Vector Semantics Và Embeddings
Kỹ thuật nhúng từ (Word Embedding) là một phương pháp biểu diễn từ ngữ dưới dạng các vector số trong không gian nhiều chiều. Mục tiêu chính của nhúng từ là biến đổi dữ liệu ngôn ngữ, vốn là dữ liệu dạng ký tự, thành dạng số hóa mà máy tính có thể hiểu và xử lý. Mỗi từ trong một tập ngữ liệu (corpus) sẽ được ánh xạ thành một vector có giá trị số, sao cho các từ có nghĩa gần nhau sẽ có vector gần nhau trong không gian vector.
Các kỹ thuật nhúng từ đã giúp giải quyết vấn đề về sự phân tán và tính không chính xác trong việc biểu diễn từ ngữ bằng cách cung cấp thông tin ngữ nghĩa trong mỗi vector. Các mô hình nhúng từ nổi tiếng bao gồm Word2Vec, GloVe, và FastText.
1. Giả thuyết phân phối.
1.1. Định nghĩa.
- Giả thuyết phân phối (Distributional Hypothesis) cho rằng “những từ xuất hiện trong cùng ngữ cảnh có xu hướng mang ý nghĩa tương tự nhau.” Nguyên lý này rất quan trọng trong Xử lý Ngôn ngữ Tự nhiên (NLP), vì nó là nền tảng cho các kỹ thuật biểu diễn từ như nhúng từ (word embeddings).
1.2. Những người đặt nền móng.
- Zellig Harris: Là người đề xuất Giả thuyết phân phối, Harris cho rằng ngữ cảnh sử dụng của từ quyết định phần lớn ý nghĩa của từ đó.
- John Rupert Firth: Ông nổi tiếng với câu nói “Bạn sẽ biết một từ qua công ty mà nó giữ,” ý chỉ rằng ý nghĩa của từ phụ thuộc vào các từ khác mà nó thường xuất hiện cùng.
- Martin Joos: Dù không nổi bật như Harris và Firth, ông cũng có những đóng góp trong việc phát triển lý thuyết này.
1.3. Ví dụ minh họa.
- Hãy lấy ví dụ về hai từ “chó” và “mèo”:
Con chó đang chạy trong vườn.
Con mèo đang chạy trong vườn.
Tôi đang cho chó ăn.
Tôi đang cho mèo ăn.
Trong các câu trên, từ “chó” và “mèo” thường xuất hiện trong các ngữ cảnh liên quan đến hành động chăm sóc, ăn uống, hay hoạt động của động vật cưng, mặc dù đây là hai từ hoàn toàn khác nhau về hình thức. Theo Giả thuyết phân phối, vì chúng thường xuất hiện trong ngữ cảnh tương tự, nên ý nghĩa của chúng cũng có xu hướng gần nhau.
2. Lexical Semantics.
Lexical Semantics (Ngữ nghĩa học từ vựng) là nghiên cứu về ý nghĩa của từ và mối quan hệ giữa các từ dựa trên ngữ nghĩa của chúng. Một số khái niệm quan trọng trong Lexical Semantics gồm:
Sự tương đồng về ngữ nghĩa (Word Similarity): Các từ có ý nghĩa hoặc xuất hiện trong ngữ cảnh tương tự. Ví dụ: Chó và mèo.
Từ đồng nghĩa (Synonyms): Các từ khác nhau nhưng có ý nghĩa tương tự nhau. Ví dụ: Hạnh phúc và sung sướng.
Từ trái nghĩa (Antonyms): Các từ có ý nghĩa đối lập nhau. Ví dụ: Ngắn và dài.
Hàm ý tích cực/tiêu cực (Positive/Negative Connotations): Từ có hàm ý tích cực hoặc tiêu cực tùy theo ngữ cảnh. Ví dụ: Hạnh phúc và đau khổ.
Trường ngữ nghĩa (Semantic Field): Các từ thuộc cùng một lĩnh vực hoặc chủ đề. Ví dụ: Marketing, kinh doanh, chi phí, lợi nhuận trong trường ngữ nghĩa kinh tế.
Lexical Semantics giúp hiểu rõ hơn cách từ ngữ tương tác và liên kết về mặt ý nghĩa, hỗ trợ các ứng dụng NLP như phân tích văn bản và dịch máy. Thao khảo mindmap tại: Lexical Semantics
Giới thiệu về SimLex-999
- SimLex-999 là một tập dữ liệu được thiết kế để đánh giá mức độ tương đồng ngữ nghĩa giữa các cặp từ. Tập dữ liệu này bao gồm các cặp từ được con người đánh giá dựa trên ngữ nghĩa, giúp kiểm tra và so sánh độ chính xác của các mô hình biểu diễn từ như Word2Vec, GloVe, FastText. Các bạn có thể tải bộ dữ liệu tại: Simlex-999
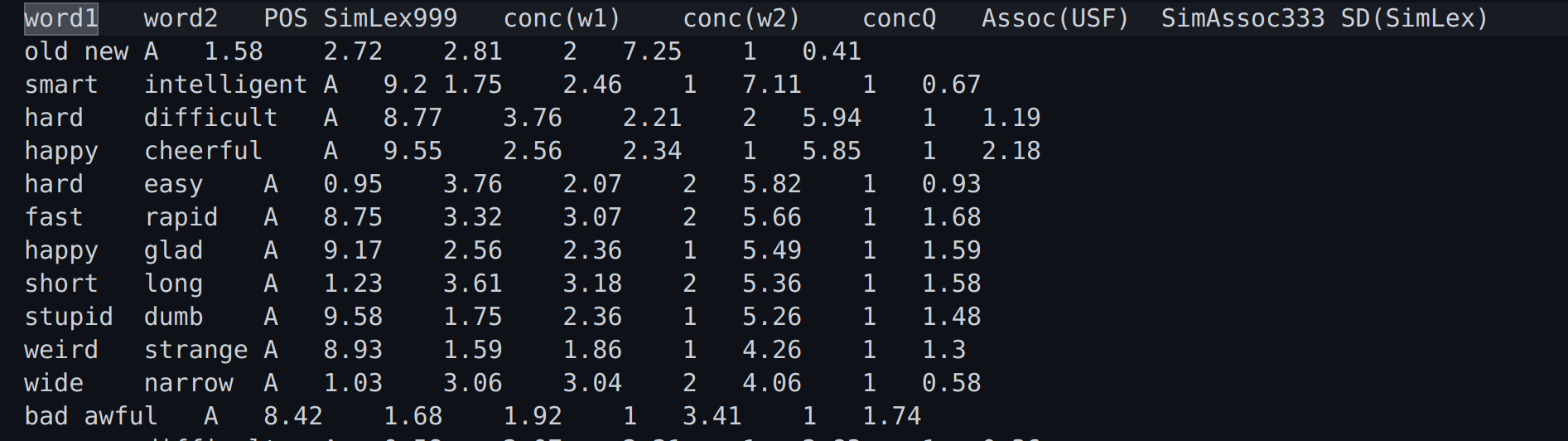
Các cột dữ liệu chính trong SimLex-999:
- word1 và word2:
- Đây là hai từ trong mỗi cặp từ mà SimLex-999 so sánh để đo lường sự tương đồng ngữ nghĩa.
- Ví dụ: “old” và “new”, “smart” và “intelligent”.
- POS (Part of Speech):
- Loại từ của các từ trong cặp, bao gồm:
- A: Adjective (tính từ).
- N: Noun (danh từ).
- V: Verb (động từ).
- Ví dụ: Trong hình ảnh, tất cả các cặp từ đều là tính từ (A).
- Loại từ của các từ trong cặp, bao gồm:
- SimLex999:
- Điểm tương đồng ngữ nghĩa giữa hai từ, trên thang điểm từ 0 đến 10, với giá trị cao hơn thể hiện mức độ tương đồng cao hơn.
- Ví dụ: “smart” và “intelligent” có điểm tương đồng là 9.2, trong khi “old” và “new” có điểm thấp hơn là 1.58.
- conc(w1) và conc(w2) (Word Concreteness):
- Độ cụ thể của từ đầu tiên (conc(w1)) và từ thứ hai (conc(w2)), đo trên thang điểm từ 1 đến 7. Từ càng cụ thể thì điểm càng cao.
- Ví dụ: “old” có độ cụ thể là 2, trong khi “new” là 7.25.
- concQ:
- Chất lượng của độ cụ thể (concreteness quality), cho biết mức độ đồng thuận giữa những người đánh giá về độ cụ thể của từ.
- Assoc(USF):
- USF Association đại diện cho độ mạnh của sự liên kết giữa hai từ dựa trên dữ liệu từ kho ngữ liệu USF Free Association. Số càng cao thì hai từ càng liên quan chặt chẽ với nhau.
- Ví dụ: “old” và “new” có chỉ số liên kết là 0.41.
- SimAssoc333:
- Sự tương đồng giữa các từ theo liên kết trong tập dữ liệu SimAssoc333, một tập hợp nhỏ hơn của SimLex-999.
- SD(SimLex):
- Standard Deviation (SD) cho điểm tương đồng SimLex999. Giá trị SD cao có nghĩa là có nhiều sự bất đồng giữa những người đánh giá về mức độ tương đồng giữa hai từ.
Ví dụ cụ thể:
- old và new:
- Tính từ (POS = A), có điểm tương đồng 1.58.
- “old” có độ cụ thể là 2, trong khi “new” là 7.25.
- Chỉ số liên kết USF là 0.41, cho thấy mức độ liên kết giữa hai từ không mạnh.
- smart và intelligent:
- Cũng là tính từ, có điểm tương đồng ngữ nghĩa rất cao là 9.2.
- Độ cụ thể của “smart” là 2.46, và “intelligent” là 7.11.
- Liên kết USF là 0.67, cho thấy sự liên kết khá mạnh giữa hai từ.
3. Vector ngữ nghĩa (Semantic vector).
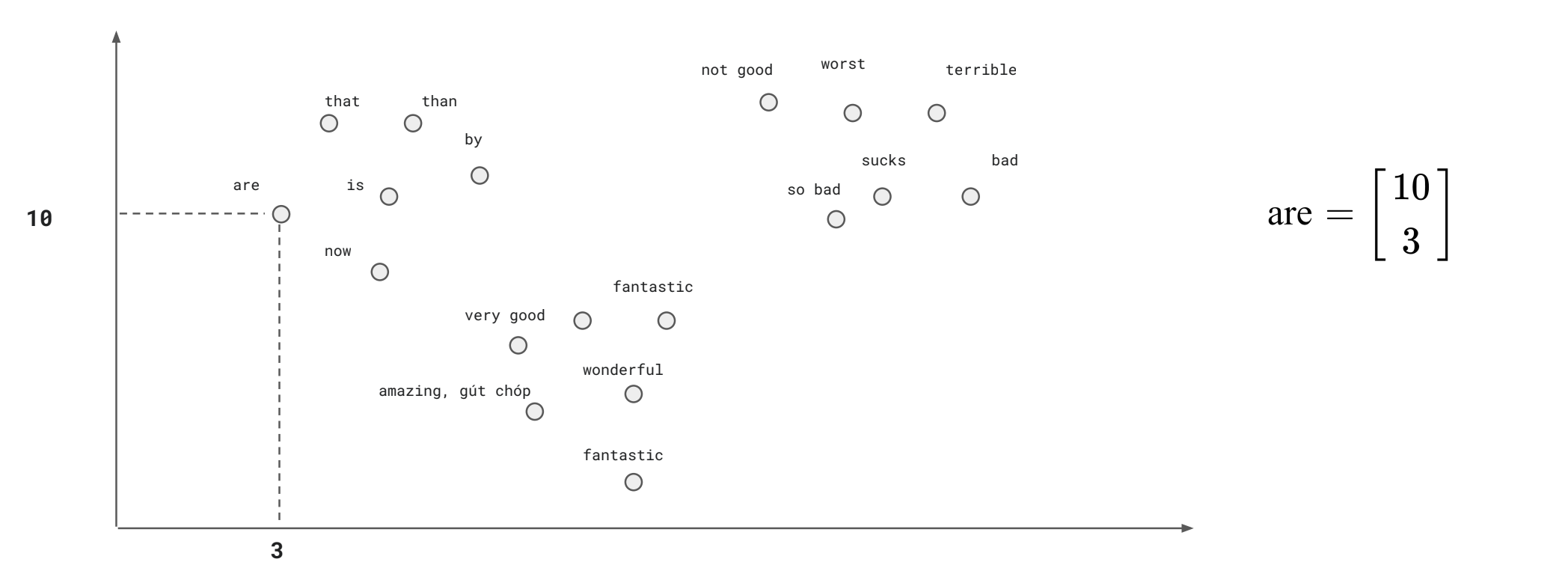
- Ngữ nghĩa của một từ được định nghĩa thông qua phân bố (distribution) của nó trong việc sử dụng ngôn ngữ.
- Hai từ có cùng phân bố (similar distribution - các từ xung quanh tương đồng nhau) sẽ có ngữ nghĩa giống nhau.
- Ý tưởng của vector ngữ nghĩa là biểu diễn một từ dưới dạng không gian ngữ nghĩ nhiều chiều (multidimensional semantic space), không gian này được xây dựng dựa trên mối quan hệ với các từ xung quanh.
- Hiểu một cách đơn giản thì ta sẽ biến các từ thành một vector chứa các số thực. Ví dụ như các từ sau biến thành vector gồm 200 số:
dog -> [0.1 , 1.34 , 4.21 ,…., 3.21]
cat -> [1.2 , 5.3 , 4.21 ,….., 6.7]
bus -> [6.42, 6.12 ,….., 1.12]
Điều ta muốn là ta phải biểu diễn sao cho các từ đồng ngữ nghĩa nằm gần nhau theo khoảng cách nào đó, ví dụ như khoảng cách Cosine hoặc Euclidean. Tức ta muốn các từ như dog và cat nằm gần nhau, tổng quát hơn là các từ về động vật phải nằm gần nhau. Kĩ thuật chuyển một từ (hay thực tế thì người ta coi từ như một token) sang dạng vector số gọi là Word Embeddings.
Và để trực quan hóa dữ liệu thì ta không thể vẽ 200 điểm này được mà ta sẽ cần phải sử dụng các thuật toán như PCA, t-SNE để giảm từ 200 xuống còn 3 dữ liệu. Các bạn có thể xem một video rất hay về việc minh họa dữ liệu tại đây: A.I. Experiments: Visualizing High-Dimensional Space
Có thể khám phá các điều thú vị khi trực quan hóa dữ liệu tại: Embedding Projector
Các loại Embeddings.
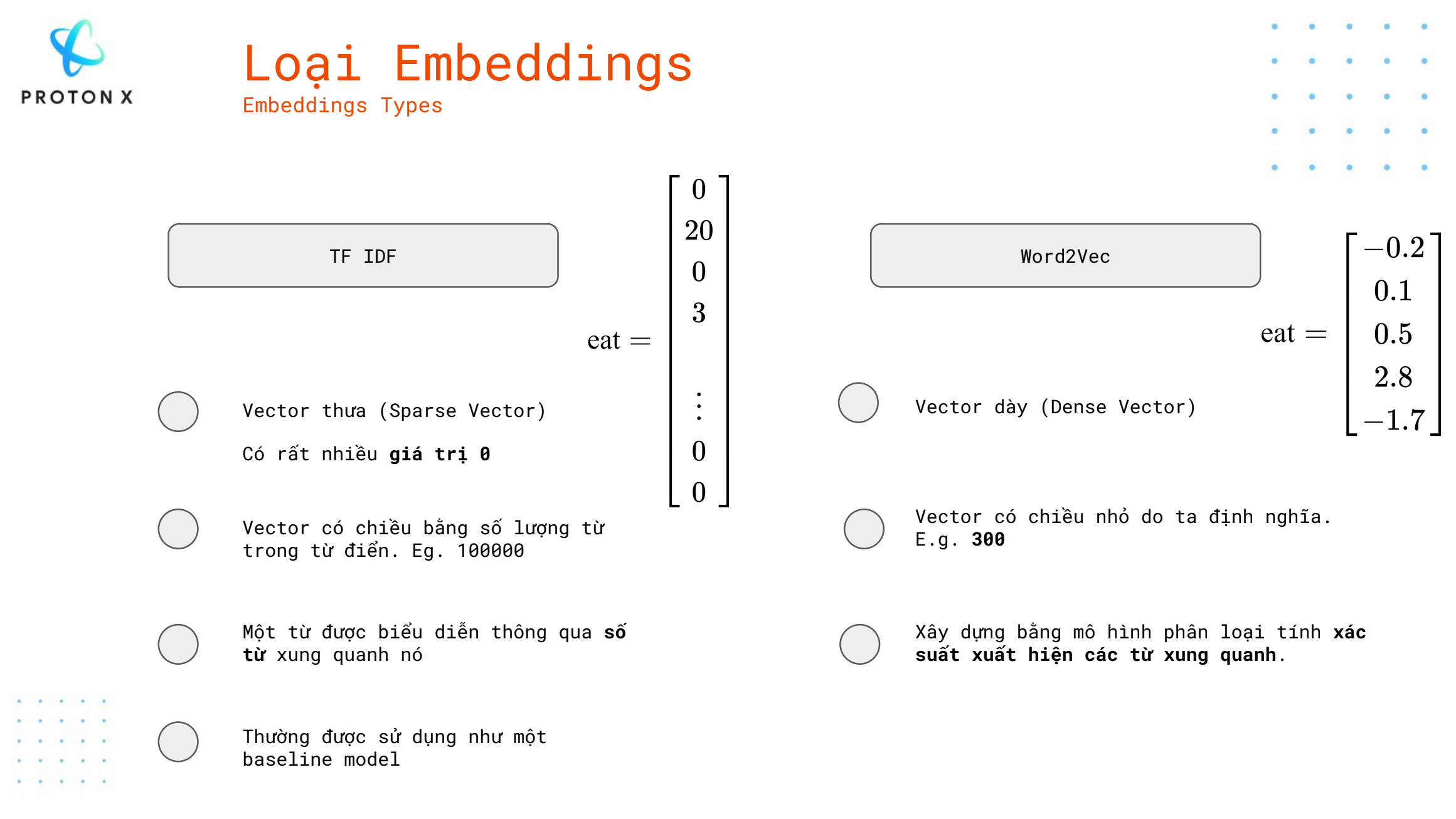
1. TF-IDF (Term Frequency-Inverse Document Frequency)
- Biểu diễn dưới dạng vector thưa (Sparse Vector): TF-IDF tạo ra các vector thưa, tức là các vector chứa rất nhiều giá trị bằng 0, bởi vì chỉ một số từ xuất hiện trong văn bản. Các từ không xuất hiện sẽ có giá trị 0.
- Có rất nhiều giá trị 0: Vector TF-IDF chứa nhiều giá trị 0, chỉ có một số vị trí có giá trị khác 0, biểu thị tần suất và mức độ quan trọng của từ trong văn bản.
- Vector có chiều bằng số lượng từ trong từ điển: TF-IDF xây dựng các vector có chiều dựa trên toàn bộ số lượng từ trong từ điển (ví dụ: 100,000 từ), dẫn đến các vector rất dài nhưng có nhiều giá trị 0.
- Thường được sử dụng như baseline model: TF-IDF là một phương pháp đơn giản và truyền thống, thường được sử dụng như một mô hình cơ bản (baseline) trong các bài toán NLP để so sánh với các mô hình phức tạp hơn.
2. Word2Vec
- Biểu diễn dưới dạng vector dày (Dense Vector): Word2Vec tạo ra các vector dày, tức là các vector chứa các giá trị khác nhau (không phải 0), thể hiện mối quan hệ ngữ nghĩa giữa các từ.
- Vector có chiều nhỏ do ta định nghĩa: Vector của Word2Vec thường có chiều nhỏ, thường là các giá trị do người dùng định nghĩa (ví dụ: 300 chiều), không phụ thuộc vào số lượng từ trong từ điển.
- Xây dựng bằng mô hình phân loại xác suất xuất hiện từ xung quanh: Word2Vec học cách biểu diễn từ bằng cách tính toán xác suất từ xuất hiện trong ngữ cảnh của các từ khác, tức là nó dựa vào mối quan hệ giữa từ và ngữ cảnh để học.
- Một từ được biểu diễn thông qua số từ xung quanh nó: Word2Vec sử dụng các kỹ thuật như CBOW hoặc Skip-gram để học từ ngữ cảnh, giúp tạo ra các vector phản ánh ý nghĩa ngữ nghĩa của từ.
Term-Document Matrix
Term-Document Matrix (TDM) là một cách biểu diễn văn bản dưới dạng ma trận trong các bài toán xử lý ngôn ngữ tự nhiên (NLP). Ma trận này thể hiện mối quan hệ giữa các từ (thuật ngữ) và các tài liệu trong tập dữ liệu.
Ví dụ cụ thể:
Giả sử chúng ta có 3 tài liệu sau:
- Document 1: “I love machine learning”
- Document 2: “machine learning is fun”
- Document 3: “I love learning and machine learning”
Bước 1: Tạo từ điển (Vocabulary)
Chúng ta liệt kê tất cả các từ xuất hiện trong 3 tài liệu trên để tạo thành từ điển:
- Từ điển: [“I”, “love”, “machine”, “learning”, “is”, “fun”, “and”]
Bước 2: Tạo Term-Document Matrix
Tiếp theo, chúng ta xây dựng Term-Document Matrix bằng cách đếm số lần mỗi từ xuất hiện trong từng tài liệu.
| Term/Document | Document 1 | Document 2 | Document 3 |
|---|---|---|---|
| I | 1 | 0 | 1 |
| love | 1 | 0 | 1 |
| machine | 1 | 1 | 1 |
| learning | 1 | 1 | 2 |
| is | 0 | 1 | 0 |
| fun | 0 | 1 | 0 |
| and | 0 | 0 | 1 |
Bước 3: Giải thích Term-Document Matrix
- Hàng: Đại diện cho từng từ trong từ điển (“I”, “love”, “machine”, “learning”, “is”, “fun”, “and”).
- Cột: Đại diện cho các tài liệu (Document 1, Document 2, Document 3).
- Giá trị: Mỗi ô biểu thị số lần từ đó xuất hiện trong tài liệu tương ứng. Ví dụ, từ “learning” xuất hiện 1 lần trong Document 1, 1 lần trong Document 2, và 2 lần trong Document 3.
Ứng dụng:
- Phân loại văn bản: TDM cung cấp các đặc trưng (features) để huấn luyện mô hình học máy.
- Trích xuất từ khóa: Giúp xác định từ nào xuất hiện nhiều nhất và quan trọng trong tập văn bản.
- Tìm kiếm thông tin: TDM được sử dụng để tìm kiếm và tính toán mức độ tương đồng giữa các tài liệu.
- Term-document matrix được định nghĩa từ task information retrieval (IR), hai văn bản tương đồng nhau sẽ có nhiều từ tương đồng nhau. Information retrieval (IR) là task tìm văn bản d từ D văn bản phù hợp nhất với truy xuất (query) q.
Biến thể: TF-IDF Matrix
Thay vì sử dụng tần suất từ xuất hiện đơn giản, bạn có thể sử dụng TF-IDF (Term Frequency-Inverse Document Frequency) để trọng số hóa các từ. Điều này giúp giảm trọng số của các từ phổ biến nhưng ít mang tính thông tin (như “the”, “is”), và tăng trọng số của các từ đặc trưng cho tài liệu.
Ví dụ, từ “machine” xuất hiện trong cả ba tài liệu, sẽ có trọng số TF-IDF thấp hơn từ “fun” (chỉ xuất hiện trong Document 2), vì “fun” đặc trưng hơn cho Document 2.
Word-vector
- Có thể xây dựng word vector với quy tắc lấy các hàng của từ làm vector embedding, với ví dụ ở bảng trên, ta có:
I –> [1,0,1]
love –> [1,0,1]
machine -> [1,1,1]
Word-word Matrix / Term-term Matrix / Term-context Matrix
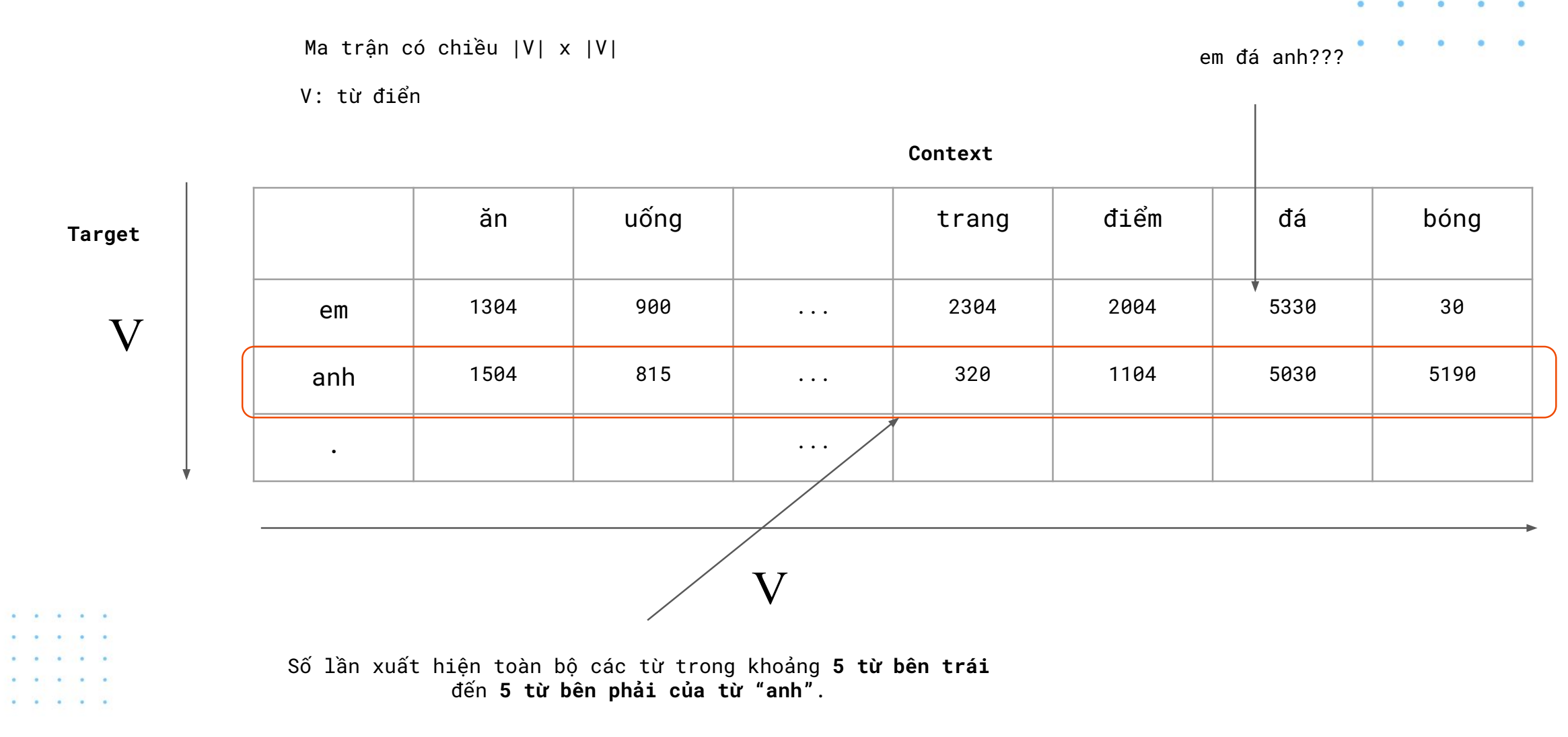
Word-word Matrix (còn gọi là Term-term Matrix hoặc Term-context Matrix) là một ma trận biểu diễn mối quan hệ giữa các từ trong một tập văn bản. Ma trận này giúp mô tả tần suất xuất hiện của một từ (từ mục tiêu) trong ngữ cảnh của các từ khác (từ ngữ cảnh). Nó là một công cụ hữu ích trong xử lý ngôn ngữ tự nhiên (NLP), giúp máy tính hiểu mối liên kết ngữ nghĩa giữa các từ.
Cấu trúc của ma trận:
V: từ điển: Tập hợp từ vựng, hay từ điển, gồm tất cả các từ xuất hiện trong tập văn bản. Mỗi từ trong từ điển tương ứng với một hàng và một cột trong ma trận.
Chiều của ma trận: Ma trận có kích thước V x V , với V là số lượng từ trong từ điển. Như vậy, mỗi hàng đại diện cho từ “target” (từ mục tiêu), và mỗi cột đại diện cho từ “context” (từ ngữ cảnh).
Ý nghĩa của giá trị trong ma trận:
- Mỗi ô trong ma trận đại diện cho số lần từ mục tiêu xuất hiện trong ngữ cảnh của từ ngữ cảnh. Ví dụ, giá trị trong ô tại hàng “anh” và cột “ăn” cho biết số lần từ “anh” xuất hiện gần từ “ăn”.
Ví dụ cụ thể:
- Trong ví dụ ở slide, hàng “anh” biểu thị các số liệu về từ “anh” xuất hiện trong các ngữ cảnh khác nhau:
- “anh” xuất hiện 1504 lần trong ngữ cảnh của từ “ăn”.
- “anh” xuất hiện 815 lần trong ngữ cảnh của từ “uống”.
- “anh” xuất hiện 5030 lần trong ngữ cảnh của từ “đá”.
- “anh” xuất hiện 5190 lần trong ngữ cảnh của từ “bóng”.
Khoảng ngữ cảnh:
- Các giá trị trong ma trận thường được tính trong một khoảng ngữ cảnh xác định, ví dụ như các từ xuất hiện trong phạm vi 5 từ bên trái và 5 từ bên phải của từ mục tiêu.
Ứng dụng của Word-word Matrix:
- Phân tích ngữ nghĩa: Word-word Matrix giúp phát hiện các từ có liên quan ngữ nghĩa với nhau thông qua tần suất xuất hiện trong cùng một ngữ cảnh.
- Mô hình ngôn ngữ: Ma trận này là nền tảng cho các mô hình như Word2Vec hay GloVe, giúp biểu diễn từ dưới dạng vector có ngữ nghĩa.
- Phát hiện quan hệ từ vựng: Nó giúp nhận biết các từ liên quan và xuất hiện gần nhau thường xuyên trong các văn bản.
4. Word2Vec.
- Word2Vec là một mô hình đơn giản và nổi tiếng giúp tạo ra các biểu diễn embedding của từ trong một không gian có số chiều thấp hơn nhiều lần so với số từ trong từ điển. Ý tưởng của word2vec đã được sử dụng trong nhiều bài toán với dữ liệu khác xa với dữ liệu ngôn ngữ.
Ý tưởng cơ bản của word2vec có thể được gói gọn trong các ý sau:
- Hai từ xuất hiện trong những văn cảnh giống nhau thường có ý nghĩa gần với nhau.
- Ta có thể đoán được một từ nếu biết các từ xung quanh nó trong câu. Ví dụ, với câu “Hà Nội là … của Việt Nam” thì từ trong dấu ba chấm khả năng cao là “thủ đô”. Với câu hoàn chỉnh “Hà Nội là thủ đô của Việt Nam”, mô hình word2vec sẽ xây dựng ra embeding của các từ sao cho xác suất để từ trong dấu ba chấm là “thủ đô” là cao nhất.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Hà | 0.031827 | -0.015052 | 0.036400 | -0.025224 | -0.026220 | -0.046286 | 0.019774 | -0.008172 | 0.006869 | 0.012888 |
| Nội | -0.050856 | 0.091691 | 0.035700 | 0.079347 | -0.067342 | -0.055625 | -0.062175 | -0.068485 | -0.007364 | 0.091895 |
| là | 0.030441 | -0.050559 | 0.038910 | -0.055022 | -0.098898 | -0.072563 | -0.056924 | -0.085691 | 0.045195 | -0.011041 |
| của | 0.080730 | 0.007994 | 0.032952 | 0.025223 | -0.025180 | 0.038352 | 0.014387 | 0.048172 | -0.084220 | 0.020160 |
| Việt | -0.030587 | 0.031163 | -0.028113 | -0.010189 | -0.071232 | -0.074625 | -0.062832 | 0.069700 | 0.066684 | 0.023029 |
Word2Vec là một embedding tĩnh (static embedding), một từ được biểu diễn dưới dạng một vector cố định (fixed embedding). Những Embedding tiên tiến hiện nay như BERT hoặc ELMO biểu diễn từ dưới dạng vector ngữ cảnh động (dynamic contextual embedding), tức là một từ sẽ có biểu diễn khác nhau trong những ngữ cảnh khác nhau.
Trong ví dụ trên đây, từ “thủ đô” đang được xét và được gọi là target word hay từ đích. Những từ xung quanh nó được gọi là context words hay từ ngữ cảnh. Với mỗi từ đích trong một câu của cơ sở dữ liệu, các từ ngữ cảnh được định nghĩa là các từ trong cùng câu có vị trí cách từ đích một khoảng không quá $\frac{C}{2}$ với $C$ là một số tự nhiên dương. Như vậy, với mỗi từ đích, ta sẽ có một bộ không quá $C$ từ ngữ cảnh.
Xét ví dụ sau đây với câu tiếng Anh: “The quick brown fox jump over the lazy dog” với $C = 4$.
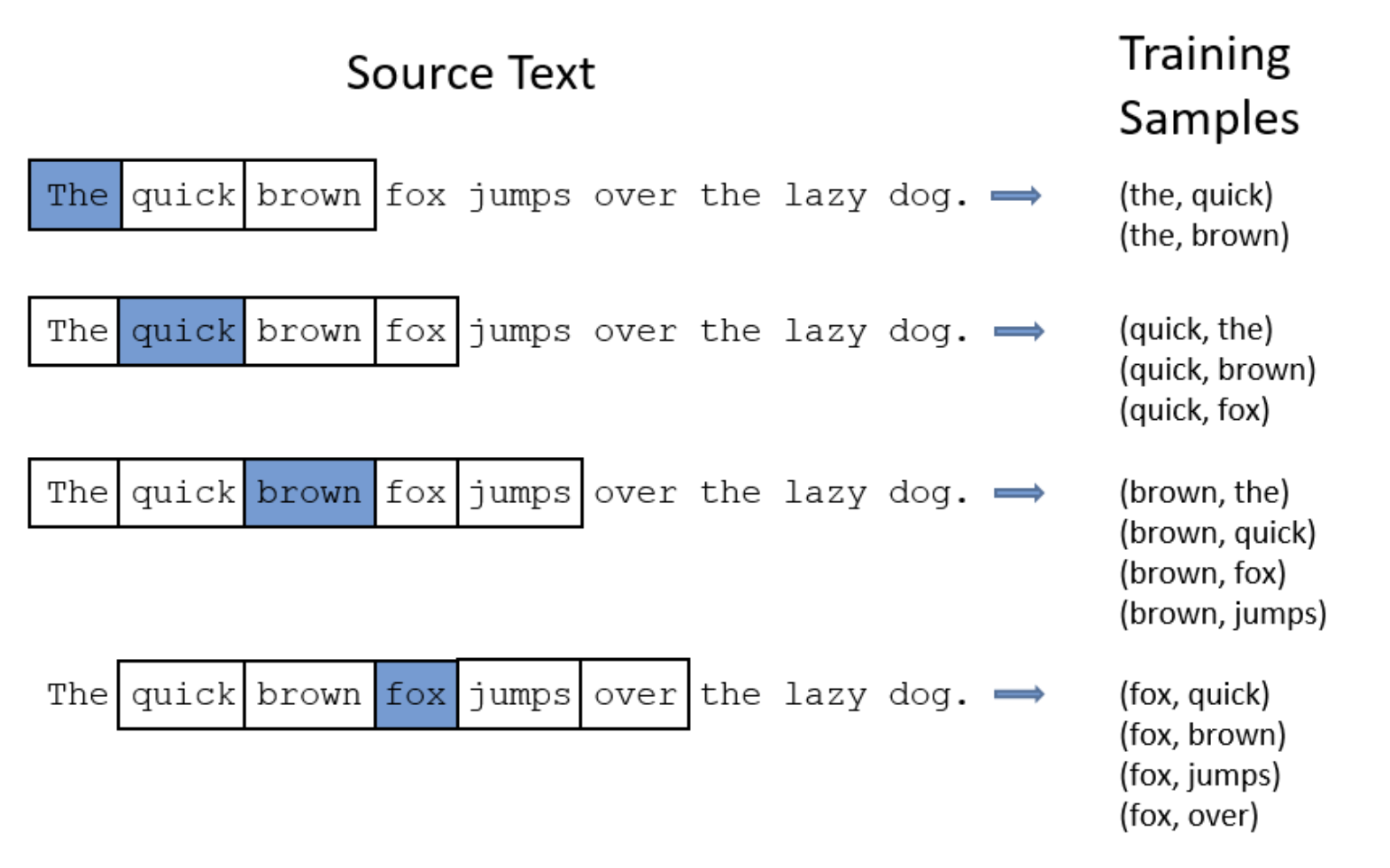
Khi “the” là từ đích, ta có cặp dữ liệu huấn luyện là (the, quick) và (the, brown). Khi “brown” là từ đích, ta có cặp dữ liệu huấn luyện là (brown, the), (brown, quick), (brown, fox) và (brown, jumps).
Word2vec định nghĩa hai embedding vector cùng chiều cho mỗi từ $w$ trong từ điển. Khi nó là một từ đích, embedding vector của nó là $u$; khi nó là một từ ngữ cảnh, embedding của nó là $v$. Sở dĩ ta cần hai embedding khác nhau vì ý nghĩa của từ đó khi nó là từ đích và từ ngữ cảnh là khác nhau. Tương ứng với đó, ta có hai ma trận embedding $U$ và $V$ cho các từ đích và các từ ngữ cảnh.
Có hai cách khác nhau xây dựng mô hình Word2Vec:
Skip-gram: Dự đoán những từ ngữ cảnh nếu biết trước từ đích.
CBOW (Continuous Bag of Words): Dựa vào những từ ngữ cảnh để dự đoán từ đích.
Mỗi cách có những ưu nhược điểm khác nhau và áp dụng với những loại dữ liệu khác nhau.
CBOW (Continuous Bag of Words).
- CBOW đi tìm xác suất xảy ra từ đích khi biết các từ ngữ cảnh xung quanh. Ta cần mô hình hóa dữ liệu sao cho xác suất sau đây đạt giá trị lớn:
- Vì có nhiều từ ngữ cảnh trong điều kiện, chúng thường được đơn giản hóa bằng cách lấy một từ “trung bình” làm đại diện.
Với $\bar{w}_{c_t}$ là trung bình cộng của các từ trong ngữ cảnh của từ đích $w_t$ .Embedding của từ trung bình này là trung bình của embedding các từ ngữ cảnh.
Nếu bạn vẫn chưa hiểu ý tưởng của CBOW thì hãy mình sẽ nói một cách đơn giản. Hãy nhìn vào hình vẽ trên, ta sẽ tạo ra tập data như ở dưới với $X$ là các từ ngữ cảnh và $y$ là các từ mục tiêu, hay bạn có thể coi đây là một bài toán machine learning thuần túy, có các đặc trưng của $X$ và nhãn $y$.
| X | y |
|---|---|
| (quick, brown) | the |
| (the, brown, fox) | quick |
| (the, quick, fox,jumps) | brown |
| (quick, brown, jumps, over) | fox |
| (brown, fox,over,the) | jumps |
| (fox, jumps,the,lazy) | over |
| (jumps, over, lazy,dog) | the |
| (over, the, dog) | lazy |
| (the, lazy) | dog |
- Đầu tiên, ta sẽ tạo ra tập từ điển của câu:
The quick brown fox jumps over the lazy dog.
- Từ điển của câu trên là:
The, quick, brown, fox, jumps, over, lazy, dog
- Để ý là chỉ có 8 từ vì từ the đã bị lặp lại vì từ điển chỉ lưu các từ khác nhau. Dưới đây là luồng hoạt động của CBOW khi xử lý cặp data đầu tiên:
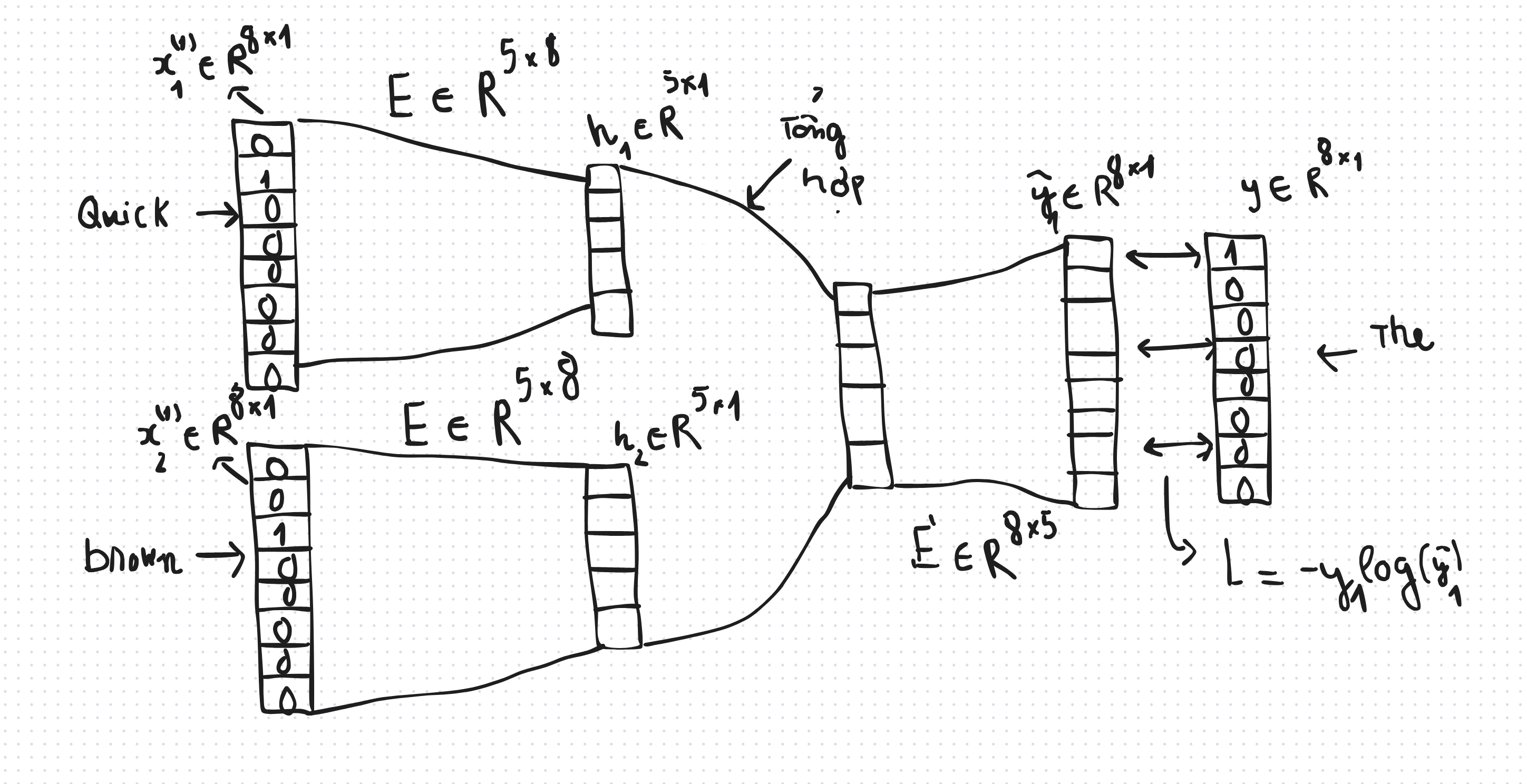
- Ban đầu từ “quick” và từ “brown” sẽ được chuyển thành dạng one-hot vector, tức là vector đó sẽ có giá trị bằng 1 tại vị trí của từ đó trong từ điển, các vị trí khác thì bằng 0:
- Tiếp theo, giả sử ta muốn mỗi một từ sẽ được embedding thành vector có kích thước là $D$, trong hình vẽ thì tôi chọn $D = 5$. Ta sẽ tạo ra một ma trận $E$ (embedding) để nén từ vector thưa one-hot thành dạng vector đầy đủ với số chiều là $5$, ta gọi vector đầy đủ ý là $h$:
- Bạn thấy phần này giống mạng no-ron nhân tạo không ? Chính xác là nó nhưng mà mô hình CBOW phiên bản đầu tiên của tác giả không có hàm kích hoạt, tôi sẽ thảo luận vấn đề này sau. Sau khi có hai vector $h_1$ và $h_2$, ta sẽ tiến hành tổng hợp hai vector này thành một vector, thường ta sẽ chỉ đơn giản là dùng một hàm lấy trung bình cộng của hai vector, ta gọi vector tổng hợp là $u$:
- Hay tổng quát hơn, ta có thể thử nhiều hàm khác nhau, và biểu diễn $u$ dưới dạng là một hàm phụ thuộc vào $h_1$ và $h_2$:
- Tạm thời ta sẽ coi hàm $F$ là hàm lấy trung bình cộng của các vector đầu vào cho đơn giản. Tiếp theo ta sẽ “phóng to” vector $u$ về dạng vector có cùng kích thước với vector ban đầu bằng cách lại lấy vector $u$ nhân với một ma trận $E$’, ta sẽ gọi kết quả của phép nhân này là $\hat{y}$:
- Đây chính là vector dự đoán, và ta muốn vector này gần với vector one-hot của từ mục tiêu,. trong trường hợp này là từ “the”, nên ta sẽ coi đây là bài toán phân loại đa lớp thông thường. Ta sẽ chuyển $\hat{y}$ sang dạng xác suất bằng cách áp dụng hàm Softmax:
- Sau đó, ta tính hàm $L$ (loss function) trên cặp data đầu tiên:
- Vậy là ta đã làm xong tất cả các bước với cặp data đầu tiên. Ta cũng làm tương tự với các cặp data còn lại, kết quả cuối cùng ta sẽ có một hàm cost function như sau (lưu ý là làm các cặp data còn lại trên cùng một mô hình như trên, tức là ta vẫn dùng ma trận $E$ và ma trận $E$’):
- Sau đó ta sẽ huấn luyện mô hình bằng các thuật toán đơn giản như GD, SGD, Adam… Sau khi huấn luyện xong thì ta sẽ thu được ma trận $E$ đã được học từ những từ ngữ cảnh và từ mục tiêu. Lúc này, ta có thể chuyển một từ sang dạng vector bằng cách thực hiện phép nhân giữa vector one-hot của từ đó với ma trận $E$:
Tác giả của phương pháp CBOW là Tomas Mikolov , các bạn có thể đọc paper gốc tại: Efficient Estimation of Word Representations in Vector Space. Tomas Mikolov không dùng hàm kích hoạt nào trong kiến trúc của CBOW vì ông phải làm việc trên tập data rất lớn và việc thêm hàm kích họat có thể làm chậm quá trình huấn luyện, một lý do nữa là ông đã thử nghiệm trên nhiều kiến trúc khác nhau và thấy việc không có hàm kích hoạt vẫn mang đến kết quả tốt. Các bạn hoàn toàn có thể thêm nhiều tầng và các hàm kích hoạt bên trong CBOW.
Giờ hãy thử lập trình thuật toán CBOW bằng thư viện Pytorch. Đầu tiên ta khởi tạo những thư viện cần thiết:
1
2
3
4
5
6
7
8
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
torch.manual_seed(1)
- Tiếp theo ta khởi tạo kích thước cửa sổ ngữ cảnh và số chiều emebdding:
1
2
context_size = 2 # {w_i-2 ... w_i ... w_i+2}
embedding_dim = 10
- Ta sẽ khởi tạo biến
raw_textlà văn bản đầu vào và một hàmmake_content_vectorđể chuyển các từ sang dạng idx:
1
2
3
4
5
6
raw_text = """We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules
called a program. People create programs to direct processes. In effect,
we conjure the spirits of the computer with our spells.""".split()
- Ta khởi tạo biến
vocabcó tác dụng lưu các từ khác nhau trong văn bản gốc,vocab_sizelà độ dài của từ điển,word_to_idxlà một dict trong python lưu các cặp word - idx,idx_to_wordlà lưu các cặp idx - word.
1
2
3
4
5
vocab = set(raw_text)
vocab_size = len(vocab)
word_to_idx = {word: i for i, word in enumerate(vocab)}
idx_to_word = {i: word for i, word in enumerate(vocab)}
- Ta khởi tạo biến
datađể lưu các cặp (từ ngữ cảnh, từ mục tiêu):
1
2
3
4
5
6
7
data = []
for i in range(2, len(raw_text) - 2):
context = [raw_text[i-2], raw_text[i-1],
raw_text[i+1], raw_text[i+2]]
target = raw_text[i]
data.append((context, target))
- Tiếp theo, ta khởi tạo class
CBOW:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.proj = nn.Linear(embedding_dim, 128)
self.output = nn.Linear(128, vocab_size)
def forward(self, inputs):
embeds = sum(self.embeddings(inputs)).view(1, -1)
out = F.relu(self.proj(embeds))
out = self.output(out)
nll_prob = F.log_softmax(out, dim=-1)
return nll_prob
def word2vec(self, word, word_to_idx):
word_idx = word_to_idx[word] # Lấy chỉ số của từ trong từ điển
word_embedding = self.embeddings(torch.tensor([word_idx])) # Lấy vector nhúng từ embeddings
return word_embedding.detach().numpy() # Trả về vector nhúng dưới dạng numpy array
- Ta sẽ dùng thuật toán Adamax để train:
1
2
3
4
5
model = CBOW(vocab_size, embedding_dim)
optimizer = optim.Adamax(model.parameters(), lr=0.001)
losses = []
loss_function = nn.NLLLoss()
- Ta sẽ chạy $200$ epochs và train mô hình CBOW:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
for epoch in range(200):
total_loss = 0
for context, target in data:
# print("Context: ", context)
context_vector = make_context_vector(context, word_to_idx)
# print("content_vector: ", context_vector)
# print("Target: ", target)
# Remember PyTorch accumulates gradients; zero them out
model.zero_grad()
nll_prob = model(context_vector)
loss = loss_function(nll_prob, Variable(torch.tensor([word_to_idx[target]])))
#print(Variable(torch.tensor([word_to_idx[target]])))
#print("loss: ",loss)
# backpropagation
loss.backward()
# update the parameters
optimizer.step()
total_loss += loss.item()
losses.append(total_loss)
print(losses[-1])
0.002134389060643116
- Giờ tôi sẽ giải thích kĩ hơn về class CBOW. Mô hình của chúng ta sẽ hơi khác kiến trúc mà tôi vừa trình bày một chút. Đầu vào của CBOW sẽ là một vector gồm 4 số, tương ứng với các idx của các từ ngữ cảnh. Ví dụ như từ ngữ cảnh và từ mục tiêu của chúng ta là:
[We, are, to, study] ——-> about
- Thì ta sẽ chuyển các từ ngữ cảnh ban đầu sang dạng idx:
[We, are, to, study] —-> [19,21,29,27]
- Đây chính là đầu vào của class CBOW. Module nn.Embedding(vocab_size, embedding_dim) có tác dụng là tạo ra một ma trận có kích thước là vocab_size x embedding_dim, cụ thể trong đoạn code thì sẽ tạo ra ma trận có kích thước là 49 * 10.
- Các số [19,21,29,27] sẽ chuyển thành dạng one-hot vector. Tức là 19 sẽ thành [0,0,…..,1,0,0,..,0],… Khi đó thì vector [19,21,29,27] sẽ chuyển thành ma trận có kích thước là 4 x 49, mỗi một hàng là vector ont-hot đại diện cho số ý. Và ta sẽ lấy ma trận one-hot này nhân với cả ma trận được tạo ra từ nn.Embedding(vocab_size, embedding_dim), kết quả là một ma trận có kích thước là 4*10
- Điều này vẫn giống như lý thuyết tôi đã trình bày, chỉ khác là giờ ta sắp xếp 4 vector thành một ma trận. Tiếp tục, ta sẽ tính tổng trên các cột của ma trận này, khi đó thì ma trận sẽ biến thành vecor có kích thước là 1 * 10. Đây chính là bước tổng hợp trên hình ảnh, thay vì dùng tổng trung bình thì code trên chỉ lấy tổng.
- Bước tiếp theo thì ta sẽ không phóng thành vector đầu ra luôn mà ta sẽ qua một tầng nữa. Cụ thể, ta sẽ đưa qua một tầng Linear có kích thước là 10*128, kết quả sẽ thành 1 * 128. Ta đưa vector này qua hàm kích hoạt Relu xong lại đưa qua tầng Linear có kích thước là 128 * 49 để trở lại kích thước đúng như đầu ra. Sau đó dùng softmax tương tự như tôi đã trình bày.
- Giờ hãy thử dùng hàm
word2veccủa mô hình đã được train:
1
2
3
4
word = 'study'
vector = model.word2vec(word, word_to_idx)
print(f"Vector embedding của từ '{word}':\n", vector)
Vector embedding của từ ‘study’:[[-0.00366543 1.8923402 -0.14652911 -2.1347413 -0.66336215 0.77671105 -0.78789824 1.9692897 -0.47480232 1.246002 ]]
- Note: Embeddings có thể được train từ nhiều bài toán khác nhau. Chỉ cần đặt lớp Emebdding ở trước mô hình học sâu bất kỳ một bài toán nào, ta đều có thể thu được embedding của các từ trong từ điển. Vector của từng từ này sẽ được học thông qua loss của bài toán tương ứng. Tuy nhiên đến thời điểm hiện tại thì các mô hình pretrained học mối quan hệ giữa các từ sử dụng Attention cho ra kết quả tốt nhất, điển hình là: Transfomer và Bert.
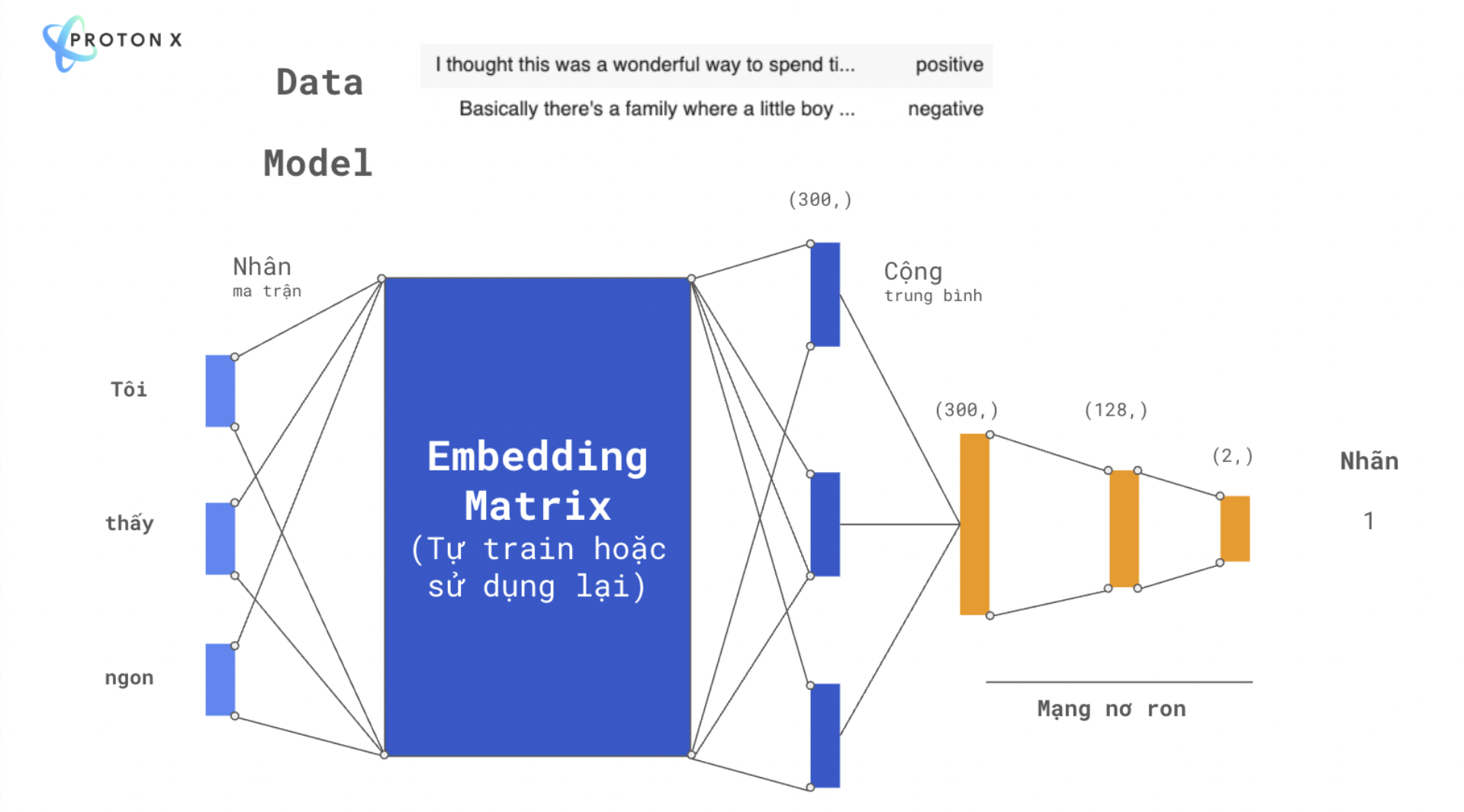
- Ảnh trên là một ví dụ minh họa sử dụng ma trận Embedding để giải quyết bài toán phân loại cảm xúc tiêu cực hay tích cực. Chúng ta có thể khởi tạo ma trận Emebdding ngẫu nhiên từ đầu hoặc sử dụng lại ma trận Embedidng đã train từ tác vụ nào đó.
Code BT ở đây
- Vấn đề của CBOW là hàm Softmax thực hiện rất chậm khi từ điền lớn lên. Giờ chúng ta sẽ đến với mô hình Skip Gram có thể giải quyết vấn đề đó.
Skip Gram
Coming Soon….