head_view
from transformers import AutoModel
model = AutoModel.from_pretrained(model_ckpt, output_attentions=True)
sentence_a = "time flies like an arrow"
sentence_b = "fruit flies like a banana"
viz_inputs = tokenizer(sentence_a, sentence_b, return_tensors='pt')
attention = model(**viz_inputs).attentions
sentence_b_start = (viz_inputs.token_type_ids == 0).sum(dim=1)
tokens = tokenizer.convert_ids_to_tokens(viz_inputs.input_ids[0])
head_view(attention, tokens, sentence_b_start, heads=[8])
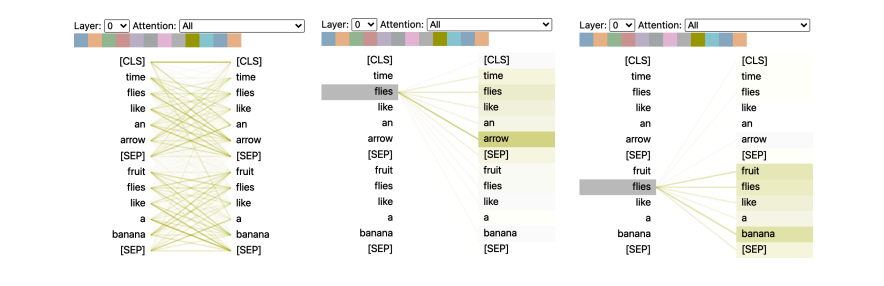
Hình minh họa này cho thấy các trọng số chú ý (attention weights) được thể hiện bằng các đường nối giữa các token mà embedding của chúng đang được cập nhật (bên trái) với từng từ mà nó đang tập trung vào (bên phải). Độ đậm nhạt của các đường thể hiện độ mạnh yếu của trọng số chú ý, với các đường đậm đại diện cho giá trị gần 1 và các đường mờ đại diện cho giá trị gần 0.
Trong ví dụ này, đầu vào bao gồm hai câu và các token [CLS] và [SEP] là các special tokens trong tokenizer của BERT mà chúng ta đã gặp ở blog trước. Một điều có thể thấy từ hình minh họa là các trọng số chú ý mạnh nhất giữa các từ thuộc cùng một câu, điều này cho thấy BERT có thể nhận biết rằng nó cần tập trung vào các từ trong cùng một câu. Tuy nhiên, đối với từ “flies,” chúng ta có thể thấy rằng BERT đã xác định “arrow” là quan trọng trong câu đầu tiên, và “fruit” cũng như “banana” trong câu thứ hai. Các trọng số chú ý này cho phép mô hình phân biệt việc sử dụng từ “flies” như một động từ hay danh từ, tùy thuộc vào ngữ cảnh mà nó xuất hiện!
Bây giờ, khi đã tìm hiểu xong về attention, hãy cùng xem cách triển khai phần còn thiếu của lớp encoder: position-wise feed-forward networks.
The Feed-Forward Layer
Lớp feed-forward trong encoder và decoder thực chất chỉ là một mạng neural fully connected hai lớp đơn giản, nhưng có một sự khác biệt: thay vì xử lý toàn bộ chuỗi embedding như một vector duy nhất, nó xử lý từng embedding độc lập. Vì lý do này, lớp này thường được gọi là position-wise feed-forward layer (lớp feed-forward theo vị trí). Bạn cũng có thể thấy nó được gọi là một tích chập một chiều (one-dimensional convolution) với kích thước kernel bằng một, thường được những người làm việc trong lĩnh vực thị giác máy tính sử dụng (ví dụ, mã nguồn của OpenAI GPT sử dụng thuật ngữ này).
Một trick là
intermediate_sizethường gấp bốn lần kích thước củahidden_size, và hàm kích hoạt GELU thường được sử dụng. Đây là nơi mà hầu hết khả năng và trí nhớ của mô hình được coi là diễn ra, và nó cũng là phần thường được mở rộng khi tăng kích thước của các mô hình. Chúng ta có thể triển khai điều này như mộtnn.Moduleđơn giản như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self,x):
x = self.linear_1(x)
x = self.gelu(x)
x = self.linear_2(x)
x = self.dropout(x)
return x
- Kiến trúc
FeedForwardhiểu đơn giản như sau:- Đầu vào: $[1,5,768]$
- Đưa đầu vào qua
nn.Linearcó kích cỡ là $(768, 3072)$ (tùy kiến trúc mà số $3072$ là khác nhau, thường làintermediate_sizegấp $4$ lầnhidden_size) - Đưa qua GELU (paper “Attention is all you need” dùng hàm kích hoạt RELU)
- Đưa qua
nn.Linear(3072, 768) - Đầu ra: $[1,5,768]$
- Giờ hãy kiểm tra đầu ra bằng code sau:
1
2
3
4
feed_forward = FeedForward(config)
ff_outputs = feed_forward(attn_outputs)
ff_outputs.size()
# torch.Size([1, 5, 768])
- Bây giờ chúng ta đã có tất cả các thành phần để tạo ra một lớp transformer encoder! Quyết định duy nhất còn lại là nên đặt skip connections và layer normalization ở vị trí nào. Chúng ta hãy xem điều này ảnh hưởng như thế nào đến kiến trúc mô hình.
Adding Layer Normalization
- Như đã đề cập trước đó, kiến trúc Transformer sử dụng layer normalization (chuẩn hóa lớp) và skip connections (kết nối bỏ qua). Layer normalization chuẩn hóa từng đầu vào trong batch để có giá trị trung bình bằng 0 và phương sai bằng 1. Skip connections truyền một tensor đến lớp tiếp theo của mô hình mà không qua xử lý và cộng nó vào tensor đã qua xử lý. Dưới đây là công thức của layer normalization (lưu ý, công thức dưới là cho một vector, trong kiến trúc Transfomer ta sẽ truyền
inputs_embedsquann.LayerNorm. Màinputs_embedslà ma trận có kích thước là $[1,5,768]$ nênnn.LayerNormsẽ được tính trên chiều cuối cùng, tức là trên các vector hàng, mỗi vector có $768$ phần tử):
Trong đó vector $x$ là đầu vào, $\mathbb{E}[x]$ là kỳ vọng của $x$, $\text{Var}[x]$ là phương sai của $x$, $\epsilon$ là một hằng số nhỏ để tránh cho việc chia cho số $0$ , $\gamma$ là hệ số điều chỉnh độ lớn (tham số có thể học được trong quá trình train), $\beta$ là hệ số điều chỉnh dộ dịch (cũng là tham số có thể học)
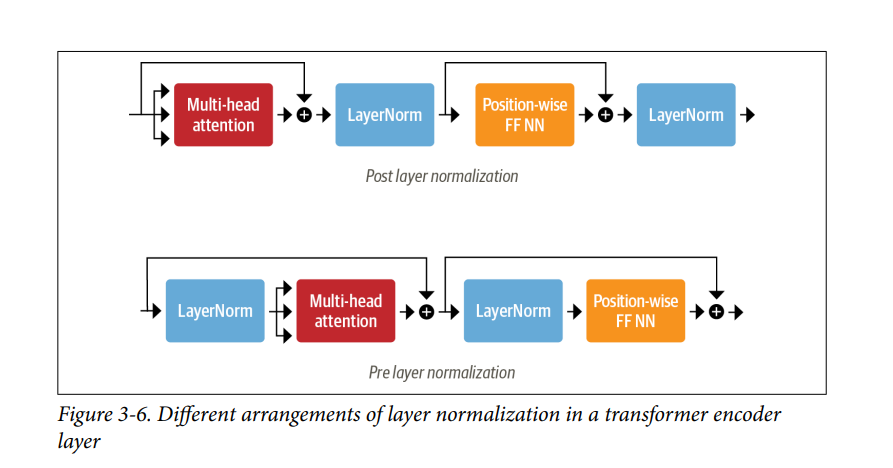
Khi nói đến việc đặt layer normalization vào vị trí nào trong các lớp encoder hoặc decoder của transformer, có hai lựa chọn chính thường được áp dụng:
- Post layer normalization: Đây là cách sắp xếp được sử dụng trong bài báo Transformer gốc; nó đặt layer normalization giữa các skip connections. Cách sắp xếp này khó huấn luyện từ đầu vì các gradient có thể bị phân kỳ. Vì lý do này, bạn thường thấy khái niệm được gọi là learning rate warm-up (làm nóng tốc độ học), trong đó tốc độ học được tăng dần từ một giá trị nhỏ đến một giá trị tối đa trong quá trình huấn luyện
- Pre layer normalization: Đây là cách sắp xếp phổ biến nhất được tìm thấy trong tài liệu; nó đặt layer normalization trong phạm vi của các skip connections. Cách này có xu hướng ổn định hơn trong quá trình huấn luyện và thường không yêu cầu bất kỳ giai đoạn làm nóng tốc độ học nào.
- Sự khác biệt giữa hai cách sắp xếp được minh họa trong Hình 3-6.
- Chúng ta sẽ code lớp
TransformerEncoderLayersử dụng cách sắp xếp thứ hai:
1
2
3
4
5
6
7
8
9
10
11
12
class TransformerEncoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.layer_norm1 = nn.LayerNorm(config.hidden_state)
self.layer_norm2 = nn.LayerNorm(config.hidden_state)
self.attention = MultiHeadAttention(config)
self.feed_forward = FeedForward(config)
def forward(self, x):
hidden_state = self.layer_norm1(x)
x = x + self.attention(hidden_state)
x = x + self.feed_forward(self.layer_norm2(x))
return x
- Giờ hãy kiểm tra với đầu vào là
inputs_embeds:
1
2
3
encoder_layer = TransformerEncoderLayer(config)
inputs_embeds.shape, encoder_layer(inputs_embeds).size()
# (torch.Size([1, 5, 768]), torch.Size([1, 5, 768]))
- Chúng ta đã code thành công lớp transformer encoder! Tuy nhiên, bạn đang thấy chúng ta đang bị thiếu gì không ? Nếu như muti-head attention chỉ đơn giản là tổng có trọng số của các token thì chẳng phải token nằm ở vị trí khác nhau trong câu cũng không khác nhau sao ? Như vậy thông tin vị trí của các token đã bị mất, điều này ảnh hưởng rất nghiêm trọng, ví dụ như câu “The dog chased the cat.” và câu “The cat chased the dog.”, hai câu này chỉ khác nhau vị trí của token dog và cat nhưng ý nghĩa đã khác hẳn nhau.
- May mắn thay, có một mẹo dễ dàng để kết hợp thông tin vị trí bằng cách sử dụng positional encoding. Chúng ta hãy cùng xem xét.
Positional Embeddings
Positional Embeddings dựa trên một ý tưởng đơn giản nhưng rất hiệu quả: bổ sung các token embedding bằng một mẫu giá trị phụ thuộc vào vị trí, được sắp xếp trong một vector. Nếu mẫu này là đặc trưng cho từng vị trí, attention heads và feed-forward layer có thể học cách kết hợp thông tin về vị trí vào các phép biến đổi của chúng.
Có nhiều cách để đạt được điều này, và một trong những cách phổ biến nhất là sử dụng một mẫu có thể học được, đặc biệt khi tập dữ liệu tiền huấn luyện đủ lớn. Cách này hoạt động giống hệt với token embedding, nhưng sử dụng chỉ số vị trí thay vì chỉ số token làm đầu vào. Với cách tiếp cận đó, một cách hiệu quả để mã hóa vị trí của các token được học trong quá trình tiền huấn luyện ra đời.
Hãy tạo một lớp
Embeddingsđơn giản như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Embeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.token_embeddings = nn.Embedding(config.vocab_size,
config.hidden_size)
self.position_embeddings = nn.Embedding(config.max_position_embeddings,
config.hidden_size)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout()
def forward(self, input_ids):
# Create position IDs for input sequence
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long).unsqueeze(0)
# Create token and position embeddings
token_embeddings = self.token_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
# Combine token and position embeddings
embeddings = token_embeddings + position_embeddings
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
embedding_layer = Embeddings(config)
embedding_layer(inputs.input_ids).size()
# torch.Size([1, 5, 768])
- Mặc dù learnable position embeddings rất dễ code và được sử dụng rộng rãi, nhưng có một số lựa chọn thay thế:
- Absolute positional representations (biểu diễn vị trí tuyệt đối): Các mô hình transformers có thể sử dụng các công thức như sin và cosin để mã hóa vị trí của các token. Điều này đặc biệt hoạt động tốt khi không có khối lượng dữ liệu lớn. Bài báo Transformers gốc dùng kiểu này.
- Relative positional representations (biểu diễn vị trí tương đối): Mặc dù các vị trí tuyệt đối là quan trọng, nhưng có thể lập luận rằng khi tính toán một embedding, các token xung quanh mới là quan trọng nhất. Biểu diễn vị trí tương đối tuân theo trực giác này và mã hóa các vị trí tương đối giữa các token. Điều này không thể được thiết lập chỉ bằng cách thêm một tầng embedding tương đối mới ở phần đầu, vì embedding tương đối thay đổi cho từng token tùy thuộc vào vị trí từ chuỗi mà chúng ta đang quan sát. Thay vào đó, cơ chế attention được sửa đổi bằng các thành phần bổ sung để đưa vị trí tương đối giữa các token vào xem xét. Các mô hình như DeBERTa sử dụng các biểu diễn này (Bằng cách kết hợp ý tưởng về biểu diễn vị trí tuyệt đối và tương đối, rotary position embeddings (nhúng vị trí quay) đạt được kết quả tuyệt vời trong nhiều nhiệm vụ. GPT-Neo là một ví dụ về mô hình có nhúng vị trí quay, có thể trong tương lai tôi sẽ làm một blog về rotary position embeddings).
- Bây giờ hãy kết hợp tất cả những điều này lại với nhau bằng cách code lớp
TransformerEncoder:
1
2
3
4
5
6
7
8
9
10
11
12
13
class TransformerEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.embeddings = Embeddings(config)
self.layers = nn.ModuleList([TransformerEncoderLayer(config) for _ in range(config.num_hidden_layers)])
def forward(self, x):
x = self.embeddings(x)
for layer in self.layers:
x = layer(x)
return x
encoder = TransformerEncoder(config)
encoder(inputs.input_ids).size()
# torch.Size([1, 5, 768])
- Chúng ta có thể thấy rằng chúng ta nhận được hidden state (vector embedding) cho mỗi token trong một batch. Định dạng đầu ra này làm cho kiến trúc rất linh hoạt và chúng ta có thể dễ dàng điều chỉnh nó cho các ứng dụng khác nhau như dự đoán các token bị thiếu trong masked language modeling hoặc dự đoán vị trí bắt đầu và kết thúc của câu trả lời trong question answering. Trong phần tiếp theo, chúng ta sẽ xem cách chúng ta có thể code một bộ phân loại giống như cái mà chúng ta đã sử dụng trong blog “Text Classification”.
Adding a Classification Head
- Các mô hình transformer thường được chia thành một body độc lập với nhiệm vụ và một task-specific head.Những gì chúng ta đã xây dựng cho đến nay là body, vì vậy nếu chúng ta muốn xây dựng một bộ phân loại văn bản, chúng ta sẽ cần phải gắn một đầu phân loại vào body đó. Chúng ta có một hidden state cho mỗi token, nhưng chúng ta chỉ cần đưa ra một dự đoán. Có một số lựa chọn để tiếp cận điều này. Theo truyền thống, token đầu tiên trong các mô hình như vậy được sử dụng để dự đoán và chúng ta có thể đính kèm một lớp dropout và một lớp linear để đưa ra dự đoán phân loại. Lớp sau mở rộng bộ encoder hiện có để phân loại chuỗi:
1
2
3
4
5
6
7
8
9
10
11
class TransformerForSequenceClassification(nn.Module):
def __init__(self, config):
super().__init__()
self.encoder = TransformerEncoder(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
def forward(self, x):
x = self.encoder(x)[:, 0, :] # chọn hidden state cho token [CLS]
x = self.dropout(x)
x = self.classifier(x)
return x
- Trước khi khởi tạo mô hình, chúng ta cần xác định có bao nhiêu lớp mà chúng ta muốn dự đoán:
1
2
3
4
5
config.num_labels = 3
encoder_classifier = TransformerForSequenceClassification(config)
encoder_classifier(inputs.input_ids).size()
# torch.Size([1, 3])
- Đó chính xác là những gì chúng ta đang tìm kiếm. Đối với mỗi ví dụ trong batch, chúng ta nhận được các logit chưa chuẩn hóa cho mỗi lớp trong đầu ra. Điều này tương ứng với mô hình BERT mà chúng tôi đã sử dụng trong blog “Text Classification” để phát hiện cảm xúc trong tweet.
- Điều này kết thúc phân tích của chúng ta về encoder và cách chúng ta có thể kết hợp nó với một đầu nhiệm vụ cụ thể. Bây giờ chúng ta hãy nói đến decoder nào !
The Decoder
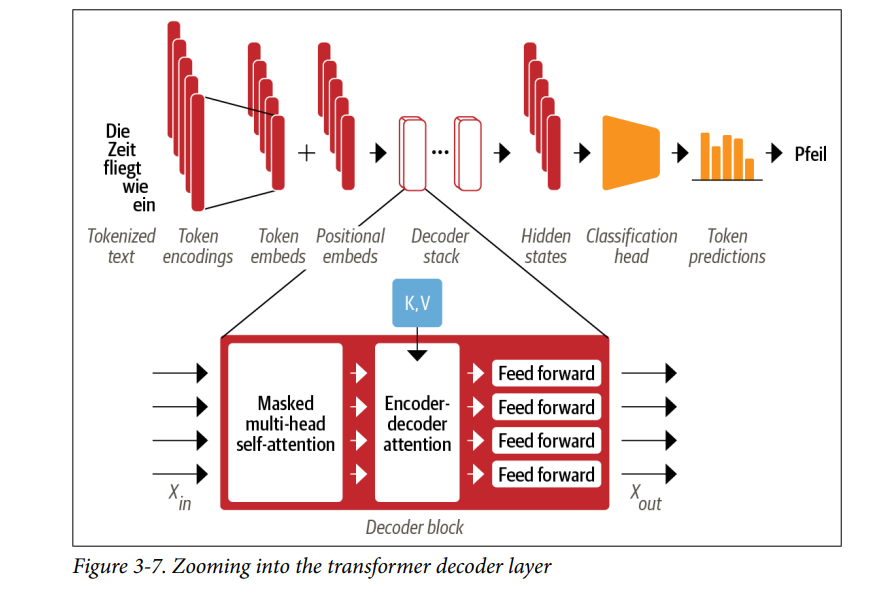
- Như minh họa trong Hình 3-7, sự khác biệt chính giữa encoder và decoder là decoder có hai lớp attention:
- Masked multi-head self-attention layer: Đảm bảo rằng các token được tạo ra tại mỗi bước thời gian chỉ dựa vào các đầu ra trước đó và token hiện tại đang được dự đoán. Nếu không có tầng này, decoder có thể “gian lận” trong quá trình huấn luyện bằng cách đơn giản sao chép các bản dịch mục tiêu; việc sử dụng mặt nạ trên đầu vào đảm bảo rằng nhiệm vụ không trở nên quá dễ dàng.
- Encoder-decoder attention layer: Thực hiện multi-head attention trên các vector key, vector value của encoder, và vector query của decoder (Lưu ý rằng không giống như self-attention, các vectơ key và query trong encoder-decoder attention có thể có độ dài khác nhau. Điều này là do đầu vào encoder và decoder thường sẽ liên quan đến các chuỗi có độ dài khác nhau. Kết quả là, ma trận attention scores trong lớp này là ma trận chữ nhật, không phải ma trận). Theo cách này, tầng attention encoder-decoder học cách liên kết các token từ hai chuỗi khác nhau, chẳng hạn như hai ngôn ngữ khác nhau. Decoder có quyền truy cập vào các key và value của encoder trong mỗi khối.
- Hãy xem xét các thay đổi cần thực hiện để thêm mặt nạ (masking) vào tầng self-attention, phần code lớp encoder-decoder attention được coi như bài tập về nhà dành cho bạn. Một mẹo với masked self-attention là dùng mask matrix, ma trận với các giá trị 1 ở phần chéo dưới và các giá trị 0 ở trên như sau:
1
2
3
4
5
6
7
8
seq_len = inputs.input_ids.size(-1)
mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0)
mask[0]
# tensor([[1., 0., 0., 0., 0.],
# [1., 1., 0., 0., 0.],
# [1., 1., 1., 0., 0.],
# [1., 1., 1., 1., 0.],
# [1., 1., 1., 1., 1.]])
- Ở đây chúng ta đã sử dụng hàm
tril()của PyTorch để tạo ma trận tam giác. Khi chúng ta có mask matrix này, chúng ta có thể ngăn mỗi attention head nhìn trộm các token trong tương lai bằng cách sử dụngTensor.masked_fill()để thay thế tất cả các số $0$ bằng âm vô cùng:
1
2
3
4
5
6
7
8
scores.masked_fill(mask == 0, -float("inf"))
# tensor([[[26.8082, -inf, -inf, -inf, -inf],
# [-0.6981, 26.9043, -inf, -inf, -inf],
# [-2.3190, 1.2928, 27.8710, -inf, -inf],
# [-0.5897, 0.3497, -0.3807, 27.5488, -inf],
# [ 0.5275, 2.0493, -0.4869, 1.6100, 29.0893]]],
# grad_fn=<MaskedFillBackward0>)
- Bằng cách đặt các giá trị nằm trên đường chéo chính bằng âm vô cùng, chúng ta đảm bảo rằng tất cả các trọng số chú ý bằng $0$ khi chúng ta lấy softmax vì $e^{-\inf} = 0$. Chúng ta có thể dễ dàng code masked attention chỉ với một thay đổi nhỏ đối với hàm
scaled_dot_product_attention(mà chúng ta đã thực hiện trước đó:
1
2
3
4
5
6
7
def scaled_dot_product_attention(query, key, value, mask=None):
dim_k = query.size(-1)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
weights = F.softmax(scores, dim=-1)
return weights.bmm(value)
Từ đây, việc xây dựng lớp decoder là một vấn đề đơn giản. Bạn có thể xem qua phần code xuất sắc của minGPT, lập trình bởi Andrej Karpathy để biết chi tiết.
Dưới đây là một cách hiểu đơn giản về encoder-decoder attention: Hãy tưởng tượng bạn (decoder) đang trong lớp làm bài kiểm tra. Bài tập là dự đoán từ tiếp theo dựa trên các từ trước đó (decoder input), nghe có vẻ đơn giản nhưng cực kỳ khó (hãy tự mình thử và dự đoán các từ tiếp theo trong một đoạn của blog này). May mắn thay, hàng xóm của bạn (encoder) có cả đoạn văn đó. Thật không may, người hàng xóm lại là một sinh viên trao đổi nước ngoài và văn bản kia bằng tiếng mẹ đẻ của họ. Nhưng bạn là một sinh viên thông minh, bạn vẫn tìm ra cách gian lận. Bạn vẽ một bức tranh hoạt hình nhỏ minh họa văn bản bạn đang có (query) và đưa nó cho hàng xóm của bạn. Họ cố gắng tìm ra đoạn nào phù hợp với mô tả đó (key), vẽ một bức tranh hoạt hình mô tả từ trong đoạn đó (value) và chuyển lại cho bạn. Với hệ thống này, bạn đã vượt qua kỳ thi.
2. Meet the Transformers
Như bạn đã thấy trong blog này, có ba kiến trúc chính cho các mô hình transformers: encoder, decoder và encoder-decoder. Thành công ban đầu của các mô hình transformer sớm đã kích hoạt một “vụ nổ Cambrian” trong sự phát triển mô hình, khi các nhà nghiên cứu xây dựng các mô hình trên các bộ dữ liệu có kích thước và tính chất khác nhau, sử dụng các mục tiêu tiền huấn luyện mới, và điều chỉnh kiến trúc để cải thiện hiệu suất hơn nữa. Mặc dù “vườn thú” các mô hình vẫn đang phát triển nhanh chóng, chúng vẫn có thể được chia thành ba loại chính này.
Trong phần này, tôi sẽ cung cấp một cái nhìn tổng quan ngắn gọn về các mô hình transformer quan trọng nhất trong mỗi loại. Hãy bắt đầu bằng cách xem xét cây phả hệ của transformer.
The Transformer Tree of Life
- Theo thời gian, mỗi trong ba kiến trúc chính đã trải qua một quá trình tiến hóa riêng của nó. Điều này được minh họa trong Hình 3-8, nơi thể hiện một số mô hình nổi bật nhất và các hậu duệ của chúng.
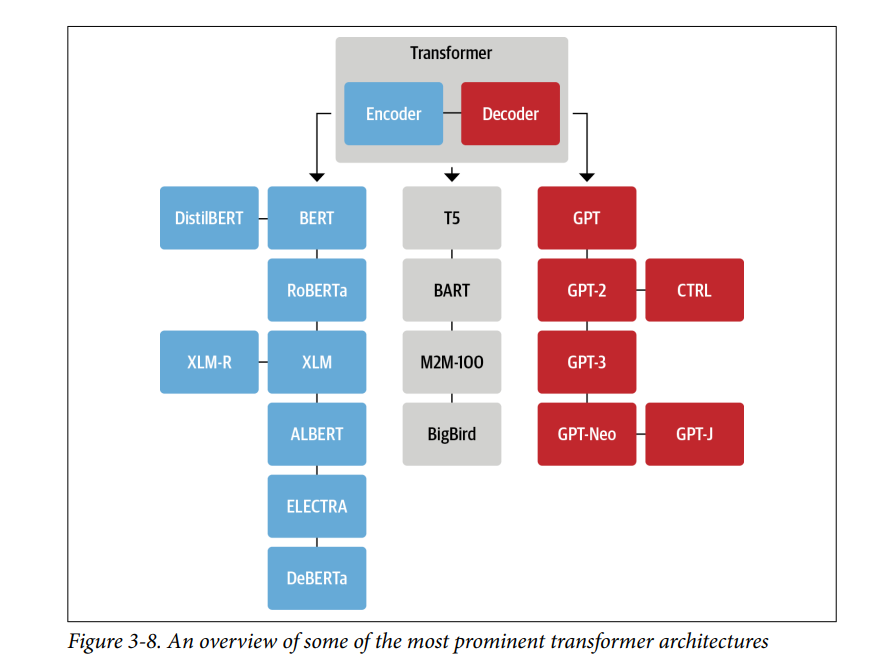
- Với hơn 50 kiến trúc khác nhau bao gồm trong 🤗 Transformers, cây phả hệ này không thể nào cung cấp một cái nhìn tổng quan đầy đủ về tất cả các mô hình hiện có: nó chỉ làm nổi bật một vài cột mốc kiến trúc quan trọng. Chúng ta đã thảo luận chi tiết về kiến trúc Transformer ban đầu trong blog này, vì vậy hãy cùng xem xét kỹ hơn một số “hậu duệ” chính, bắt đầu với nhánh encoder.
The Encoder Branch
- Mô hình chỉ sử dụng encoder đầu tiên dựa trên kiến trúc Transformer là BERT. Khi được công bố, nó đã vượt trội hơn tất cả các mô hình tiên tiến nhất trên chuẩn đánh giá GLUE phổ biến, một thước đo khả năng hiểu natural language understanding (NLU) trên nhiều tác vụ có mức độ khó khác nhau. Sau đó, mục tiêu tiền huấn luyện và kiến trúc của BERT đã được điều chỉnh để cải thiện hiệu suất hơn nữa. Các mô hình chỉ sử dụng encoder vẫn thống trị trong nghiên cứu và công nghiệp về các tác vụ NLU, chẳng hạn như xử lý văn bản, NER, question answering. Hãy xem qua mô hình BERT và các biến thể của nó:
- BERT:
- BERT được tiền huấn luyện với hai mục tiêu: dự đoán các từ bị che trong văn bản và xác định xem một đoạn văn bản có khả năng tiếp theo sau một đoạn khác hay không. Nhiệm vụ đầu tiên được gọi là mô hình hóa ngôn ngữ có che (masked language modeling - MLM), và nhiệm vụ sau là dự đoán câu tiếp theo (next sentence prediction - NSP).
- DistilBERT:
- Mặc dù BERT mang lại kết quả tuyệt vời, kích thước của nó có thể gây khó khăn khi triển khai trong các môi trường yêu cầu độ trễ thấp. Bằng cách sử dụng một kỹ thuật gọi là triển khai tri thức (knowledge distillation) trong quá trình tiền huấn luyện, DistilBERT đạt được 97% hiệu suất của BERT, đồng thời sử dụng ít hơn 40% bộ nhớ và nhanh hơn 60%.
- RoBERTa:
- Một nghiên cứu sau khi phát hành BERT cho thấy hiệu suất của nó có thể được cải thiện bằng cách sửa đổi phương pháp tiền huấn luyện. RoBERTa được huấn luyện trong thời gian dài hơn, với các batch lớn hơn và nhiều dữ liệu huấn luyện hơn, đồng thời loại bỏ nhiệm vụ NSP. Những thay đổi này đã cải thiện đáng kể hiệu suất của nó so với mô hình BERT gốc.
- XLM:
- Nhiều mục tiêu tiền huấn luyện để xây dựng các mô hình đa ngôn ngữ đã được khám phá trong công trình về mô hình ngôn ngữ xuyên ngôn ngữ (XLM), bao gồm mô hình hóa ngôn ngữ tự hồi quy từ các mô hình giống GPT và MLM từ BERT. Ngoài ra, các tác giả của bài báo về tiền huấn luyện XLM đã giới thiệu mô hình hóa ngôn ngữ dịch (translation language modeling - TLM), một mở rộng của MLM cho đầu vào đa ngôn ngữ. Thử nghiệm với các nhiệm vụ tiền huấn luyện này, họ đã đạt được kết quả tiên tiến nhất trên nhiều chuẩn đánh giá NLU đa ngôn ngữ cũng như các nhiệm vụ dịch thuật.
- XLM-RoBERTa
- Tiếp nối công trình của XLM và RoBERTa, mô hình XLM-RoBERTa (hoặc XLM-R) đưa tiền huấn luyện đa ngôn ngữ lên một cấp độ cao hơn bằng cách mở rộng quy mô dữ liệu huấn luyện một cách đáng kể. Sử dụng tập dữ liệu Common Crawl corpus, các nhà phát triển đã tạo ra một tập dữ liệu với 2,5 terabyte văn bản; sau đó họ huấn luyện một bộ mã hóa với MLM trên tập dữ liệu này.
- ALBERT:
- Mô hình ALBERT đã giới thiệu ba thay đổi để làm cho kiến trúc bộ mã hóa hiệu quả hơn.
- Đầu tiên, nó tách biệt kích thước embedding của token khỏi kích thước của lớp ẩn, cho phép kích thước embedding nhỏ hơn và nhờ đó tiết kiệm tham số, đặc biệt khi từ vựng trở nên lớn.
- Thứ hai, tất cả các lớp chia sẻ cùng tham số, điều này giảm số lượng tham số hiệu quả cần thiết xuống thêm nữa.
- Cuối cùng, mục tiêu NSP (Next Sentence Prediction) được thay thế bằng dự đoán thứ tự câu: mô hình cần dự đoán liệu thứ tự của hai câu liên tiếp có bị hoán đổi hay không, thay vì dự đoán liệu chúng có thuộc về cùng một ngữ cảnh hay không.
- Những thay đổi này làm cho việc huấn luyện các mô hình lớn hơn với ít tham số hơn trở nên khả thi và đạt được hiệu năng vượt trội trên các tác vụ NLU (Hiểu ngôn ngữ tự nhiên).
- ELECTRA:
- Một hạn chế của mục tiêu tiền huấn luyện MLM (Masked Language Model) tiêu chuẩn là ở mỗi bước huấn luyện, chỉ các đại diện của các token bị che đi được cập nhật, trong khi các token đầu vào khác thì không. Để giải quyết vấn đề này, ELECTRA sử dụng cách tiếp cận hai mô hình:
- Mô hình đầu tiên (thường là nhỏ) hoạt động như một mô hình ngôn ngữ bị che và dự đoán các token bị che.
- Mô hình thứ hai, được gọi là bộ phân biệt (discriminator), được giao nhiệm vụ dự đoán token nào trong đầu ra của mô hình đầu tiên là bị che ban đầu.
- Do đó, bộ phân biệt cần thực hiện phân loại nhị phân cho mỗi token, điều này làm cho việc huấn luyện hiệu quả hơn gấp 30 lần. Trong các tác vụ downstream, bộ phân biệt được tinh chỉnh giống như một mô hình BERT tiêu chuẩn.
- DeBERTa:
- Mô hình DeBERTa giới thiệu hai thay đổi kiến trúc:
- Đầu tiên, mỗi token được biểu diễn dưới dạng hai vector: một cho nội dung, cái còn lại cho vị trí tương đối. Bằng cách tách nội dung của token khỏi vị trí tương đối của nó, các lớp self-attention có thể mô hình hóa tốt hơn sự phụ thuộc của các token gần nhau.
- Mặt khác, vị trí tuyệt đối của một từ cũng rất quan trọng, đặc biệt là đối với việc giải mã. Vì lý do này, một embedding vị trí tuyệt đối được thêm vào ngay trước lớp softmax của lớp giải mã token.
- DeBERTa là mô hình đầu tiên (được sử dụng như một tập hợp mô hình) đánh bại con người trên chỉ số SuperGLUE benchmark, một phiên bản khó hơn của GLUE.
- Giờ chúnng ta hãy xem qua các mô hình nổi bật ở nhánh decoder.
The Decoder Branch
- Tiến bộ trong các mô hình transformer decoder đã được dẫn đầu phần lớn bởi OpenAI. Những mô hình này đặc biệt xuất sắc trong việc dự đoán từ tiếp theo trong một chuỗi và thường được sử dụng cho các tác vụ sinh văn bản. Sự tiến bộ của chúng được thúc đẩy bởi việc sử dụng các tập dữ liệu lớn hơn và mở rộng quy mô các mô hình ngôn ngữ lên kích thước ngày càng lớn hơn. Hãy cùng xem sự phát triển của những mô hình sinh văn bản thú vị này:
- GPT:
- Việc giới thiệu GPT đã kết hợp hai ý tưởng chính trong NLP: kiến trúc transformer decoder mới và hiệu quả, cùng với học chuyển giao. Trong cấu hình này, mô hình được tiền huấn luyện bằng cách dự đoán từ tiếp theo dựa trên các từ trước đó. Mô hình được huấn luyện trên tập dữ liệu BookCorpus và đạt được kết quả tuyệt vời trong các tác vụ downstream như phân loại.
- GPT-2:
- Được truyền cảm hứng từ thành công của cách tiếp cận tiền huấn luyện đơn giản và có khả năng mở rộng, mô hình ban đầu và tập dữ liệu huấn luyện đã được nâng cấp để tạo ra GPT-2. Mô hình này có khả năng tạo ra các chuỗi văn bản dài, mạch lạc. Do lo ngại về khả năng lạm dụng, mô hình đã được phát hành theo từng giai đoạn, bắt đầu với các mô hình nhỏ hơn trước và mô hình đầy đủ sau đó.
- CTRL
- Các mô hình như GPT-2 có thể tiếp tục một chuỗi đầu vào (còn gọi là prompt). Tuy nhiên, người dùng có rất ít quyền kiểm soát phong cách của văn bản được tạo ra. Mô hình Conditional Transformer Language (CTRL) giải quyết vấn đề này bằng cách thêm các “token kiểm soát” vào đầu chuỗi. Những token này cho phép kiểm soát phong cách của văn bản được tạo ra, từ đó cho phép tạo ra văn bản đa dạng.
- GPT-3:
- Sau thành công của việc mở rộng GPT lên GPT-2, một phân tích sâu sắc về hành vi của các mô hình ngôn ngữ ở các quy mô khác nhau đã tiết lộ rằng có những quy luật đơn giản điều chỉnh mối quan hệ giữa tài nguyên tính toán, kích thước tập dữ liệu, kích thước mô hình và hiệu suất của mô hình ngôn ngữ. Được truyền cảm hứng từ những hiểu biết này, GPT-2 đã được mở rộng lên 100 lần để tạo ra GPT-3 với 175 tỷ tham số.
- Ngoài khả năng tạo ra các đoạn văn bản cực kỳ thực tế, mô hình này còn thể hiện khả năng học few-shot (few-shot learning): với một vài ví dụ của một tác vụ mới như dịch văn bản thành mã, mô hình có thể thực hiện nhiệm vụ trên các ví dụ mới. OpenAI chưa công khai mã nguồn của mô hình này nhưng cung cấp giao diện thông qua API OpenAI.
- GPT-Neo/GPT-J-6B:
- GPT-Neo và GPT-J-6B là các mô hình tương tự GPT được huấn luyện bởi EleutherAI, một nhóm các nhà nghiên cứu nhằm tái tạo và phát hành các mô hình quy mô GPT-3. Các mô hình hiện tại là các biến thể nhỏ hơn của mô hình 175 tỷ tham số đầy đủ, với 1.3, 2.7 và 6 tỷ tham số, và cạnh tranh với các mô hình GPT-3 nhỏ hơn do OpenAI cung cấp.
- Nhánh cuối cùng trong “cây tiến hóa” của transformer là các mô hình encoder-decoder. Hãy cùng xem qua.
The Encoder-Decoder Branch
- Mặc dù việc xây dựng các mô hình chỉ sử dụng bộ mã hóa (encoder) hoặc bộ giải mã (decoder) đã trở nên phổ biến, nhưng vẫn có một số biến thể encoder-decoder của kiến trúc Transformer có ứng dụng mới trong cả lĩnh vực NLU (Hiểu ngôn ngữ tự nhiên) và NLG (Sinh ngôn ngữ tự nhiên):
- T5:
- Mô hình T5 thống nhất cả NLU và NLG bằng cách chuyển đổi chúng thành các tác vụ text-to-text. Tất cả các tác vụ đều được định dạng dưới dạng tác vụ seq-to-seq, nơi kiến trúc encoder-decoder là tự nhiên. Ví dụ, đối với các bài toán phân loại văn bản, điều này có nghĩa là văn bản được sử dụng làm đầu vào của bộ mã hóa và bộ giải mã phải tạo ra nhãn dưới dạng văn bản thông thường thay vì một lớp. Kiến trúc T5 sử dụng kiến trúc Transformer gốc. Với tập dữ liệu lớn C4, mô hình được tiền huấn luyện bằng cách mô phỏng ngôn ngữ bị che cũng như chuẩn SuperGLUE để giải quyết tất cả các tác vụ text-to-text. Đây là mô hình lớn nhất (11 tỉ tham số) đạt state-of-the-art trên hiều benchmarks.
- BART:
- BART kết hợp các quy trình tiền huấn luyện của BERT và GPT trong kiến trúc encoder-decoder. Các chuỗi đầu vào trải qua một số phép biến đổi có thể, từ che dấu đơn giản đến hoán vị chuỗi, xóa token và xoay tài liệu. Các đầu vào đã được biến đổi này được truyền qua bộ encoder, và bộ decoder phải tái tạo lại văn bản gốc. Điều này làm cho mô hình linh hoạt hơn vì có thể sử dụng nó cho cả các nhiệm vụ xử lý ngôn ngữ tự nhiên (NLU) và tạo ngôn ngữ tự nhiên (NLG), đạt hiệu suất hàng đầu ở cả hai loại nhiệm vụ.
- M2M-100:
- Thông thường, một mô hình dịch được xây dựng cho một cặp ngôn ngữ và một chiều dịch nhất định. Tất nhiên, điều này không mở rộng được sang nhiều ngôn ngữ, và ngoài ra, có thể có kiến thức chung giữa các cặp ngôn ngữ có thể được tận dụng để dịch giữa các ngôn ngữ hiếm. M2M-100 là mô hình dịch đầu tiên có thể dịch giữa bất kỳ cặp ngôn ngữ nào trong số 100 ngôn ngữ. Điều này cho phép dịch chất lượng cao giữa các ngôn ngữ hiếm và ít được đại diện. Mô hình sử dụng tiền tố token (tương tự như token đặc biệt [CLS]) để chỉ định ngôn ngữ nguồn và ngôn ngữ đích.
- BigBird:
- Một hạn chế chính của các mô hình transformer là kích thước ngữ cảnh tối đa, do yêu cầu bộ nhớ bậc hai của cơ chế attention. BigBird giải quyết vấn đề này bằng cách sử dụng một dạng attention thưa, có khả năng mở rộng tuyến tính. Điều này cho phép mở rộng mạnh mẽ kích thước ngữ cảnh từ 512 token trong hầu hết các mô hình BERT lên 4.096 token trong BigBird. Điều này đặc biệt hữu ích trong các trường hợp cần bảo tồn các phụ thuộc dài hạn, chẳng hạn như tóm tắt văn bản.
- Các pretrained checkpoints của tất cả các mô hình được đề cập trong phần này có sẵn trên Hugging Face Hub và có thể được tinh chỉnh để phù hợp với trường hợp sử dụng của bạn với 🤗 Transformers, như đã mô tả trong blog trước.
3. Tổng Kết
- Transformers là một kiến trúc mạng nơ-ron mạnh mẽ, được thiết kế để xử lý dữ liệu tuần tự bằng cách tận dụng cơ chế Attention, giúp mô hình tập trung vào các phần quan trọng của đầu vào. Với cấu trúc dựa trên Encoder-Decoder, Transformers đã thay thế các mô hình truyền thống như RNN và LSTM trong nhiều ứng dụng, đặc biệt là xử lý ngôn ngữ tự nhiên (NLP) và thị giác máy tính (CV). Tính song song hóa cao và khả năng mở rộng vượt trội khiến Transformers trở thành nền tảng cho các mô hình AI tiên tiến như GPT và BERT.